 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Neural Network Training: A Brief Review
Dec 26, 2023
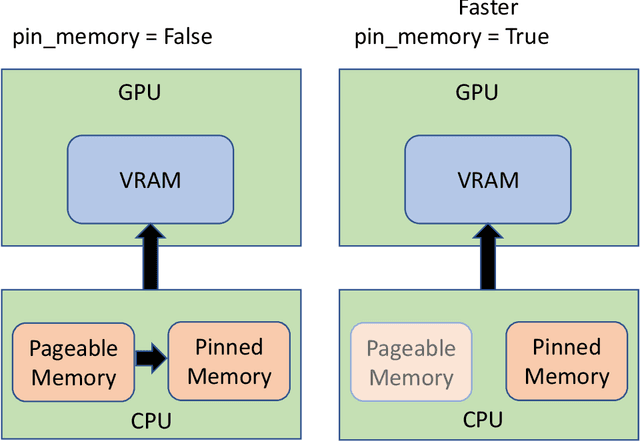

The process of training a deep neural network is characterized by significant time requirements and associated costs. Although researchers have made considerable progress in this area, further work is still required due to resource constraints. This study examines innovative approaches to expedite the training process of deep neural networks (DNN), with specific emphasis on three state-of-the-art models such as ResNet50, Vision Transformer (ViT), and EfficientNet. The research utilizes sophisticated methodologies, including Gradient Accumulation (GA), Automatic Mixed Precision (AMP), and Pin Memory (PM), in order to optimize performance and accelerate the training procedure. The study examines the effects of these methodologies on the DNN models discussed earlier, assessing their efficacy with regard to training rate and computational efficacy. The study showcases the efficacy of including GA as a strategic approach, resulting in a noteworthy decrease in the duration required for training. This enables the models to converge at a faster pace. The utilization of AMP enhances the speed of computations by taking advantage of the advantages offered by lower precision arithmetic while maintaining the correctness of the model. Furthermore, this study investigates the application of Pin Memory as a strategy to enhance the efficiency of data transmission between the central processing unit and the graphics processing unit, thereby offering a promising opportunity for enhancing overall performance. The experimental findings demonstrate that the combination of these sophisticated methodologies significantly accelerates the training of DNNs, offering vital insights for experts seeking to improve the effectiveness of deep learning processes.
Quantum Generative Adversarial Networks: Bridging Classical and Quantum Realms
Dec 26, 2023
In this pioneering research paper, we present a groundbreaking exploration into the synergistic fusion of classical and quantum computing paradigms within the realm of Generative Adversarial Networks (GANs). Our objective is to seamlessly integrate quantum computational elements into the conventional GAN architecture, thereby unlocking novel pathways for enhanced training processes. Drawing inspiration from the inherent capabilities of quantum bits (qubits), we delve into the incorporation of quantum data representation methodologies within the GAN framework. By capitalizing on the unique quantum features, we aim to accelerate the training process of GANs, offering a fresh perspective on the optimization of generative models. Our investigation deals with theoretical considerations and evaluates the potential quantum advantages that may manifest in terms of training efficiency and generative quality. We confront the challenges inherent in the quantum-classical amalgamation, addressing issues related to quantum hardware constraints, error correction mechanisms, and scalability considerations. This research is positioned at the forefront of quantum-enhanced machine learning, presenting a critical stride towards harnessing the computational power of quantum systems to expedite the training of Generative Adversarial Networks. Through our comprehensive examination of the interface between classical and quantum realms, we aim to uncover transformative insights that will propel the field forward, fostering innovation and advancing the frontier of quantum machine learning.
