 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSS: A Diverse Sample Selection Method to Preserve Knowledge in Class-Incremental Learning
Dec 14, 2023Rehearsal-based techniques are commonly used to mitigate catastrophic forgetting (CF) in Incremental learning (IL). The quality of the exemplars selected is important for this purpose and most methods do not ensure the appropriate diversity of the selected exemplars. We propose a new technique "DSS" -- Diverse Selection of Samples from the input data stream in the Class-incremental learning (CIL) setup under both disjoint and fuzzy task boundary scenarios. Our method outperforms state-of-the-art methods and is much simpler to understand and implement.
PBES: PCA Based Exemplar Sampling Algorithm for Continual Learning
Dec 14, 2023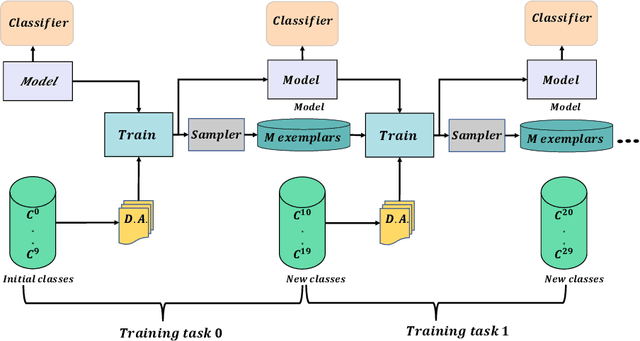
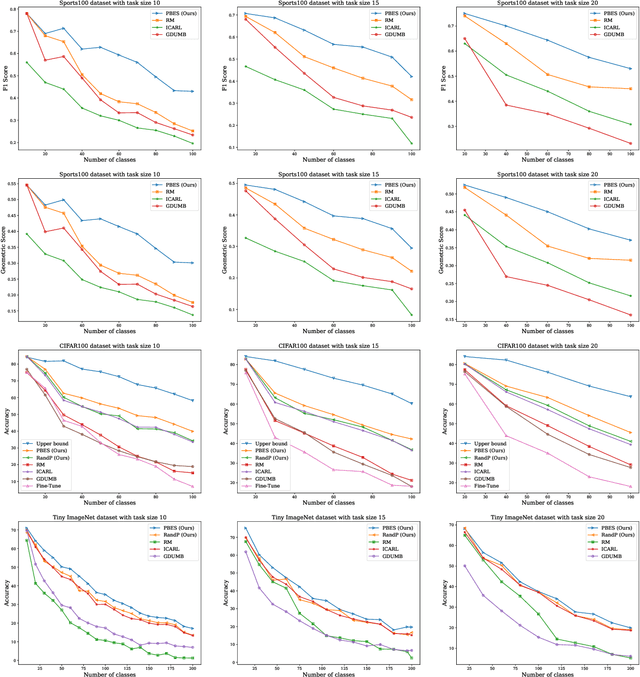
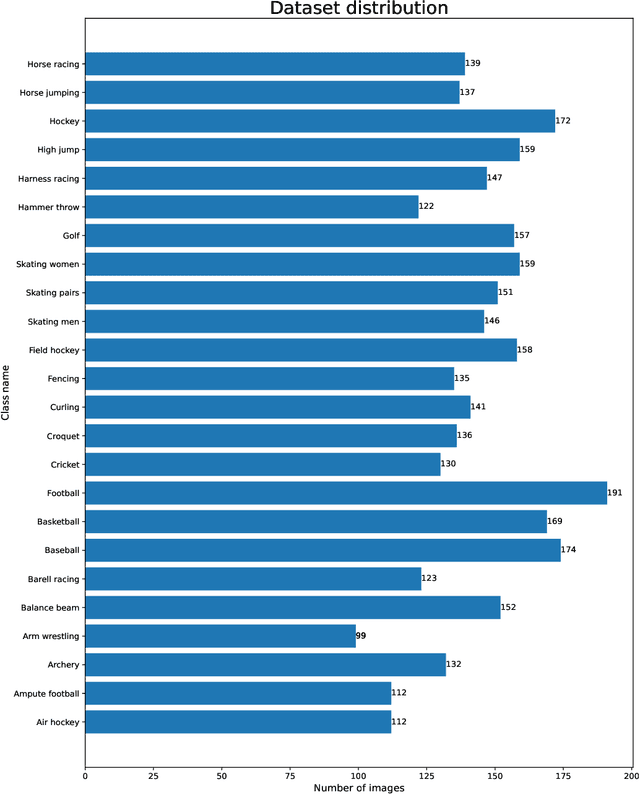
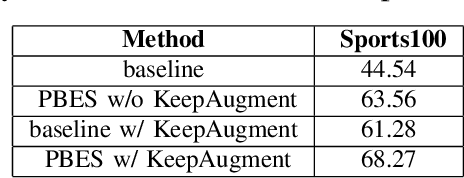
We propose a novel exemplar selection approach based on Principal Component Analysis (PCA) and median sampling, and a neural network training regime in the setting of class-incremental learning. This approach avoids the pitfalls due to outliers in the data and is both simple to implement and use across various incremental machine learning models. It also has independent usage as a sampling algorithm. We achieve better performance compared to state-of-the-art methods.
