 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Robustness of Reasoning Models on Parameterized Logical Problems
Feb 13, 2026Logic provides a controlled testbed for evaluating LLM-based reasoners, yet standard SAT-style benchmarks often conflate surface difficulty (length, wording, clause order) with the structural phenomena that actually determine satisfiability. We introduce a diagnostic benchmark for 2-SAT built from parameterized families of structured 2--CNF formulas, where satisfiability is characterized by the implication graph and can be tuned along interpretable axes. Our generators isolate distinct competencies and failure modes: (i) contradiction-cycle UNSAT cores with controllable size and imbalance, (ii) SAT instances with a prescribed fraction of free variables to control solution multiplicity, (iii) planted backbones that modulate propagation, (iv) late bridge clauses that couple otherwise monotone regions to probe sensitivity to ordering and revision, and (v) symmetry/duplication variants that test abstraction under renaming and redundant structure. We evaluate LLM-based reasoners on decision accuracy and assignment validity, and quantify robustness under semantics-preserving perturbations such as clause reordering, filler clauses, and variable renaming. Across models, we observe sharp performance transitions under targeted structural interventions even when surface statistics are held fixed, revealing brittleness regimes that are invisible to aggregate SAT accuracy.
Solving morphological analogies: from retrieval to generation
Mar 30, 2023


Analogical inference is a remarkable capability of human reasoning, and has been used to solve hard reasoning tasks. Analogy based reasoning (AR) has gained increasing interest from the artificial intelligence community and has shown its potential in multiple machine learning tasks such as classification, decision making and recommendation with competitive results. We propose a deep learning (DL) framework to address and tackle two key tasks in AR: analogy detection and solving. The framework is thoroughly tested on the Siganalogies dataset of morphological analogical proportions (APs) between words, and shown to outperform symbolic approaches in many languages. Previous work have explored the behavior of the Analogy Neural Network for classification (ANNc) on analogy detection and of the Analogy Neural Network for retrieval (ANNr) on analogy solving by retrieval, as well as the potential of an autoencoder (AE) for analogy solving by generating the solution word. In this article we summarize these findings and we extend them by combining ANNr and the AE embedding model, and checking the performance of ANNc as an retrieval method. The combination of ANNr and AE outperforms the other approaches in almost all cases, and ANNc as a retrieval method achieves competitive or better performance than 3CosMul. We conclude with general guidelines on using our framework to tackle APs with DL.