Secure Information Embedding in Images with Hybrid Firefly Algorithm
Dec 21, 2023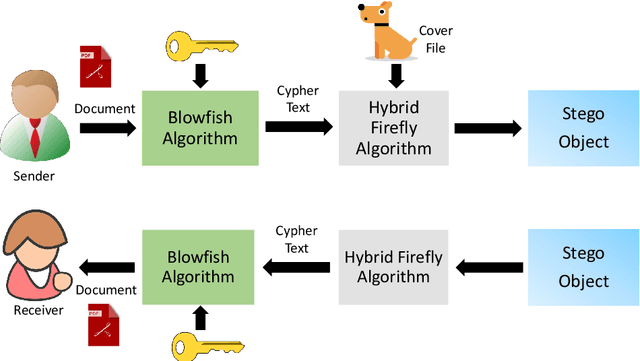



Various methods have been proposed to secure access to sensitive information over time, such as the many cryptographic methods in use to facilitate secure communications on the internet. But other methods like steganography have been overlooked which may be more suitable in cases where the act of transmission of sensitive information itself should remain a secret. Multiple techniques that are commonly discussed for such scenarios suffer from low capacity and high distortion in the output signal. This research introduces a novel steganographic approach for concealing a confidential portable document format (PDF) document within a host image by employing the Hybrid Firefly algorithm (HFA) proposed to select the pixel arrangement. This algorithm combines two widely used optimization algorithms to improve their performance. The suggested methodology utilizes the HFA algorithm to conduct a search for optimal pixel placements in the spatial domain. The purpose of this search is to accomplish two main goals: increasing the host image's capacity and reducing distortion. Moreover, the proposed approach intends to reduce the time required for the embedding procedure. The findings indicate a decrease in image distortion and an accelerated rate of convergence in the search process. The resultant embeddings exhibit robustness against steganalytic assaults, hence rendering the identification of the embedded data a formidable undertaking.
PBES: PCA Based Exemplar Sampling Algorithm for Continual Learning
Dec 14, 2023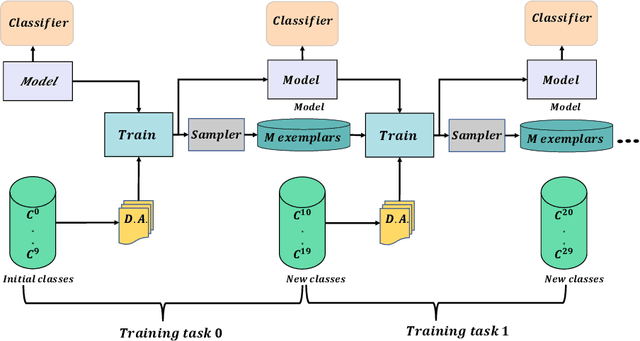
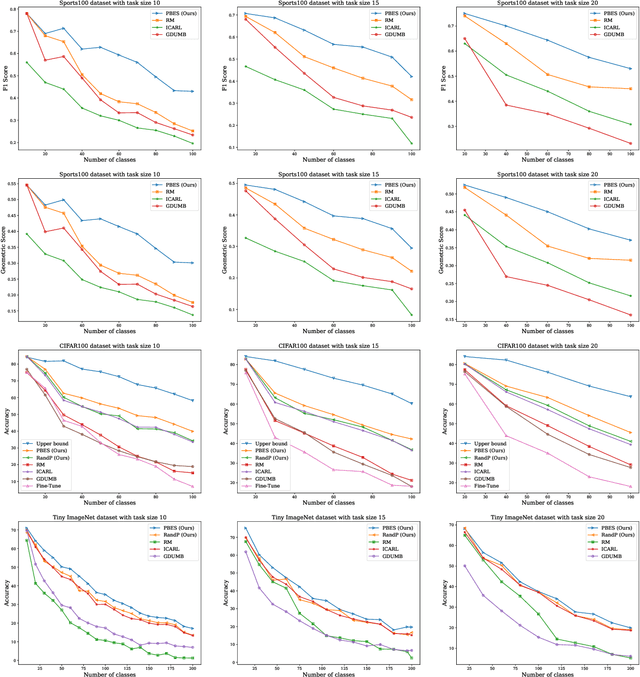
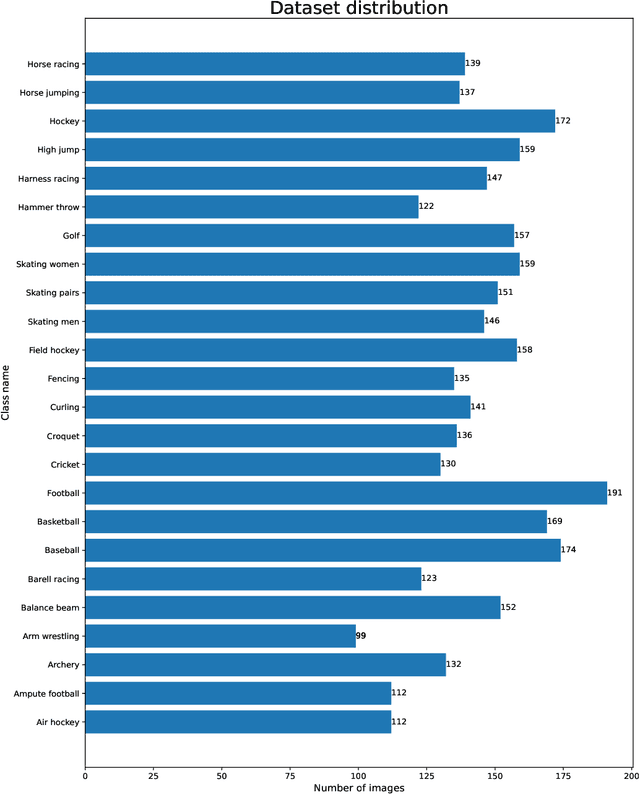
