 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Human Psychophysics to Evaluate Generalization in Scene Text Recognition Models
Jun 30, 2020
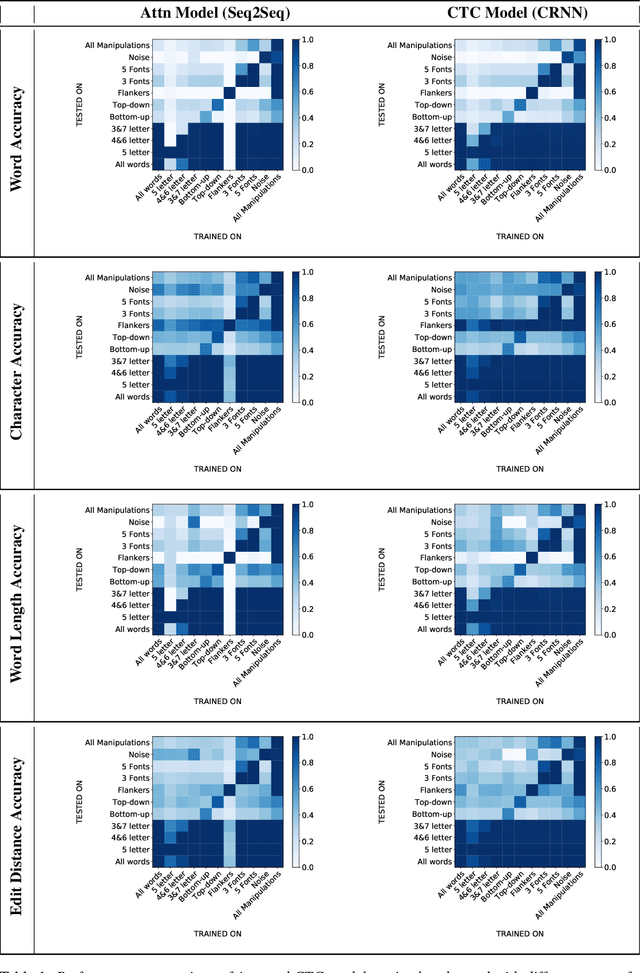
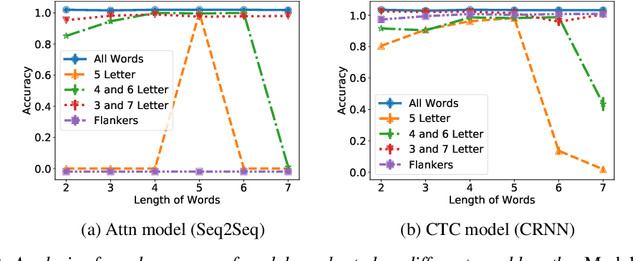
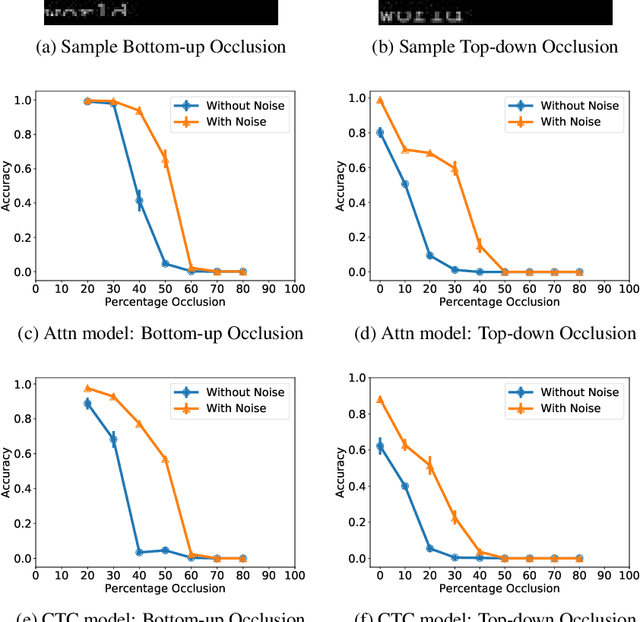
Scene text recognition models have advanced greatly in recent years. Inspired by human reading we characterize two important scene text recognition models by measuring their domains i.e. the range of stimulus images that they can read. The domain specifies the ability of readers to generalize to different word lengths, fonts, and amounts of occlusion. These metrics identify strengths and weaknesses of existing models. Relative to the attention-based (Attn) model, we discover that the connectionist temporal classification (CTC) model is more robust to noise and occlusion, and better at generalizing to different word lengths. Further, we show that in both models, adding noise to training images yields better generalization to occlusion. These results demonstrate the value of testing models till they break, complementing the traditional data science focus on optimizing performance.