 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Evaluation and Anomaly Detection in Temporal Complex Networks using Deep Learning Methods
Jun 15, 2024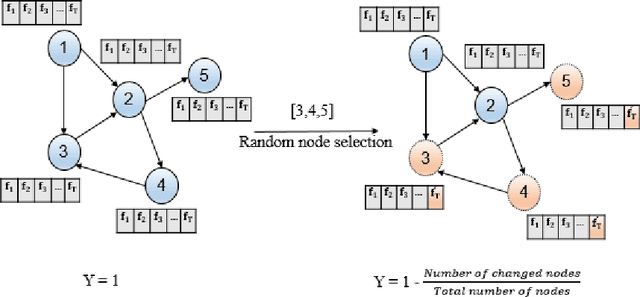
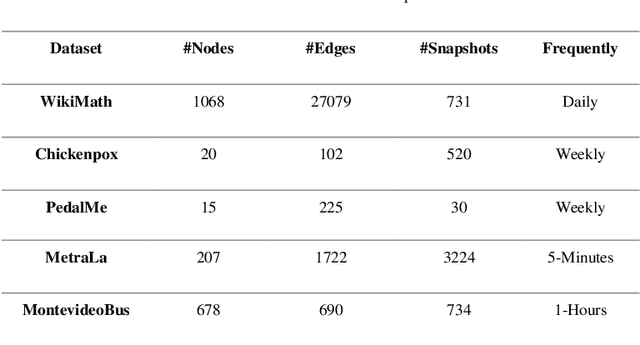
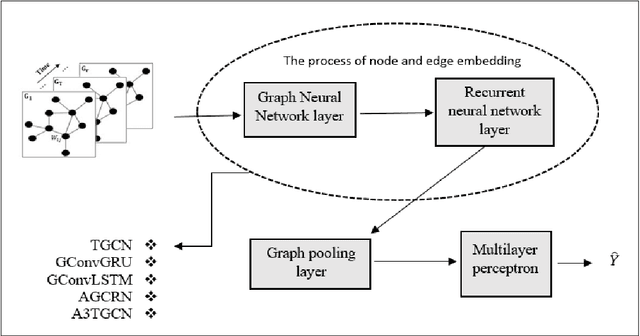
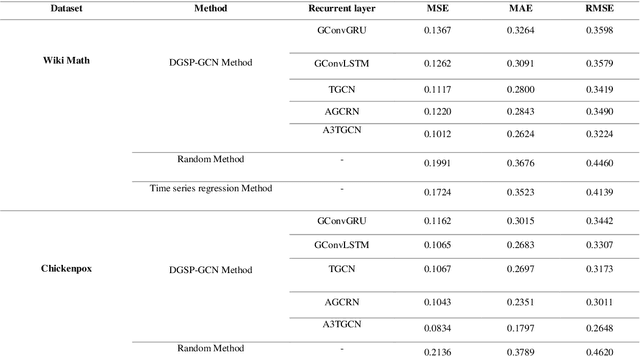
Modeling complex networks allows us to analyze the characteristics and discover the basic mechanisms governing phenomena such as disease outbreaks, information diffusion, transportation efficiency, social influence, and even human brain function. Consequently, various network generative models (called temporal network models) have been presented to model how the network topologies evolve dynamically over time. Temporal network models face the challenge of results evaluation because common evaluation methods are appropriate only for static networks. This paper proposes an automatic approach based on deep learning to handle this issue. In addition to an evaluation method, the proposed method can also be used for anomaly detection in evolving networks. The proposed method has been evaluated on five different datasets, and the evaluations show that it outperforms the alternative methods based on the error rate measure in different datasets.