We propose a novel exemplar selection approach based on Principal Component Analysis (PCA) and median sampling, and a neural network training regime in the setting of class-incremental learning. This approach avoids the pitfalls due to outliers in the data and is both simple to implement and use across various incremental machine learning models. It also has independent usage as a sampling algorithm. We achieve better performance compared to state-of-the-art methods.
DSS: A Diverse Sample Selection Method to Preserve Knowledge in Class-Incremental Learning
Dec 14, 2023Rehearsal-based techniques are commonly used to mitigate catastrophic forgetting (CF) in Incremental learning (IL). The quality of the exemplars selected is important for this purpose and most methods do not ensure the appropriate diversity of the selected exemplars. We propose a new technique "DSS" -- Diverse Selection of Samples from the input data stream in the Class-incremental learning (CIL) setup under both disjoint and fuzzy task boundary scenarios. Our method outperforms state-of-the-art methods and is much simpler to understand and implement.
RTRA: Rapid Training of Regularization-based Approaches in Continual Learning
Dec 14, 2023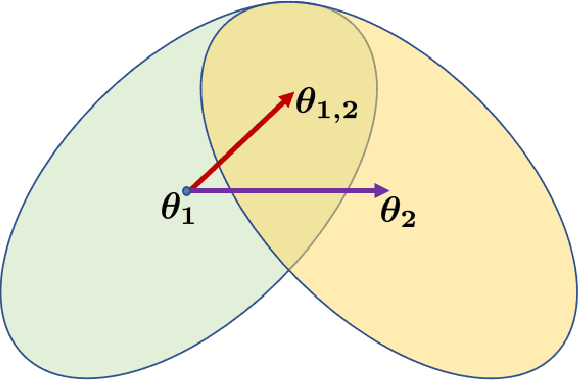
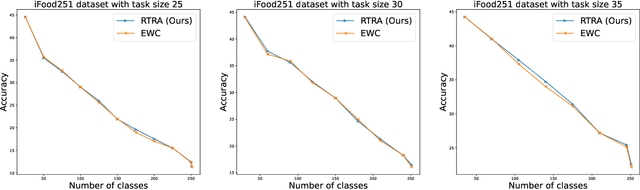
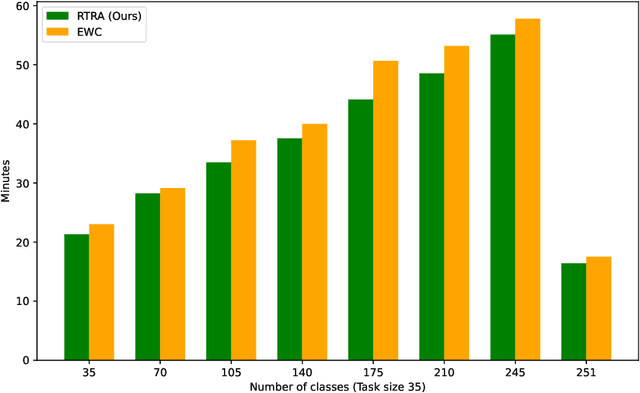
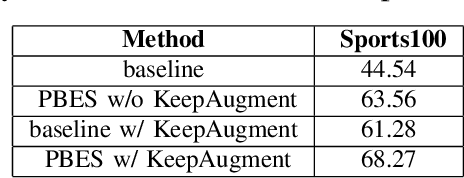
Catastrophic forgetting(CF) is a significant challenge in continual learning (CL). In regularization-based approaches to mitigate CF, modifications to important training parameters are penalized in subsequent tasks using an appropriate loss function. We propose the RTRA, a modification to the widely used Elastic Weight Consolidation (EWC) regularization scheme, using the Natural Gradient for loss function optimization. Our approach improves the training of regularization-based methods without sacrificing test-data performance. We compare the proposed RTRA approach against EWC using the iFood251 dataset. We show that RTRA has a clear edge over the state-of-the-art approaches.
