 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListBERT: Learning to Rank E-commerce products with Listwise BERT
Jun 30, 2022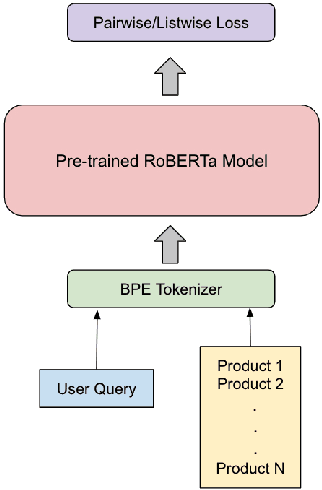
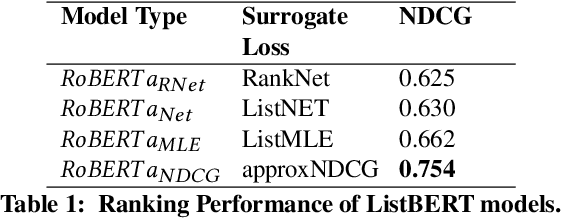
Efficient search is a critical component for an e-commerce platform with an innumerable number of products. Every day millions of users search for products pertaining to their needs. Thus, showing the relevant products on the top will enhance the user experience. In this work, we propose a novel approach of fusing a transformer-based model with various listwise loss functions for ranking e-commerce products, given a user query. We pre-train a RoBERTa model over a fashion e-commerce corpus and fine-tune it using different listwise loss functions. Our experiments indicate that the RoBERTa model fine-tuned with an NDCG based surrogate loss function(approxNDCG) achieves an NDCG improvement of 13.9% compared to other popular listwise loss functions like ListNET and ListMLE. The approxNDCG based RoBERTa model also achieves an NDCG improvement of 20.6% compared to the pairwise RankNet based RoBERTa model. We call our methodology of directly optimizing the RoBERTa model in an end-to-end manner with a listwise surrogate loss function as ListBERT. Since there is a low latency requirement in a real-time search setting, we show how these models can be easily adopted by using a knowledge distillation technique to learn a representation-focused student model that can be easily deployed and leads to ~10 times lower ranking latency.
Neural Search: Learning Query and Product Representations in Fashion E-commerce
Jul 17, 2021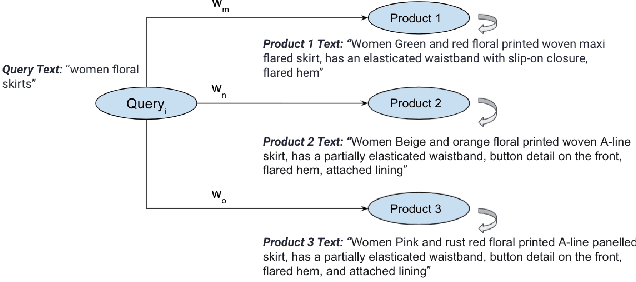
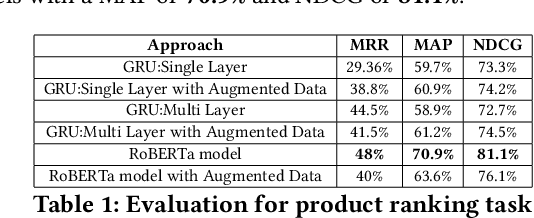
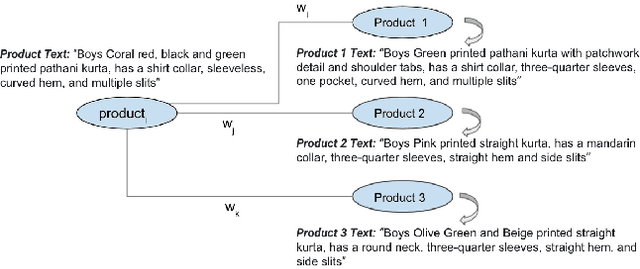
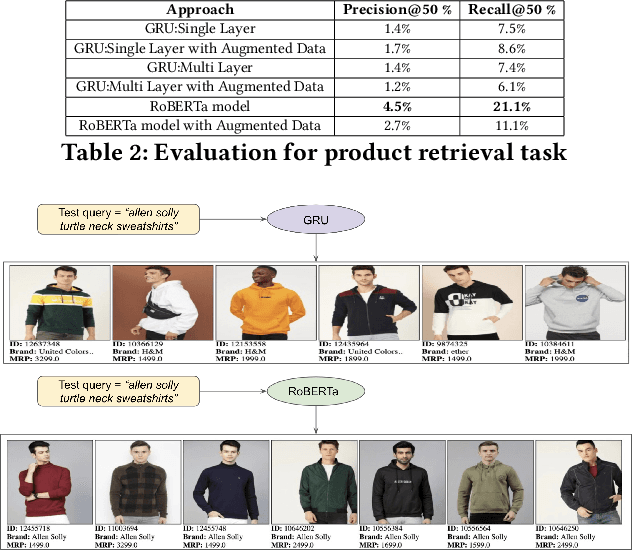
