 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing representations of long clinical texts for the task of patient note-identification
Mar 31, 2025



In this paper, we address the challenge of patient-note identification, which involves accurately matching an anonymized clinical note to its corresponding patient, represented by a set of related notes. This task has broad applications, including duplicate records detection and patient similarity analysis, which require robust patient-level representations. We explore various embedding methods, including Hierarchical Attention Networks (HAN), three-level Hierarchical Transformer Networks (HTN), LongFormer, and advanced BERT-based models, focusing on their ability to process mediumto-long clinical texts effectively. Additionally, we evaluate different pooling strategies (mean, max, and mean_max) for aggregating wordlevel embeddings into patient-level representations and we examine the impact of sliding windows on model performance. Our results indicate that BERT-based embeddings outperform traditional and hierarchical models, particularly in processing lengthy clinical notes and capturing nuanced patient representations. Among the pooling strategies, mean_max pooling consistently yields the best results, highlighting its ability to capture critical features from clinical notes. Furthermore, the reproduction of our results on both MIMIC dataset and Necker hospital data warehouse illustrates the generalizability of these approaches to real-world applications, emphasizing the importance of both embedding methods and aggregation strategies in optimizing patient-note identification and enhancing patient-level modeling.
Tackling Morphological Analogies Using Deep Learning -- Extended Version
Nov 09, 2021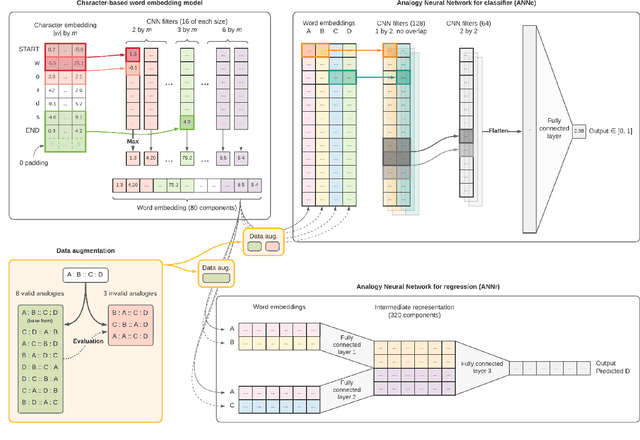
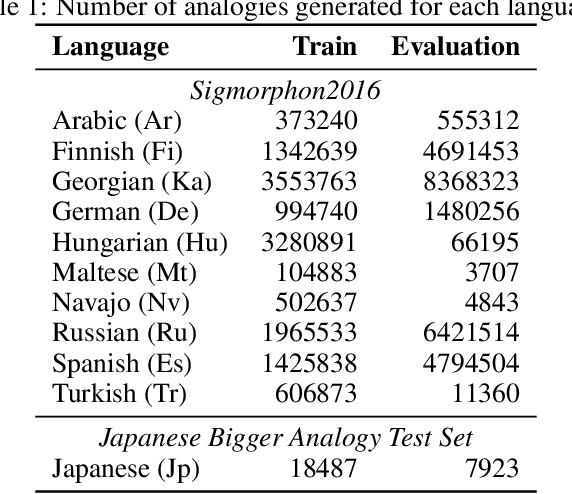
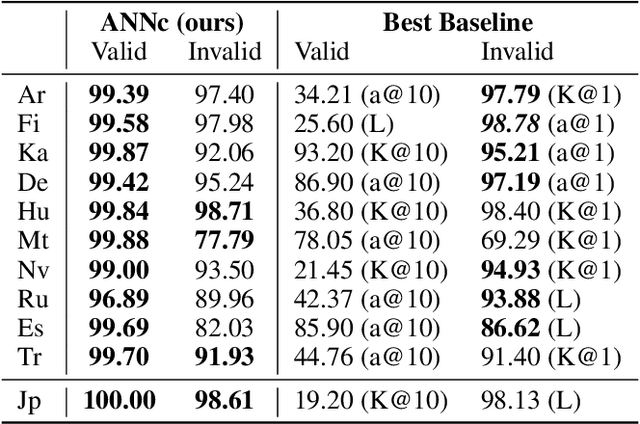
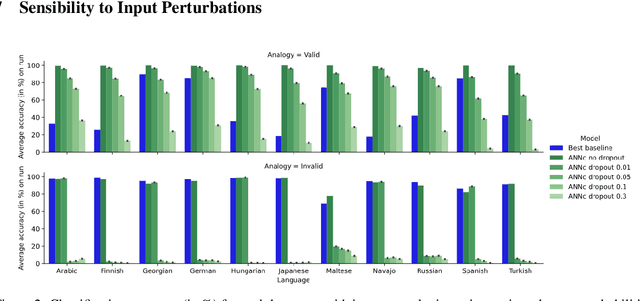
Analogical proportions are statements of the form "A is to B as C is to D". They constitute an inference tool that provides a logical framework to address learning, transfer, and explainability concerns and that finds useful applications in artificial intelligence and natural language processing. In this paper, we address two problems, namely, analogy detection and resolution in morphology. Multiple symbolic approaches tackle the problem of analogies in morphology and achieve competitive performance. We show that it is possible to use a data-driven strategy to outperform those models. We propose an approach using deep learning to detect and solve morphological analogies. It encodes structural properties of analogical proportions and relies on a specifically designed embedding model capturing morphological characteristics of words. We demonstrate our model's competitive performance on analogy detection and resolution over multiple languages. We provide an empirical study to analyze the impact of balancing training data and evaluate the robustness of our approach to input perturbation.