Tackling Morphological Analogies Using Deep Learning -- Extended Version
Nov 09, 2021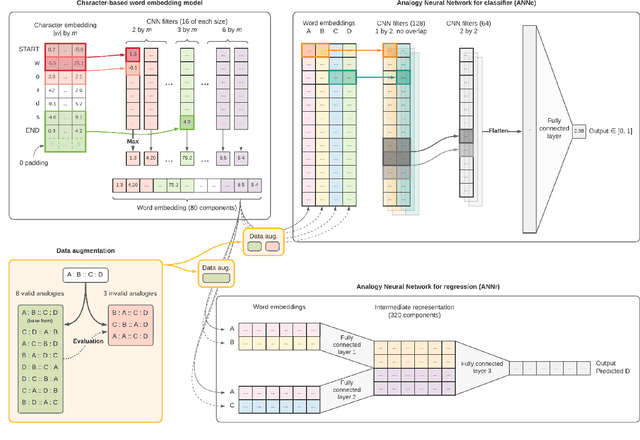
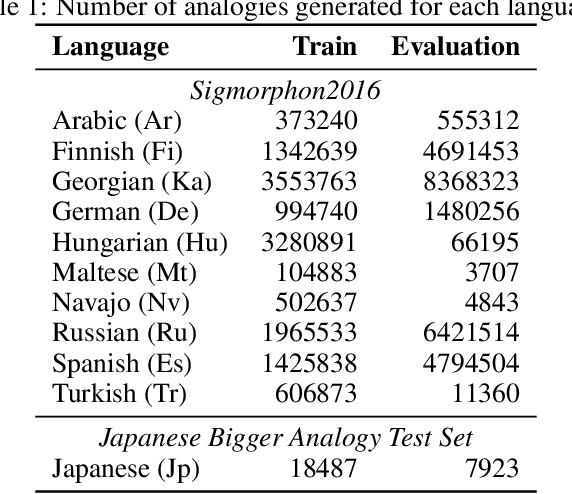
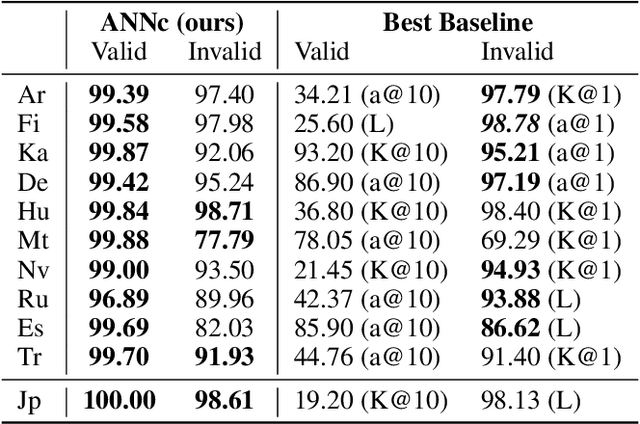
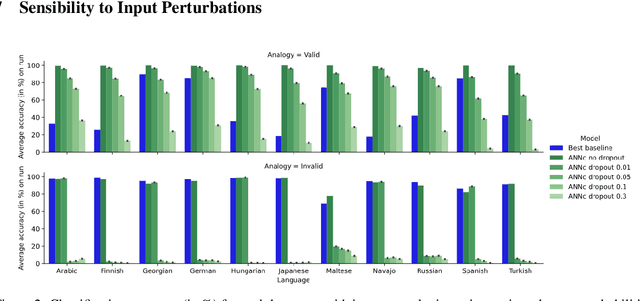
Analogical proportions are statements of the form "A is to B as C is to D". They constitute an inference tool that provides a logical framework to address learning, transfer, and explainability concerns and that finds useful applications in artificial intelligence and natural language processing. In this paper, we address two problems, namely, analogy detection and resolution in morphology. Multiple symbolic approaches tackle the problem of analogies in morphology and achieve competitive performance. We show that it is possible to use a data-driven strategy to outperform those models. We propose an approach using deep learning to detect and solve morphological analogies. It encodes structural properties of analogical proportions and relies on a specifically designed embedding model capturing morphological characteristics of words. We demonstrate our model's competitive performance on analogy detection and resolution over multiple languages. We provide an empirical study to analyze the impact of balancing training data and evaluate the robustness of our approach to input perturbation.
A Neural Approach for Detecting Morphological Analogies
Aug 09, 2021
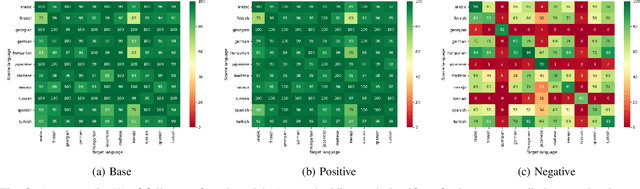
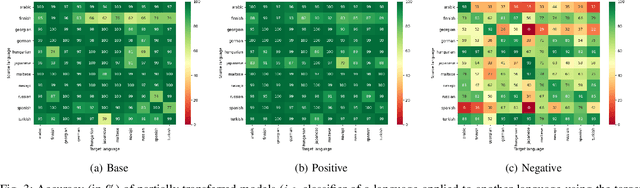
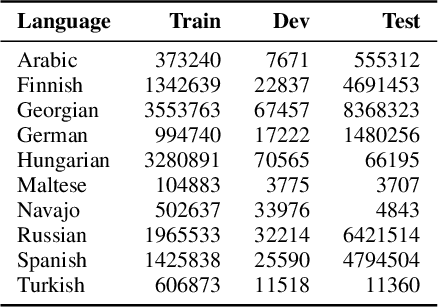
Analogical proportions are statements of the form "A is to B as C is to D" that are used for several reasoning and classification tasks in artificial intelligence and natural language processing (NLP). For instance, there are analogy based approaches to semantics as well as to morphology. In fact, symbolic approaches were developed to solve or to detect analogies between character strings, e.g., the axiomatic approach as well as that based on Kolmogorov complexity. In this paper, we propose a deep learning approach to detect morphological analogies, for instance, with reinflexion or conjugation. We present empirical results that show that our framework is competitive with the above-mentioned state of the art symbolic approaches. We also explore empirically its transferability capacity across languages, which highlights interesting similarities between them.