Typical e-commerce platforms contain millions of products in the catalog. Users visit these platforms and enter search queries to retrieve their desired products. Therefore, showing the relevant products at the top is essential for the success of e-commerce platforms. We approach this problem by learning low dimension representations for queries and product descriptions by leveraging user click-stream data as our main source of signal for product relevance. Starting from GRU-based architectures as our baseline model, we move towards a more advanced transformer-based architecture. This helps the model to learn contextual representations of queries and products to serve better search results and understand the user intent in an efficient manner. We perform experiments related to pre-training of the Transformer based RoBERTa model using a fashion corpus and fine-tuning it over the triplet loss. Our experiments on the product ranking task show that the RoBERTa model is able to give an improvement of 7.8% in Mean Reciprocal Rank(MRR), 15.8% in Mean Average Precision(MAP) and 8.8% in Normalized Discounted Cumulative Gain(NDCG), thus outperforming our GRU based baselines. For the product retrieval task, RoBERTa model is able to outperform other two models with an improvement of 164.7% in Precision@50 and 145.3% in Recall@50. In order to highlight the importance of pre-training RoBERTa for fashion domain, we qualitatively compare already pre-trained RoBERTa on standard datasets with our custom pre-trained RoBERTa over a fashion corpus for the query token prediction task. Finally, we also show a qualitative comparison between GRU and RoBERTa results for product retrieval task for some test queries.
Genetic CFL: Optimization of Hyper-Parameters in Clustered Federated Learning
Jul 17, 2021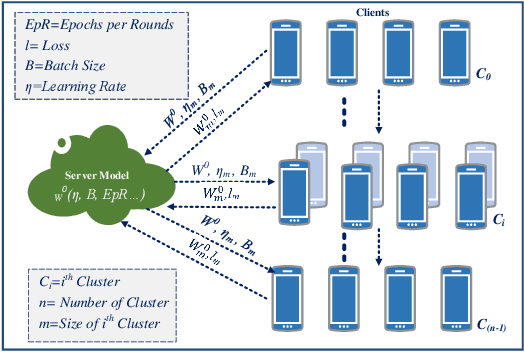
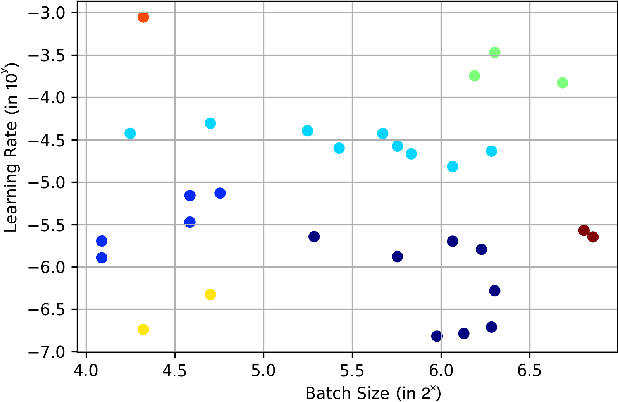
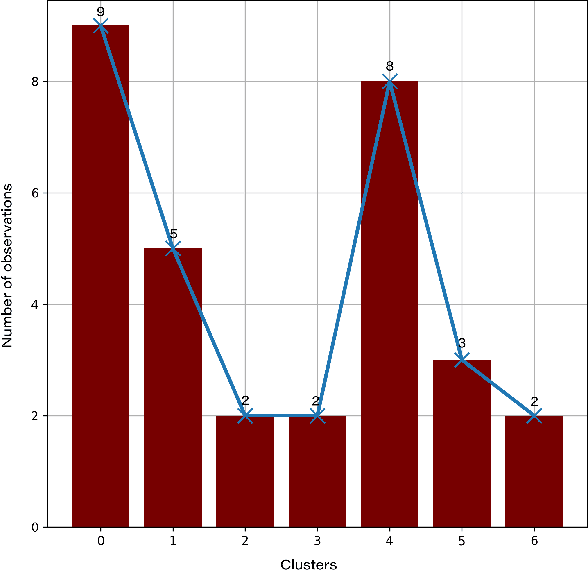
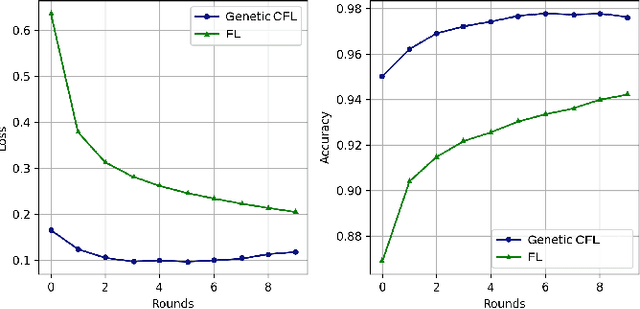
Federated learning (FL) is a distributed model for deep learning that integrates client-server architecture, edge computing, and real-time intelligence. FL has the capability of revolutionizing machine learning (ML) but lacks in the practicality of implementation due to technological limitations, communication overhead, non-IID (independent and identically distributed) data, and