 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Model Selection Using a Scalable and Size-Independent Complex Network Classifier
Feb 01, 2014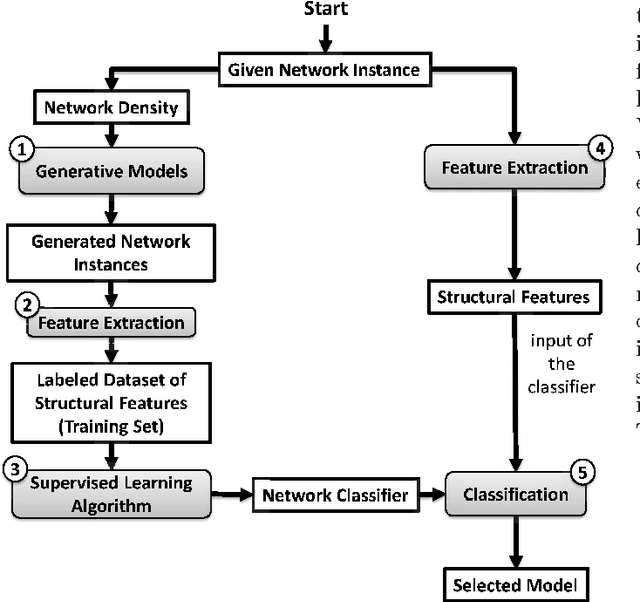

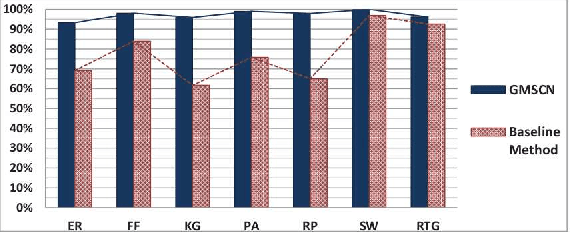
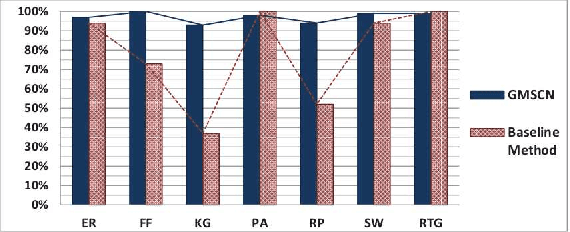
Real networks exhibit nontrivial topological features such as heavy-tailed degree distribution, high clustering, and small-worldness. Researchers have developed several generative models for synthesizing artificial networks that are structurally similar to real networks. An important research problem is to identify the generative model that best fits to a target network. In this paper, we investigate this problem and our goal is to select the model that is able to generate graphs similar to a given network instance. By the means of generating synthetic networks with seven outstanding generative models, we have utilized machine learning methods to develop a decision tree for model selection. Our proposed method, which is named "Generative Model Selection for Complex Networks" (GMSCN), outperforms existing methods with respect to accuracy, scalability and size-independence.
