 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARNESS-LM: A Three-Phase Training Recipe for Harnessing SLMs in Sponsored Search Retrieval
May 22, 2026In the competitive landscape of sponsored search, balancing retrieval quality with production latency is a critical challenge. While large retrieval models based on Small Language Models (SLMs) such as Qwen3-Embedding-4B/8B set strong upper bounds on public benchmarks, their deployment in high-throughput, latency-sensitive environments remains impractical. In this paper, we present HARNESS-LM (HLM), a three-phase training framework for transferring the capabilities of large-scale retrievers into compact, cost-efficient models. The approach comprises: (1) training a high-performance reference ("teacher") retriever by fine-tuning a billion-parameter-scale SLM; (2) aligning query representations via an L2 objective to distill knowledge into a sub-600M parameter student encoder; and (3) applying a final contrastive refinement stage to optimize the student for retrieval performance. We also present a comprehensive empirical study of key design choices, including alignment objectives, embedding dimensionality, model scale, architecture, and optimization strategies, to identify configurations that are most effective in production settings. On a real-world Bing Ads evaluation benchmark, HLM recovers over 98% of the reference retriever's precision across multiple settings, while delivering up to 27x lower online query-encoder latency and 20x higher throughput on NVIDIA A100 GPUs. Online A/B testing on Bing Ads further shows a +1% Revenue, +0.6% Impression, and +0.4% Click uplift over the current ensemble of retrievers running in production with the deployed 190M parameter model, clearly highlighting the practical efficacy of the HLM recipe in a real-world sponsored search setting.
Learning-To-Embed: Adopting Transformer based models for E-commerce Products Representation Learning
Dec 07, 2022



Learning low-dimensional representation for large number of products present in an e-commerce catalogue plays a vital role as they are helpful in tasks like product ranking, product recommendation, finding similar products, modelling user-behaviour etc. Recently, a lot of tasks in the NLP field are getting tackled using the Transformer based models and these deep models are widely applicable in the industries setting to solve various problems. With this motivation, we apply transformer based model for learning contextual representation of products in an e-commerce setting. In this work, we propose a novel approach of pre-training transformer based model on a users generated sessions dataset obtained from a large fashion e-commerce platform to obtain latent product representation. Once pre-trained, we show that the low-dimension representation of the products can be obtained given the product attributes information as a textual sentence. We mainly pre-train BERT, RoBERTa, ALBERT and XLNET variants of transformer model and show a quantitative analysis of the products representation obtained from these models with respect to Next Product Recommendation(NPR) and Content Ranking(CR) tasks. For both the tasks, we collect an evaluation data from the fashion e-commerce platform and observe that XLNET model outperform other variants with a MRR of 0.5 for NPR and NDCG of 0.634 for CR. XLNET model also outperforms the Word2Vec based non-transformer baseline on both the downstream tasks. To the best of our knowledge, this is the first and novel work for pre-training transformer based models using users generated sessions data containing products that are represented with rich attributes information for adoption in e-commerce setting. These models can be further fine-tuned in order to solve various downstream tasks in e-commerce, thereby eliminating the need to train a model from scratch.
ListBERT: Learning to Rank E-commerce products with Listwise BERT
Jun 30, 2022
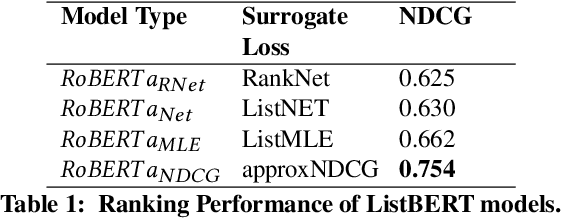
Efficient search is a critical component for an e-commerce platform with an innumerable number of products. Every day millions of users search for products pertaining to their needs. Thus, showing the relevant products on the top will enhance the user experience. In this work, we propose a novel approach of fusing a transformer-based model with various listwise loss functions for ranking e-commerce products, given a user query. We pre-train a RoBERTa model over a fashion e-commerce corpus and fine-tune it using different listwise loss functions. Our experiments indicate that the RoBERTa model fine-tuned with an NDCG based surrogate loss function(approxNDCG) achieves an NDCG improvement of 13.9% compared to other popular listwise loss functions like ListNET and ListMLE. The approxNDCG based RoBERTa model also achieves an NDCG improvement of 20.6% compared to the pairwise RankNet based RoBERTa model. We call our methodology of directly optimizing the RoBERTa model in an end-to-end manner with a listwise surrogate loss function as ListBERT. Since there is a low latency requirement in a real-time search setting, we show how these models can be easily adopted by using a knowledge distillation technique to learn a representation-focused student model that can be easily deployed and leads to ~10 times lower ranking latency.
Neural Search: Learning Query and Product Representations in Fashion E-commerce
Jul 17, 2021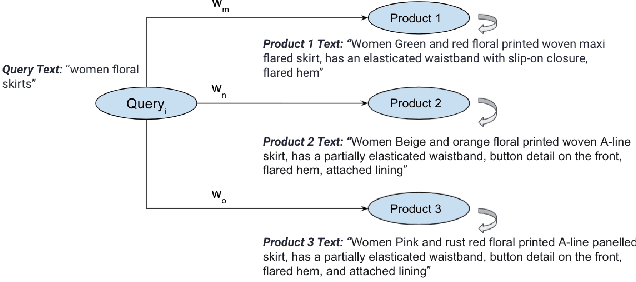
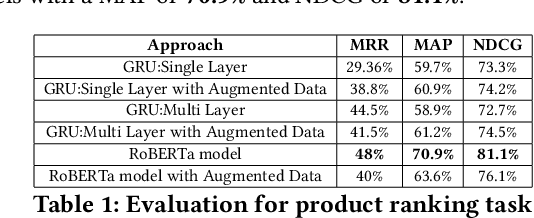
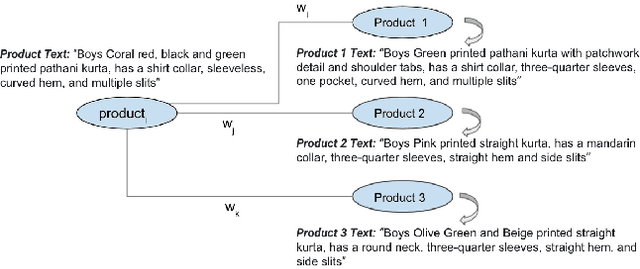
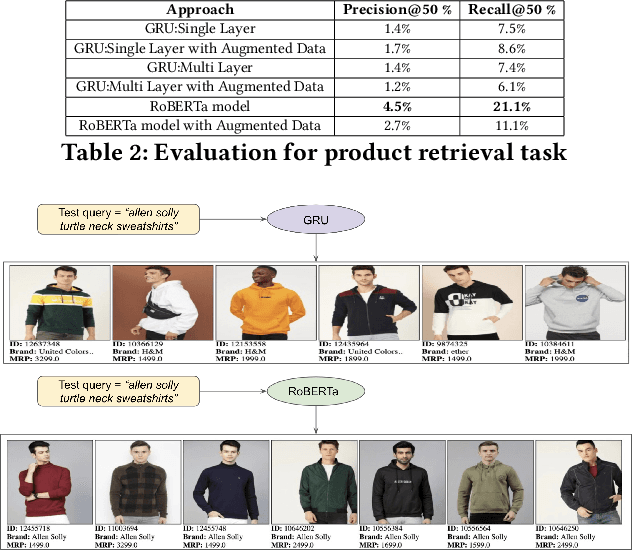
Typical e-commerce platforms contain millions of products in the catalog. Users visit these platforms and enter search queries to retrieve their desired products. Therefore, showing the relevant products at the top is essential for the success of e-commerce platforms. We approach this problem by learning low dimension representations for queries and product descriptions by leveraging user click-stream data as our main source of signal for product relevance. Starting from GRU-based architectures as our baseline model, we move towards a more advanced transformer-based architecture. This helps the model to learn contextual representations of queries and products to serve better search results and understand the user intent in an efficient manner. We perform experiments related to pre-training of the Transformer based RoBERTa model using a fashion corpus and fine-tuning it over the triplet loss. Our experiments on the product ranking task show that the RoBERTa model is able to give an improvement of 7.8% in Mean Reciprocal Rank(MRR), 15.8% in Mean Average Precision(MAP) and 8.8% in Normalized Discounted Cumulative Gain(NDCG), thus outperforming our GRU based baselines. For the product retrieval task, RoBERTa model is able to outperform other two models with an improvement of 164.7% in Precision@50 and 145.3% in Recall@50. In order to highlight the importance of pre-training RoBERTa for fashion domain, we qualitatively compare already pre-trained RoBERTa on standard datasets with our custom pre-trained RoBERTa over a fashion corpus for the query token prediction task. Finally, we also show a qualitative comparison between GRU and RoBERTa results for product retrieval task for some test queries.
Deep Contextual Embeddings for Address Classification in E-commerce
Jul 06, 2020