NNCP: A citation count prediction methodology based on deep neural network learning techniques
Oct 19, 2018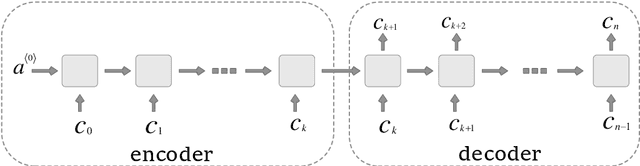
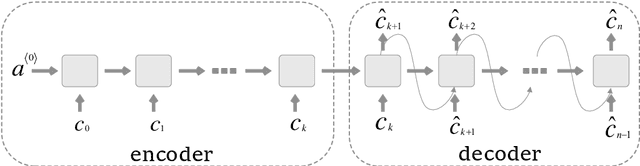
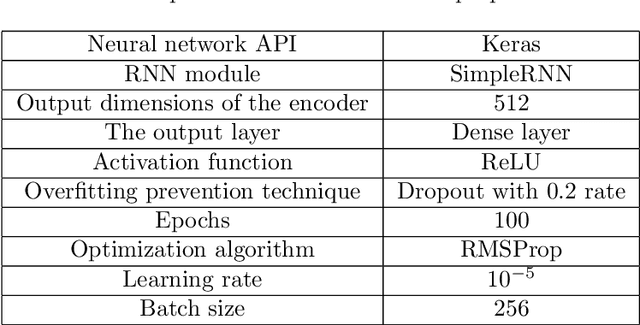
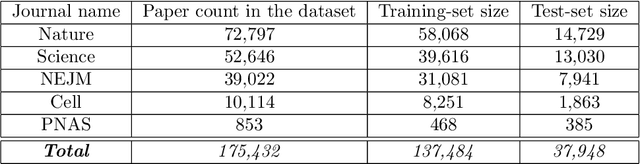
With the growing number of published scientific papers world-wide, the need to evaluation and quality assessment methods for research papers is increasing. Scientific fields such as scientometrics, informetrics and bibliometrics establish quantified analysis methods and measurements for scientific papers. In this area, an important problem is to predict the future influence of a published paper. Particularly, early discrimination between influential papers and insignificant papers may find important applications. In this regard, one of the most important metrics is the number of citations to the paper, since this metric is widely utilized in the evaluation of scientific publications and moreover, it serves as the basis for many other metrics such as h-index. In this paper, we propose a novel method for predicting long-term citations of a paper based on the number of its citations in the first few years after publication. In order to train a citations prediction model, we employed artificial neural networks which is a powerful machine learning tool with recently growing applications in many domains including image and text processing. The empirical experiments show that our proposed method out-performs state-of-the-art methods with respect to the prediction accuracy in both yearly and total prediction of the number of citations.
Towards quantitative methods to assess network generative models
Sep 05, 2018
Assessing generative models is not an easy task. Generative models should synthesize graphs which are not replicates of real networks but show topological features similar to real graphs. We introduce an approach for assessing graph generative models using graph classifiers. The inability of an established graph classifier for distinguishing real and synthesized graphs could be considered as a performance measurement for graph generators.
Generative Model Selection Using a Scalable and Size-Independent Complex Network Classifier
Feb 01, 2014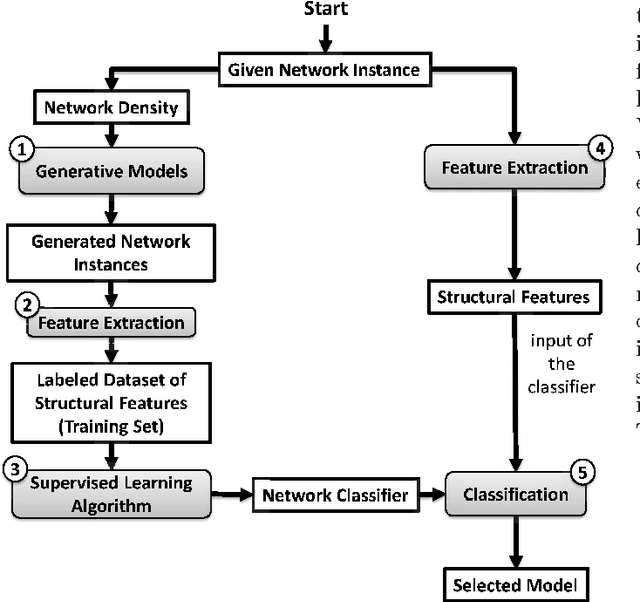

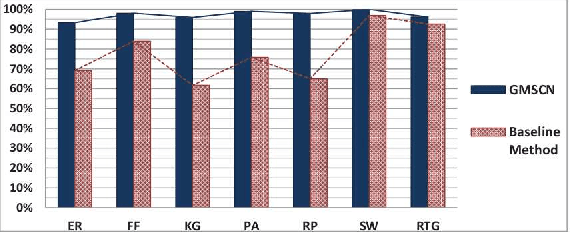
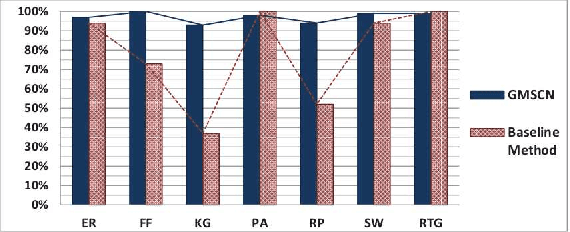
Real networks exhibit nontrivial topological features such as heavy-tailed degree distribution, high clustering, and small-worldness. Researchers have developed several generative models for synthesizing artificial networks that are structurally similar to real networks. An important research problem is to identify the generative model that best fits to a target network. In this paper, we investigate this problem and our goal is to select the model that is able to generate graphs similar to a given network instance. By the means of generating synthetic networks with seven outstanding generative models, we have utilized machine learning methods to develop a decision tree for model selection. Our proposed method, which is named "Generative Model Selection for Complex Networks" (GMSCN), outperforms existing methods with respect to accuracy, scalability and size-independence.