A Neural Approach for Detecting Morphological Analogies
Aug 09, 2021
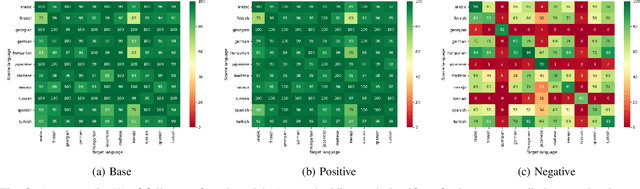
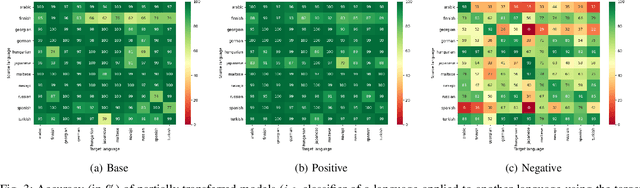
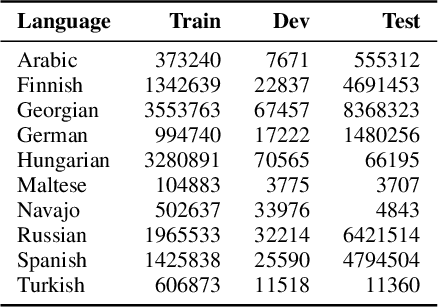
Analogical proportions are statements of the form "A is to B as C is to D" that are used for several reasoning and classification tasks in artificial intelligence and natural language processing (NLP). For instance, there are analogy based approaches to semantics as well as to morphology. In fact, symbolic approaches were developed to solve or to detect analogies between character strings, e.g., the axiomatic approach as well as that based on Kolmogorov complexity. In this paper, we propose a deep learning approach to detect morphological analogies, for instance, with reinflexion or conjugation. We present empirical results that show that our framework is competitive with the above-mentioned state of the art symbolic approaches. We also explore empirically its transferability capacity across languages, which highlights interesting similarities between them.
