 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering of Urban Traffic Patterns by K-Means and Dynamic Time Warping: Case Study
Sep 18, 2023
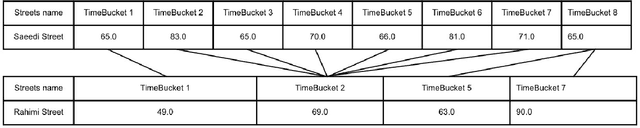

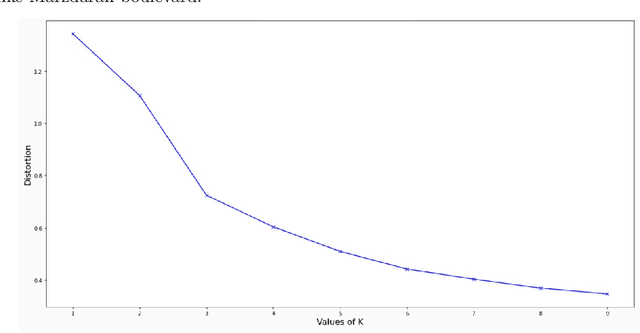
Clustering of urban traffic patterns is an essential task in many different areas of traffic management and planning. In this paper, two significant applications in the clustering of urban traffic patterns are described. The first application estimates the missing speed values using the speed of road segments with similar traffic patterns to colorify map tiles. The second one is the estimation of essential road segments for generating addresses for a local point on the map, using the similarity patterns of different road segments. The speed time series extracts the traffic pattern in different road segments. In this paper, we proposed the time series clustering algorithm based on K-Means and Dynamic Time Warping. The case study of our proposed algorithm is based on the Snapp application's driver speed time series data. The results of the two applications illustrate that the proposed method can extract similar urban traffic patterns.
Color Texture Image Retrieval Based on Copula Multivariate Modeling in the Shearlet Domain
Aug 03, 2020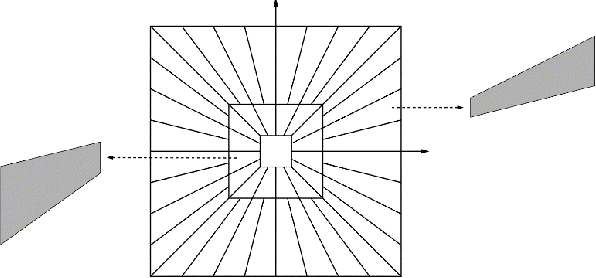
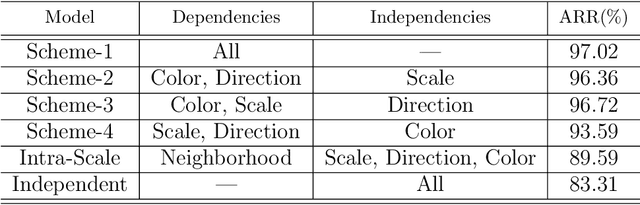
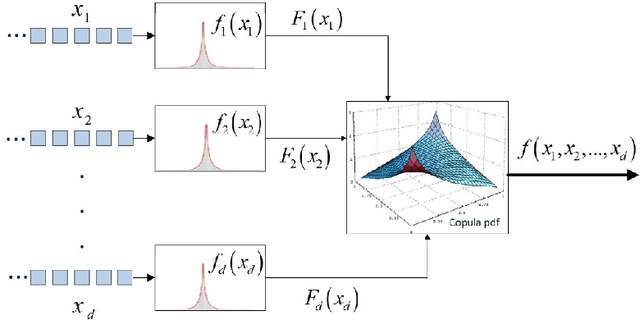
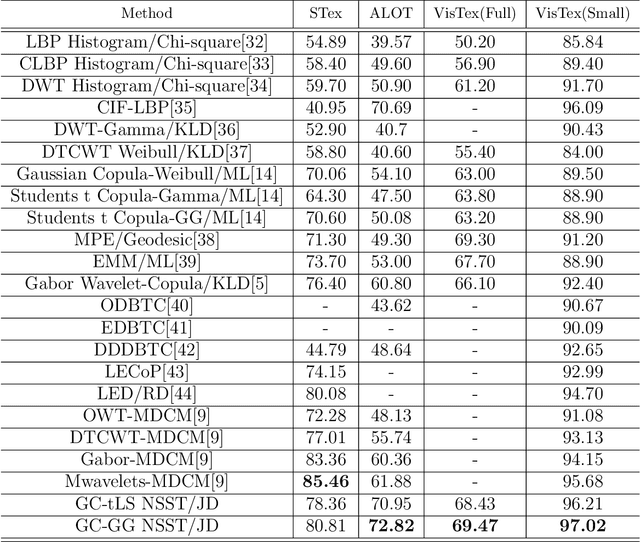
In this paper, a color texture image retrieval framework is proposed based on Shearlet domain modeling using Copula multivariate model. In the proposed framework, Gaussian Copula is used to model the dependencies between different sub-bands of the Non Subsample Shearlet Transform (NSST) and non-Gaussian models are used for marginal modeling of the coefficients. Six different schemes are proposed for modeling NSST coefficients based on the four types of neighboring defined; moreover, Kullback Leibler Divergence(KLD) close form is calculated in different situations for the two Gaussian Copula and non Gaussian functions in order to investigate the similarities in the proposed retrieval framework. The Jeffery divergence (JD) criterion, which is a symmetrical version of KLD, is used for investigating similarities in the proposed framework. We have implemented our experiments on four texture image retrieval benchmark datasets, the results of which show the superiority of the proposed framework over the existing state-of-the-art methods. In addition, the retrieval time of the proposed framework is also analyzed in the two steps of feature extraction and similarity matching, which also shows that the proposed framework enjoys an appropriate retrieval time.