privacy concerns. Training a ML model over heterogeneous non-IID data highly degrades the convergence rate and performance. The existing traditional and clustered FL algorithms exhibit two main limitations, including inefficient client training and static hyper-parameter utilization. To overcome these limitations, we propose a novel hybrid algorithm, namely genetic clustered FL (Genetic CFL), that clusters edge devices based on the training hyper-parameters and genetically modifies the parameters cluster-wise. Then, we introduce an algorithm that drastically increases the individual cluster accuracy by integrating the density-based clustering and genetic hyper-parameter optimization. The results are bench-marked using MNIST handwritten digit dataset and the CIFAR-10 dataset. The proposed genetic CFL shows significant improvements and works well with realistic cases of non-IID and ambiguous data.
Federated Learning for Intrusion Detection System: Concepts, Challenges and Future Directions
Jun 16, 2021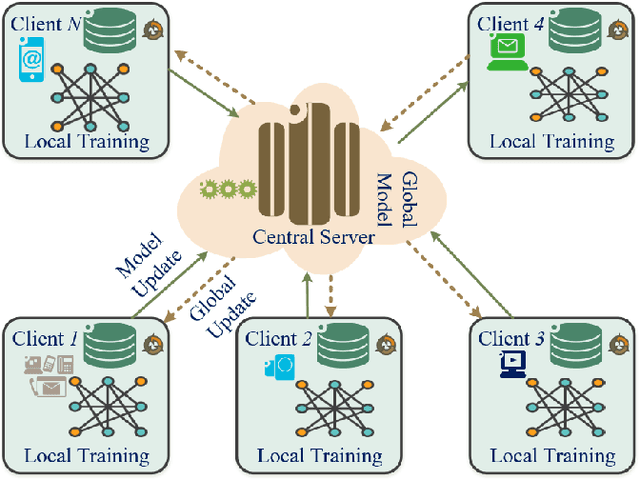

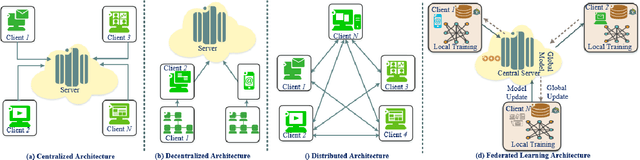
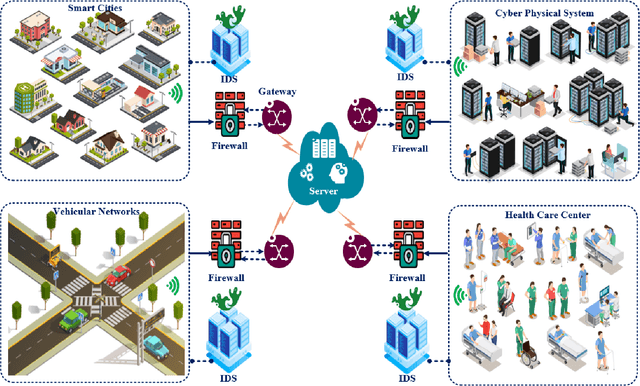
The rapid development of the Internet and smart devices trigger surge in network traffic making its infrastructure more complex and heterogeneous. The predominated usage of mobile phones, wearable devices and autonomous vehicles are examples of distributed networks which generate huge amount of data each and every day. The computational power of these devices have also seen steady progression which has created the need to transmit information, store data locally and drive network computations towards edge devices. Intrusion detection systems play a significant role in ensuring security and privacy of such devices. Machine Learning and Deep Learning with Intrusion Detection Systems have gained great momentum due to their achievement of high classification accuracy. However the privacy and security aspects potentially gets jeopardised due to the need of storing and communicating data to centralized server. On the contrary, federated