On the Transferability of Neural Models of Morphological Analogies
Aug 09, 2021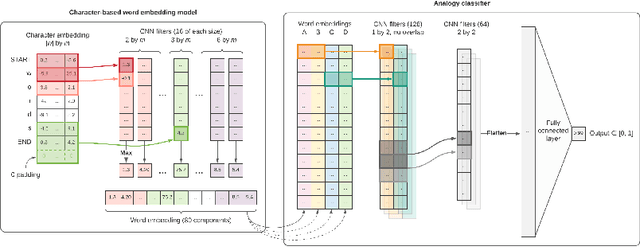
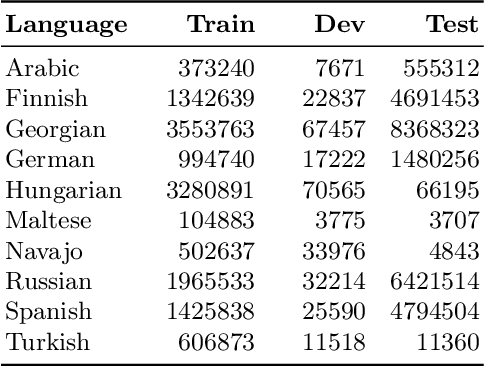
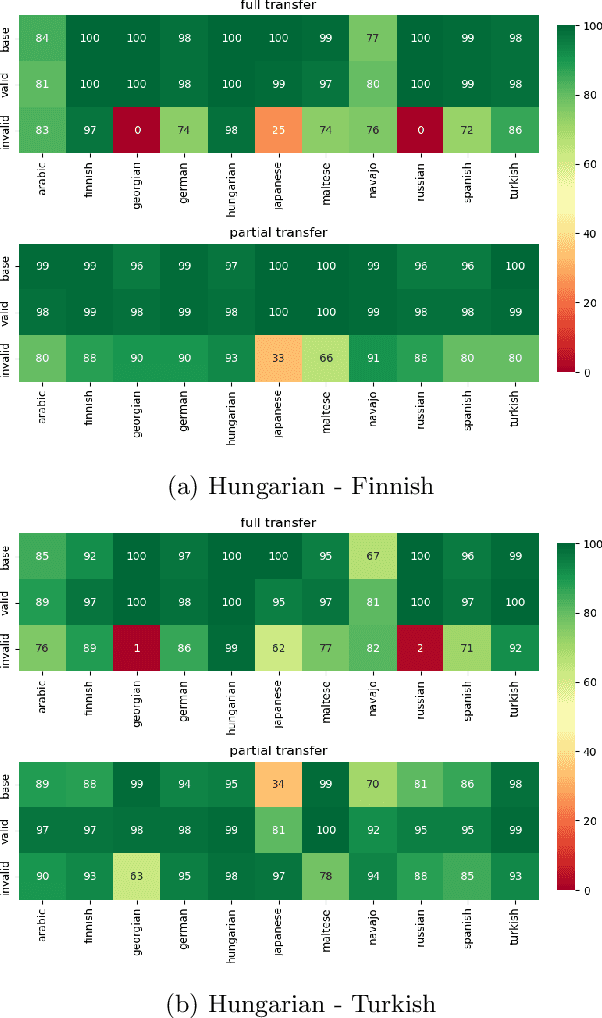
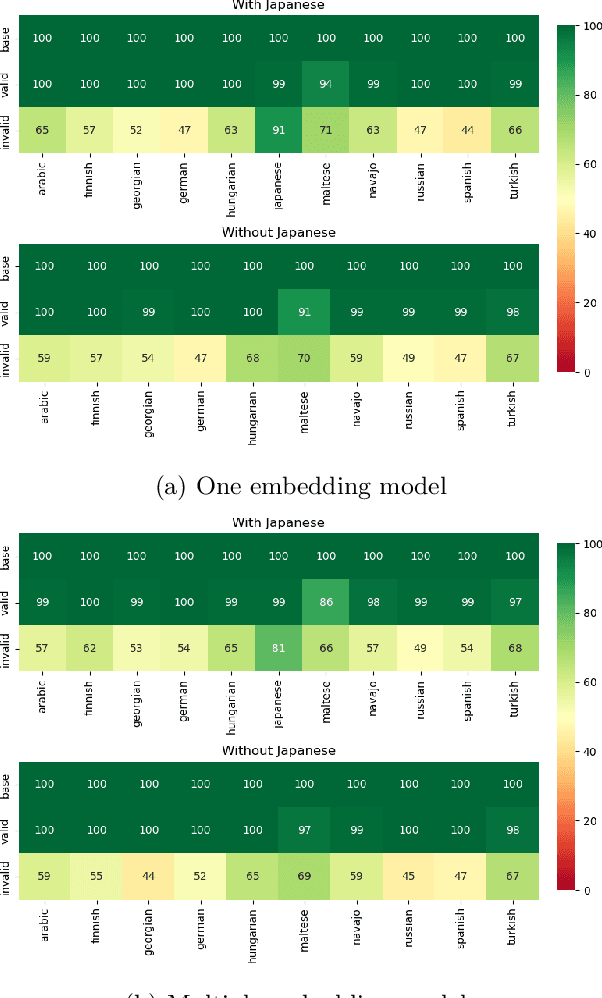
Analogical proportions are statements expressed in the form "A is to B as C is to D" and are used for several reasoning and classification tasks in artificial intelligence and natural language processing (NLP). In this paper, we focus on morphological tasks and we propose a deep learning approach to detect morphological analogies. We present an empirical study to see how our framework transfers across languages, and that highlights interesting similarities and differences between these languages. In view of these results, we also discuss the possibility of building a multilingual morphological model.
Exploring the Combination of Contextual Word Embeddings and Knowledge Graph Embeddings
Apr 17, 2020



``Classical'' word embeddings, such as Word2Vec, have been shown to capture the semantics of words based on their distributional properties. However, their ability to represent the different meanings that a word may have is limited. Such approaches also do not explicitly encode relations between entities, as denoted by words. Embeddings of knowledge bases (KB) capture the explicit relations between entities denoted by words, but are not able to directly capture the syntagmatic properties of these words. To our knowledge, recent research have focused on representation learning that augment the strengths of one with the other. In this work, we begin exploring another approach using contextual and KB embeddings jointly at the same level and propose two tasks -- an entity typing and a relation typing task -- that evaluate the performance of contextual and KB embeddings. We also evaluated a concatenated model of contextual and KB embeddings with these two tasks, and obtain conclusive results on the first task. We hope our work may contribute as a basis for models and datasets that develop in the direction of this approach.