 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Reinforcement Learning Accelerated MCMC on Multiscale Inversion Problem
Nov 17, 2020
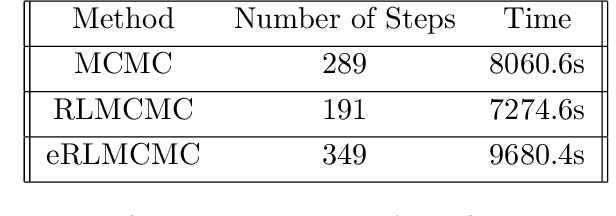
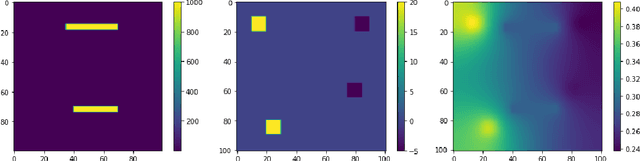

In this work, we propose a multi-agent actor-critic reinforcement learning (RL) algorithm to accelerate the multi-level Monte Carlo Markov Chain (MCMC) sampling algorithms. The policies (actors) of the agents are used to generate the proposal in the MCMC steps; and the critic, which is centralized, is in charge of estimating the long term reward. We verify our proposed algorithm by solving an inverse problem with multiple scales. There are several difficulties in the implementation of this problem by using traditional MCMC sampling. Firstly, the computation of the posterior distribution involves evaluating the forward solver, which is very time consuming for a problem with heterogeneous. We hence propose to use the multi-level algorithm. More precisely, we use the generalized multiscale finite element method (GMsFEM) as the forward solver in evaluating a posterior distribution in the multi-level rejection procedure. Secondly, it is hard to find a function which can generate samplings which are meaningful. To solve this issue, we learn an RL policy as the proposal generator. Our experiments show that the proposed method significantly improves the sampling process