learning (FL) fits in appropriately as a privacy-preserving decentralized learning technique that does not transfer data but trains models locally and transfers the parameters to the centralized server. The present paper aims to present an extensive and exhaustive review on the use of FL in intrusion detection system. In order to establish the need for FL, various types of IDS, relevant ML approaches and its associated issues are discussed. The paper presents detailed overview of the implementation of FL in various aspects of anomaly detection. The allied challenges of FL implementations are also identified which provides idea on the scope of future direction of research. The paper finally presents the plausible solutions associated with the identified challenges in FL based intrusion detection system implementation acting as a baseline for prospective research.
Genetically Optimized Prediction of Remaining Useful Life
Feb 17, 2021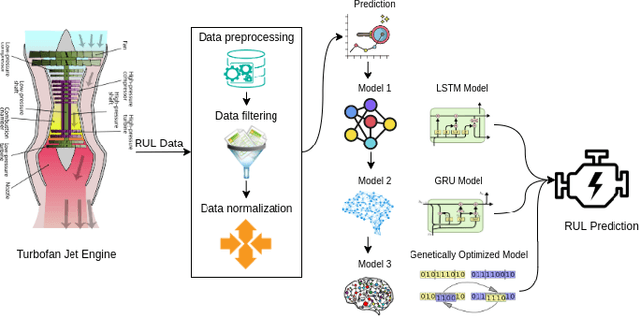
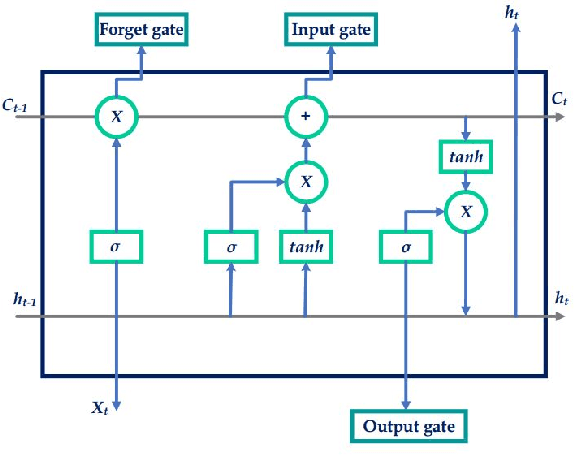
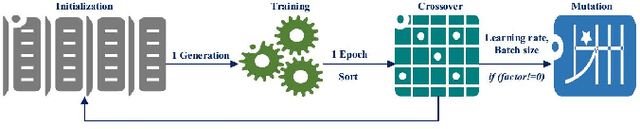
The application of remaining useful life (RUL) prediction has taken great importance in terms of energy optimization, cost-effectiveness, and risk mitigation. The existing RUL prediction algorithms mostly constitute deep learning frameworks. In this paper, we implement LSTM and GRU models and compare the obtained results with a proposed genetically trained neural network. The current models solely depend on Adam and SGD for optimization and learning. Although the models have worked well with these optimizers, even little uncertainties in prognostics prediction can result in huge losses. We hope to improve the consistency of the predictions by adding another layer of optimization using Genetic Algorithms. The hyper-parameters - learning rate and batch size are optimized beyond manual capacity. These models and the proposed architecture are tested on the NASA Turbofan Jet Engine dataset. The optimized architecture can predict the given hyper-parameters autonomously and provide superior results.