Learning an Integrated Distance Metric for Comparing Structure of Complex Networks
Jul 13, 2013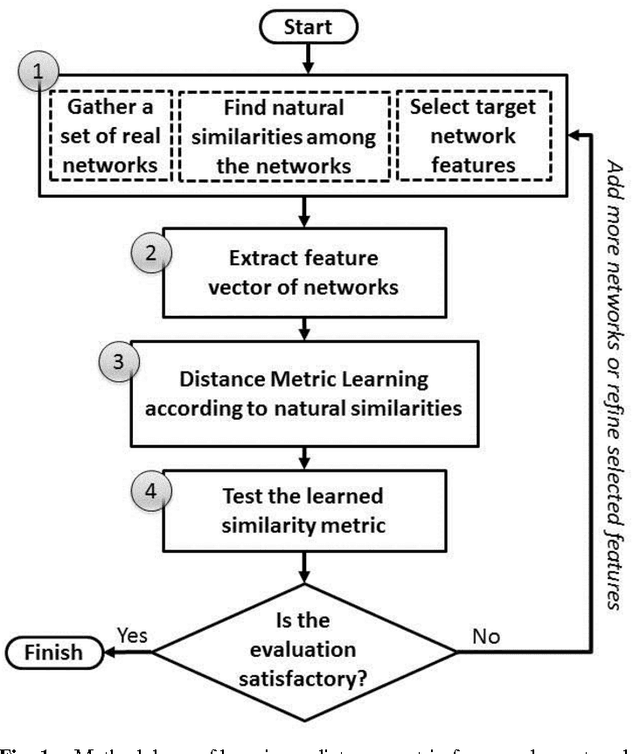
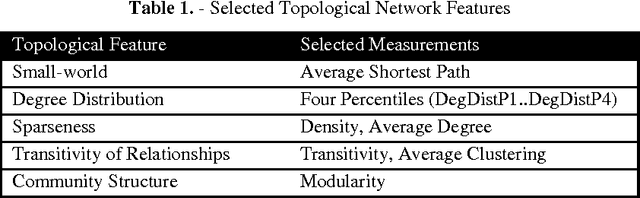
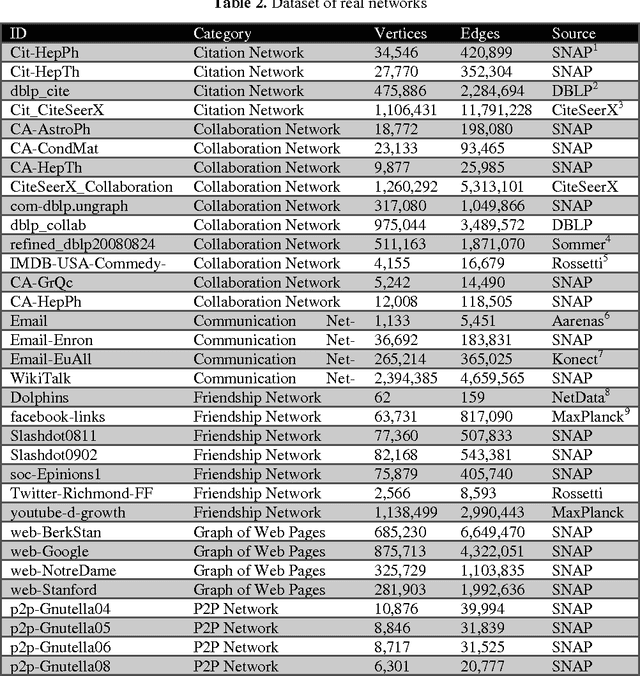
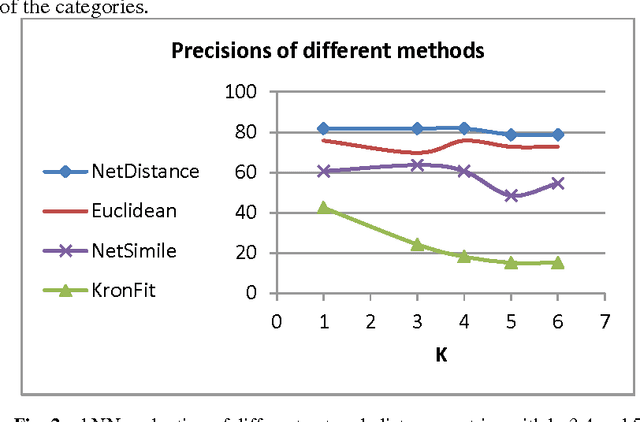
Graph comparison plays a major role in many network applications. We often need a similarity metric for comparing networks according to their structural properties. Various network features - such as degree distribution and clustering coefficient - provide measurements for comparing networks from different points of view, but a global and integrated distance metric is still missing. In this paper, we employ distance metric learning algorithms in order to construct an integrated distance metric for comparing structural properties of complex networks. According to natural witnesses of network similarities (such as network categories) the distance metric is learned by the means of a dataset of some labeled real networks. For evaluating our proposed method which is called NetDistance, we applied it as the distance metric in K-nearest-neighbors classification. Empirical results show that NetDistance outperforms previous methods, at least 20 percent, with respect to precision.