On the Transferability of Neural Models of Morphological Analogies
Aug 09, 2021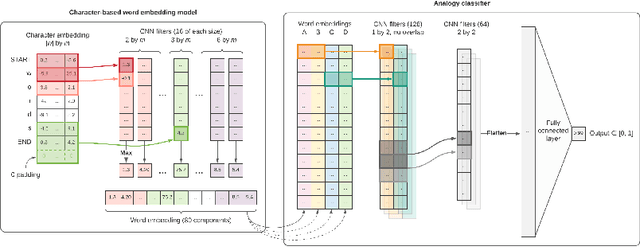
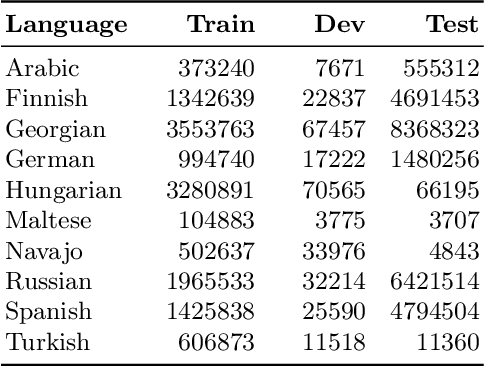
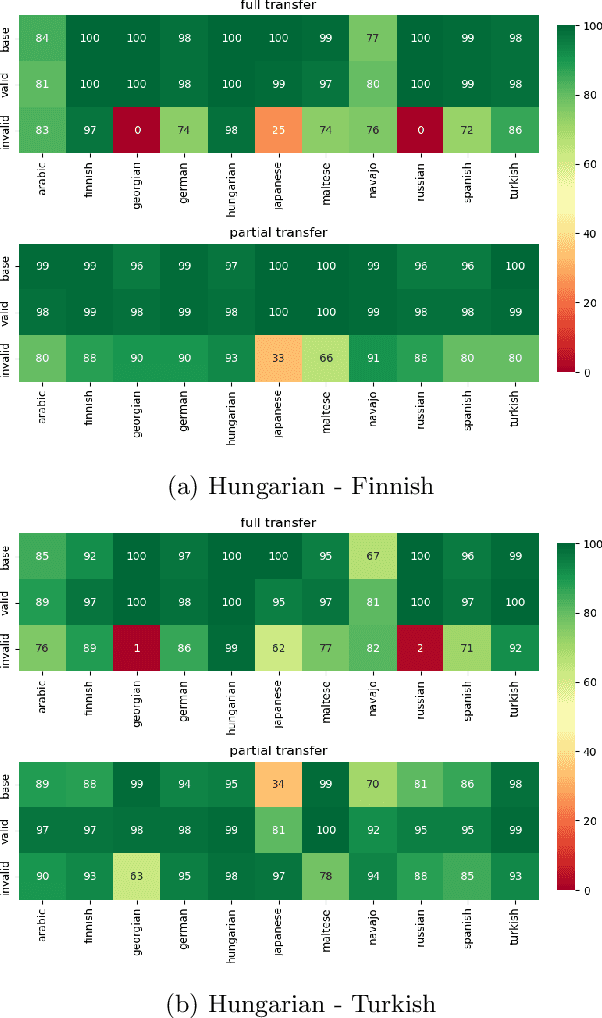
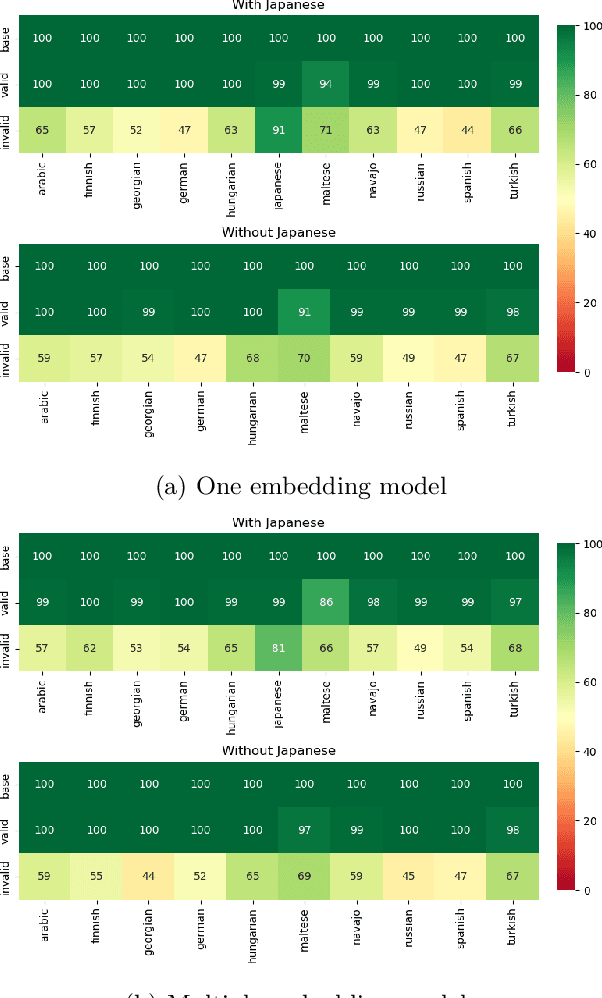
Analogical proportions are statements expressed in the form "A is to B as C is to D" and are used for several reasoning and classification tasks in artificial intelligence and natural language processing (NLP). In this paper, we focus on morphological tasks and we propose a deep learning approach to detect morphological analogies. We present an empirical study to see how our framework transfers across languages, and that highlights interesting similarities and differences between these languages. In view of these results, we also discuss the possibility of building a multilingual morphological model.