RTRA: Rapid Training of Regularization-based Approaches in Continual Learning
Dec 14, 2023
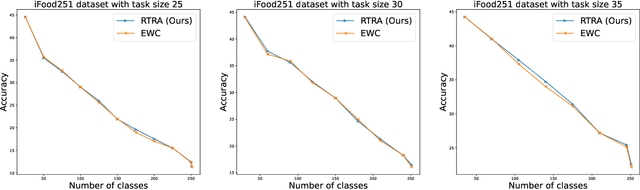
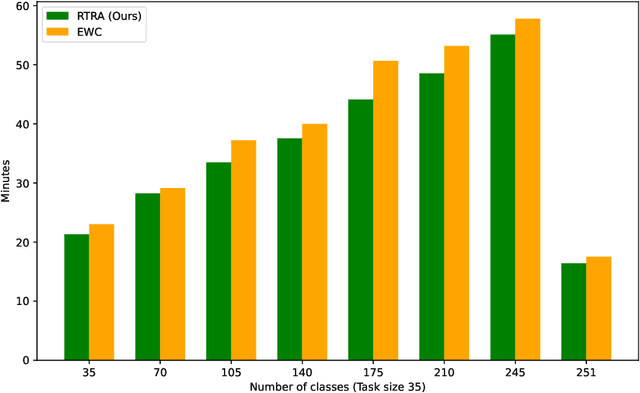
Catastrophic forgetting(CF) is a significant challenge in continual learning (CL). In regularization-based approaches to mitigate CF, modifications to important training parameters are penalized in subsequent tasks using an appropriate loss function. We propose the RTRA, a modification to the widely used Elastic Weight Consolidation (EWC) regularization scheme, using the Natural Gradient for loss function optimization. Our approach improves the training of regularization-based methods without sacrificing test-data performance. We compare the proposed RTRA approach against EWC using the iFood251 dataset. We show that RTRA has a clear edge over the state-of-the-art approaches.
CIDMP: Completely Interpretable Detection of Malaria Parasite in Red Blood Cells using Lower-dimensional Feature Space
Jul 05, 2020
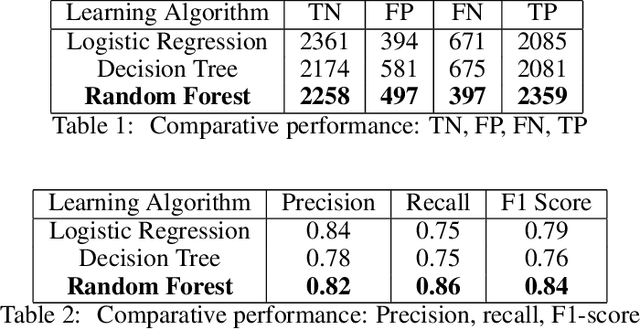
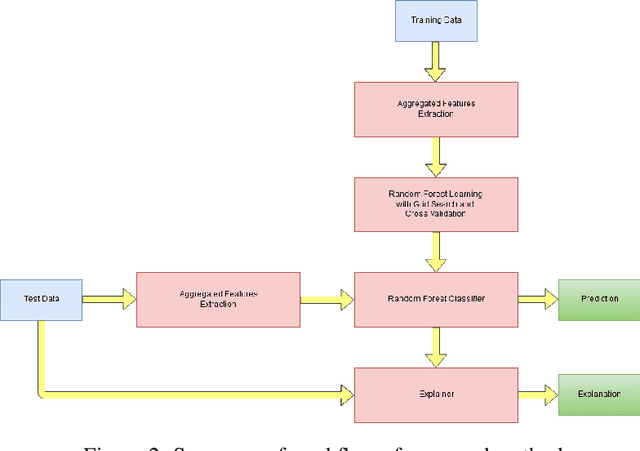
Predicting if red blood cells (RBC) are infected with the malaria parasite is an important problem in Pathology. Recently, supervised machine learning approaches have been used for this problem, and they have had reasonable success. In particular, state-of-the-art methods such as Convolutional Neural Networks automatically extract increasingly complex feature hierarchies from the image pixels. While such generalized automatic feature extraction methods have significantly reduced the burden of feature engineering in many domains, for niche tasks such as the one we consider in this paper, they result in two major problems. First, they use a very large number of features (that may or may not be relevant) and therefore training such models is computationally expensive. Further, more importantly, the large feature-space makes it very hard to interpret which features are truly important for predictions. Thus, a criticism of such methods is that learning algorithms pose opaque black boxes to its users, in this case, medical experts. The recommendation of such algorithms can be understood easily, but the reason for their recommendation is not clear. This is the problem of non-interpretability of the model, and the best-performing algorithms are usually the least interpretable. To address these issues, in this paper, we propose an approach to extract a very small number of aggregated features that are easy to interpret and compute, and empirically show that we obtain high prediction accuracy even with a significantly reduced feature-space.