E-commerce customers in developing nations like India tend to follow no fixed format while entering shipping addresses. Parsing such addresses is challenging because of a lack of inherent structure or hierarchy. It is imperative to understand the language of addresses, so that shipments can be routed without delays. In this paper, we propose a novel approach towards understanding customer addresses by deriving motivation from recent advances in Natural Language Processing (NLP). We also formulate different pre-processing steps for addresses using a combination of edit distance and phonetic algorithms. Then we approach the task of creating vector representations for addresses using Word2Vec with TF-IDF, Bi-LSTM and BERT based approaches. We compare these approaches with respect to sub-region classification task for North and South Indian cities. Through experiments, we demonstrate the effectiveness of generalized RoBERTa model, pre-trained over a large address corpus for language modelling task. Our proposed RoBERTa model achieves a classification accuracy of around 90% with minimal text preprocessing for sub-region classification task outperforming all other approaches. Once pre-trained, the RoBERTa model can be fine-tuned for various downstream tasks in supply chain like pincode suggestion and geo-coding. The model generalizes well for such tasks even with limited labelled data. To the best of our knowledge, this is the first of its kind research proposing a novel approach of understanding customer addresses in e-commerce domain by pre-training language models and fine-tuning them for different purposes.
"Having 2 hours to write a paper is fun!": Detecting Sarcasm in Numerical Portions of Text
Sep 06, 2017



Sarcasm occurring due to the presence of numerical portions in text has been quoted as an error made by automatic sarcasm detection approaches in the past. We present a first study in detecting sarcasm in numbers, as in the case of the sentence 'Love waking up at 4 am'. We analyze the challenges of the problem, and present Rule-based, Machine Learning and Deep Learning approaches to detect sarcasm in numerical portions of text. Our Deep Learning approach outperforms four past works for sarcasm detection and Rule-based and Machine learning approaches on a dataset of tweets, obtaining an F1-score of 0.93. This shows that special attention to text containing numbers may be useful to improve state-of-the-art in sarcasm detection.