 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Information Embedding in Images with Hybrid Firefly Algorithm
Dec 21, 2023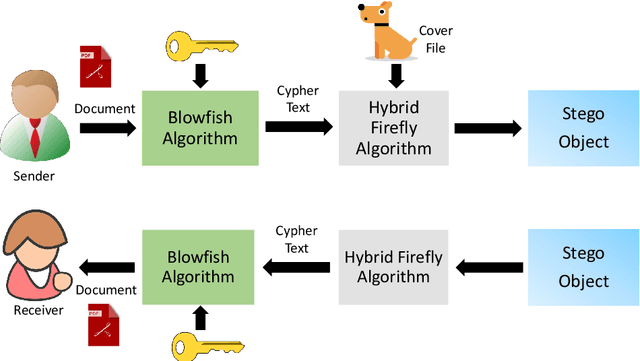



Various methods have been proposed to secure access to sensitive information over time, such as the many cryptographic methods in use to facilitate secure communications on the internet. But other methods like steganography have been overlooked which may be more suitable in cases where the act of transmission of sensitive information itself should remain a secret. Multiple techniques that are commonly discussed for such scenarios suffer from low capacity and high distortion in the output signal. This research introduces a novel steganographic approach for concealing a confidential portable document format (PDF) document within a host image by employing the Hybrid Firefly algorithm (HFA) proposed to select the pixel arrangement. This algorithm combines two widely used optimization algorithms to improve their performance. The suggested methodology utilizes the HFA algorithm to conduct a search for optimal pixel placements in the spatial domain. The purpose of this search is to accomplish two main goals: increasing the host image's capacity and reducing distortion. Moreover, the proposed approach intends to reduce the time required for the embedding procedure. The findings indicate a decrease in image distortion and an accelerated rate of convergence in the search process. The resultant embeddings exhibit robustness against steganalytic assaults, hence rendering the identification of the embedded data a formidable undertaking.
Several categories of Large Language Models : A Short Survey
Jul 05, 2023Large Language Models(LLMs)have become effective tools for natural language processing and have been used in many different fields. This essay offers a succinct summary of various LLM subcategories. The survey emphasizes recent developments and efforts made for various LLM kinds, including task-based financial LLMs, multilingual language LLMs, biomedical and clinical LLMs, vision language LLMs, and code language models. The survey gives a general summary of the methods, attributes, datasets, transformer models, and comparison metrics applied in each category of LLMs. Furthermore, it highlights unresolved problems in the field of developing chatbots and virtual assistants, such as boosting natural language processing, enhancing chatbot intelligence, and resolving moral and legal dilemmas. The purpose of this study is to provide readers, developers, academics, and users interested in LLM-based chatbots and virtual intelligent assistant technologies with useful information and future directions.