 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Neural Network Training: A Brief Review
Dec 26, 2023
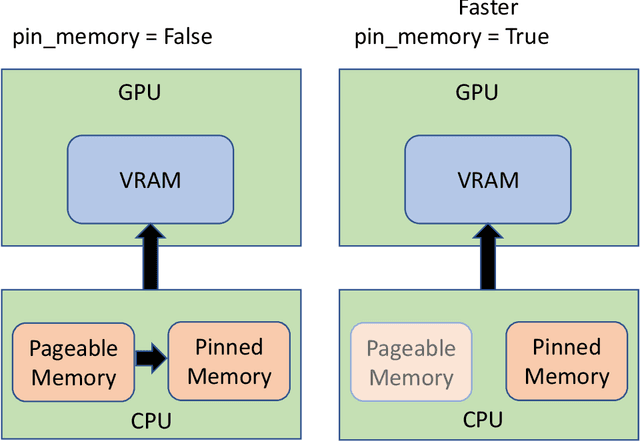

The process of training a deep neural network is characterized by significant time requirements and associated costs. Although researchers have made considerable progress in this area, further work is still required due to resource constraints. This study examines innovative approaches to expedite the training process of deep neural networks (DNN), with specific emphasis on three state-of-the-art models such as ResNet50, Vision Transformer (ViT), and EfficientNet. The research utilizes sophisticated methodologies, including Gradient Accumulation (GA), Automatic Mixed Precision (AMP), and Pin Memory (PM), in order to optimize performance and accelerate the training procedure. The study examines the effects of these methodologies on the DNN models discussed earlier, assessing their efficacy with regard to training rate and computational efficacy. The study showcases the efficacy of including GA as a strategic approach, resulting in a noteworthy decrease in the duration required for training. This enables the models to converge at a faster pace. The utilization of AMP enhances the speed of computations by taking advantage of the advantages offered by lower precision arithmetic while maintaining the correctness of the model. Furthermore, this study investigates the application of Pin Memory as a strategy to enhance the efficiency of data transmission between the central processing unit and the graphics processing unit, thereby offering a promising opportunity for enhancing overall performance. The experimental findings demonstrate that the combination of these sophisticated methodologies significantly accelerates the training of DNNs, offering vital insights for experts seeking to improve the effectiveness of deep learning processes.
Quantum Generative Adversarial Networks: Bridging Classical and Quantum Realms
Dec 26, 2023
In this pioneering research paper, we present a groundbreaking exploration into the synergistic fusion of classical and quantum computing paradigms within the realm of Generative Adversarial Networks (GANs). Our objective is to seamlessly integrate quantum computational elements into the conventional GAN architecture, thereby unlocking novel pathways for enhanced training processes. Drawing inspiration from the inherent capabilities of quantum bits (qubits), we delve into the incorporation of quantum data representation methodologies within the GAN framework. By capitalizing on the unique quantum features, we aim to accelerate the training process of GANs, offering a fresh perspective on the optimization of generative models. Our investigation deals with theoretical considerations and evaluates the potential quantum advantages that may manifest in terms of training efficiency and generative quality. We confront the challenges inherent in the quantum-classical amalgamation, addressing issues related to quantum hardware constraints, error correction mechanisms, and scalability considerations. This research is positioned at the forefront of quantum-enhanced machine learning, presenting a critical stride towards harnessing the computational power of quantum systems to expedite the training of Generative Adversarial Networks. Through our comprehensive examination of the interface between classical and quantum realms, we aim to uncover transformative insights that will propel the field forward, fostering innovation and advancing the frontier of quantum machine learning.
EmbAu: A Novel Technique to Embed Audio Data Using Shuffled Frog Leaping Algorithm
Dec 13, 2023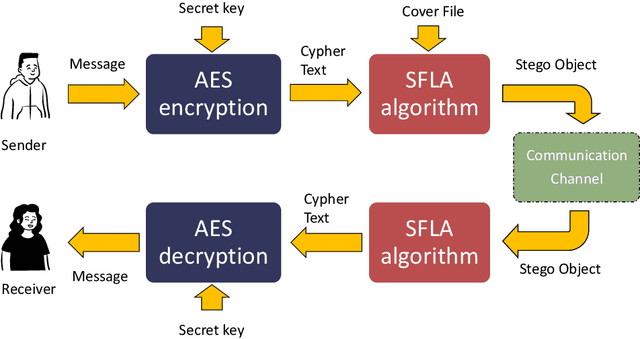



The aim of steganographic algorithms is to identify the appropriate pixel positions in the host or cover image, where bits of sensitive information can be concealed for data encryption. Work is being done to improve the capacity to integrate sensitive information and to maintain the visual appearance of the steganographic image. Consequently, steganography is a challenging research area. In our currently proposed image steganographic technique, we used the Shuffled Frog Leaping Algorithm (SFLA) to determine the order of pixels by which sensitive information can be placed in the cover image. To achieve greater embedding capacity, pixels from the spatial domain of the cover image are carefully chosen and used for placing the sensitive data. Bolstered via image steganography, the final image after embedding is resistant to steganalytic attacks. The SFLA algorithm serves in the optimal pixels selection of any colored (RGB) cover image for secret bit embedding. Using the fitness function, the SFLA benefits by reaching a minimum cost value in an acceptable amount of time. The pixels for embedding are meticulously chosen to minimize the host image's distortion upon embedding. Moreover, an effort has been taken to make the detection of embedded data in the steganographic image a formidable challenge. Due to the enormous need for audio data encryption in the current world, we feel that our suggested method has significant potential in real-world applications. In this paper, we propose and compare our strategy to existing steganographic methods.
Several categories of Large Language Models : A Short Survey
Jul 05, 2023Large Language Models(LLMs)have become effective tools for natural language processing and have been used in many different fields. This essay offers a succinct summary of various LLM subcategories. The survey emphasizes recent developments and efforts made for various LLM kinds, including task-based financial LLMs, multilingual language LLMs, biomedical and clinical LLMs, vision language LLMs, and code language models. The survey gives a general summary of the methods, attributes, datasets, transformer models, and comparison metrics applied in each category of LLMs. Furthermore, it highlights unresolved problems in the field of developing chatbots and virtual assistants, such as boosting natural language processing, enhancing chatbot intelligence, and resolving moral and legal dilemmas. The purpose of this study is to provide readers, developers, academics, and users interested in LLM-based chatbots and virtual intelligent assistant technologies with useful information and future directions.