Learning an Integrated Distance Metric for Comparing Structure of Complex Networks
Jul 13, 2013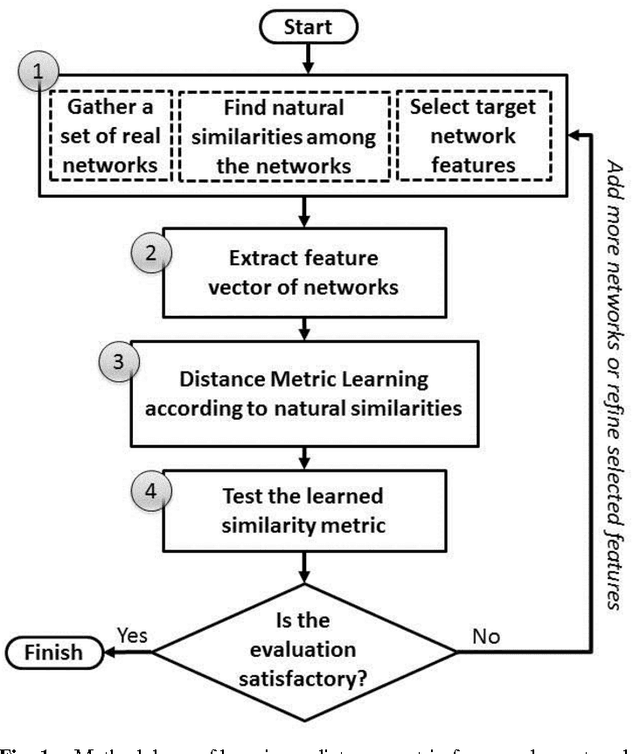
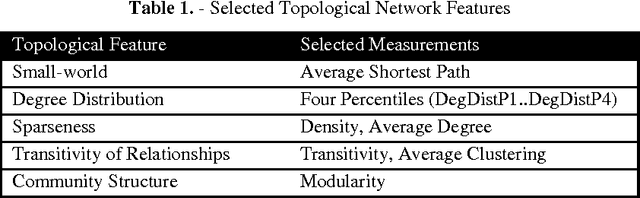
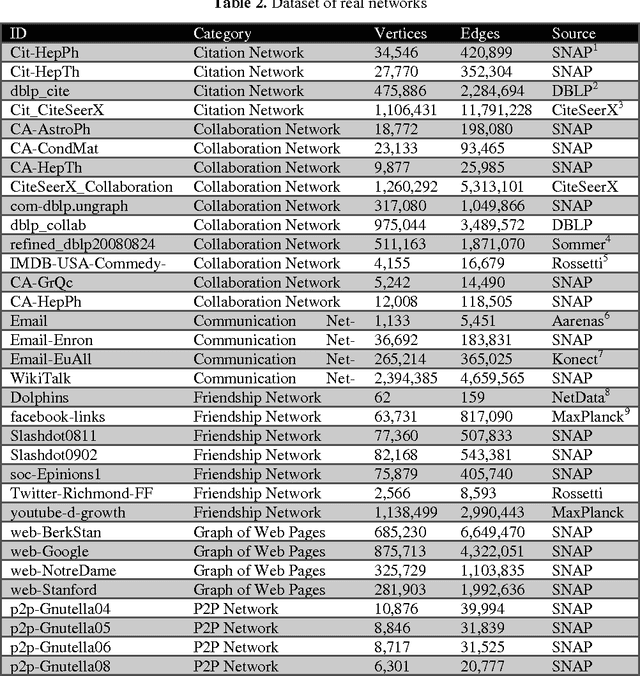
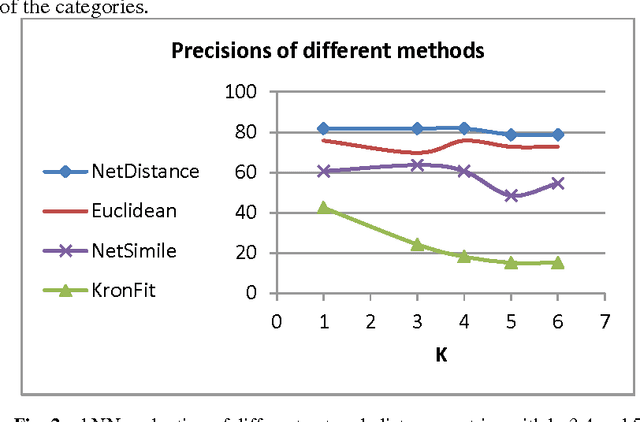
Graph comparison plays a major role in many network applications. We often need a similarity metric for comparing networks according to their structural properties. Various network features - such as degree distribution and clustering coefficient - provide measurements for comparing networks from different points of view, but a global and integrated distance metric is still missing. In this paper, we employ distance metric learning algorithms in order to construct an integrated distance metric for comparing structural properties of complex networks. According to natural witnesses of network similarities (such as network categories) the distance metric is learned by the means of a dataset of some labeled real networks. For evaluating our proposed method which is called NetDistance, we applied it as the distance metric in K-nearest-neighbors classification. Empirical results show that NetDistance outperforms previous methods, at least 20 percent, with respect to precision.