EmbAu: A Novel Technique to Embed Audio Data Using Shuffled Frog Leaping Algorithm
Dec 13, 2023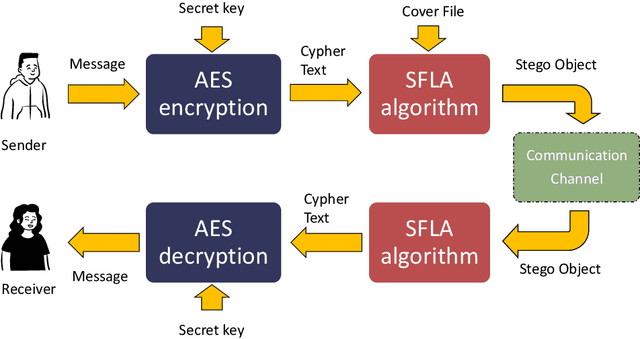



The aim of steganographic algorithms is to identify the appropriate pixel positions in the host or cover image, where bits of sensitive information can be concealed for data encryption. Work is being done to improve the capacity to integrate sensitive information and to maintain the visual appearance of the steganographic image. Consequently, steganography is a challenging research area. In our currently proposed image steganographic technique, we used the Shuffled Frog Leaping Algorithm (SFLA) to determine the order of pixels by which sensitive information can be placed in the cover image. To achieve greater embedding capacity, pixels from the spatial domain of the cover image are carefully chosen and used for placing the sensitive data. Bolstered via image steganography, the final image after embedding is resistant to steganalytic attacks. The SFLA algorithm serves in the optimal pixels selection of any colored (RGB) cover image for secret bit embedding. Using the fitness function, the SFLA benefits by reaching a minimum cost value in an acceptable amount of time. The pixels for embedding are meticulously chosen to minimize the host image's distortion upon embedding. Moreover, an effort has been taken to make the detection of embedded data in the steganographic image a formidable challenge. Due to the enormous need for audio data encryption in the current world, we feel that our suggested method has significant potential in real-world applications. In this paper, we propose and compare our strategy to existing steganographic methods.