 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifyViStA:WCE Classification with Visual understanding through Segmentation and Attention
Dec 24, 2024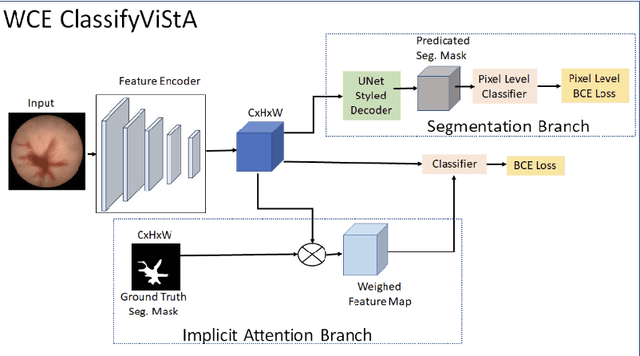
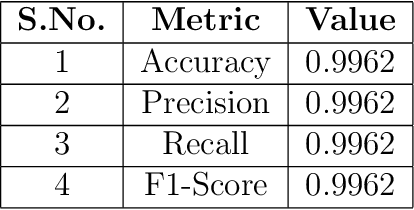

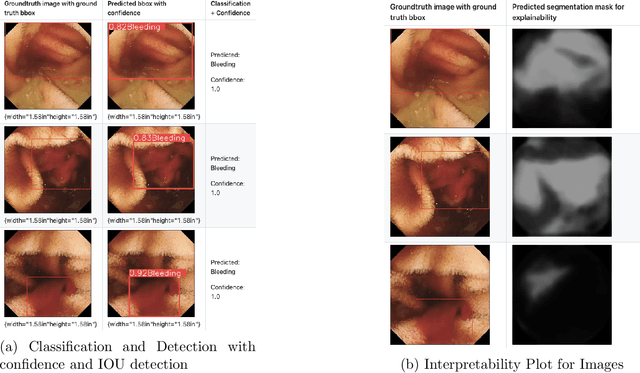
Gastrointestinal (GI) bleeding is a serious medical condition that presents significant diagnostic challenges, particularly in settings with limited access to healthcare resources. Wireless Capsule Endoscopy (WCE) has emerged as a powerful diagnostic tool for visualizing the GI tract, but it requires time-consuming manual analysis by experienced gastroenterologists, which is prone to human error and inefficient given the increasing number of patients.To address this challenge, we propose ClassifyViStA, an AI-based framework designed for the automated detection and classification of bleeding and non-bleeding frames from WCE videos. The model consists of a standard classification path, augmented by two specialized branches: an implicit attention branch and a segmentation branch.The attention branch focuses on the bleeding regions, while the segmentation branch generates accurate segmentation masks, which are used for classification and interpretability. The model is built upon an ensemble of ResNet18 and VGG16 architectures to enhance classification performance. For the bleeding region detection, we implement a Soft Non-Maximum Suppression (Soft NMS) approach with YOLOv8, which improves the handling of overlapping bounding boxes, resulting in more accurate and nuanced detections.The system's interpretability is enhanced by using the segmentation masks to explain the classification results, offering insights into the decision-making process similar to the way a gastroenterologist identifies bleeding regions. Our approach not only automates the detection of GI bleeding but also provides an interpretable solution that can ease the burden on healthcare professionals and improve diagnostic efficiency. Our code is available at ClassifyViStA.
Can you even tell left from right? Presenting a new challenge for VQA
Mar 15, 2022
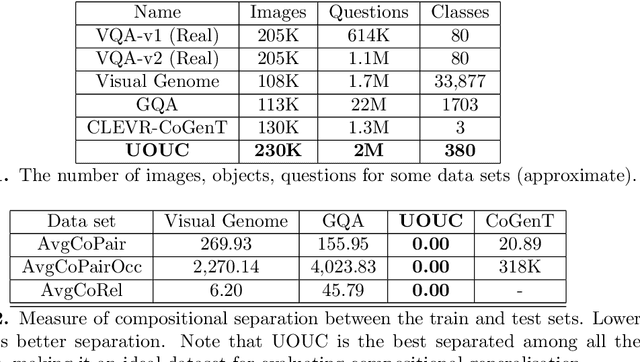
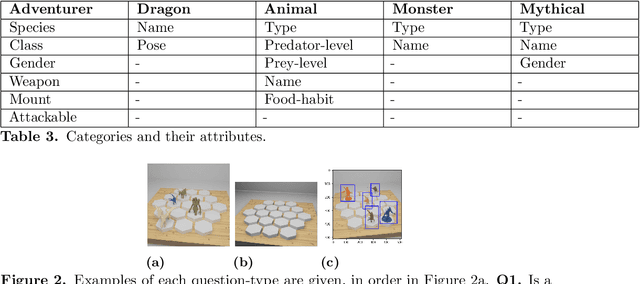
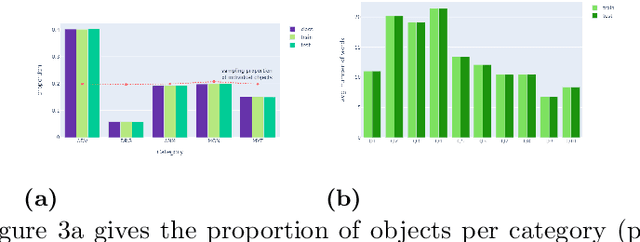
Visual Question Answering (VQA) needs a means of evaluating the strengths and weaknesses of models. One aspect of such an evaluation is the evaluation of compositional generalisation, or the ability of a model to answer well on scenes whose scene-setups are different from the training set. Therefore, for this purpose, we need datasets whose train and test sets differ significantly in composition. In this work, we present several quantitative measures of compositional separation and find that popular datasets for VQA are not good evaluators. To solve this, we present Uncommon Objects in Unseen Configurations (UOUC), a synthetic dataset for VQA. UOUC is at once fairly complex while also being well-separated, compositionally. The object-class of UOUC consists of 380 clasess taken from 528 characters from the Dungeons and Dragons game. The train set of UOUC consists of 200,000 scenes; whereas the test set consists of 30,000 scenes. In order to study compositional generalisation, simple reasoning and memorisation, each scene of UOUC is annotated with up to 10 novel questions. These deal with spatial relationships, hypothetical changes to scenes, counting, comparison, memorisation and memory-based reasoning. In total, UOUC presents over 2 million questions. UOUC also finds itself as a strong challenge to well-performing models for VQA. Our evaluation of recent models for VQA shows poor compositional generalisation, and comparatively lower ability towards simple reasoning. These results suggest that UOUC could lead to advances in research by being a strong benchmark for VQA.
Consensual Collaborative Training And Knowledge Distillation Based Facial Expression Recognition Under Noisy Annotations
Jul 10, 2021
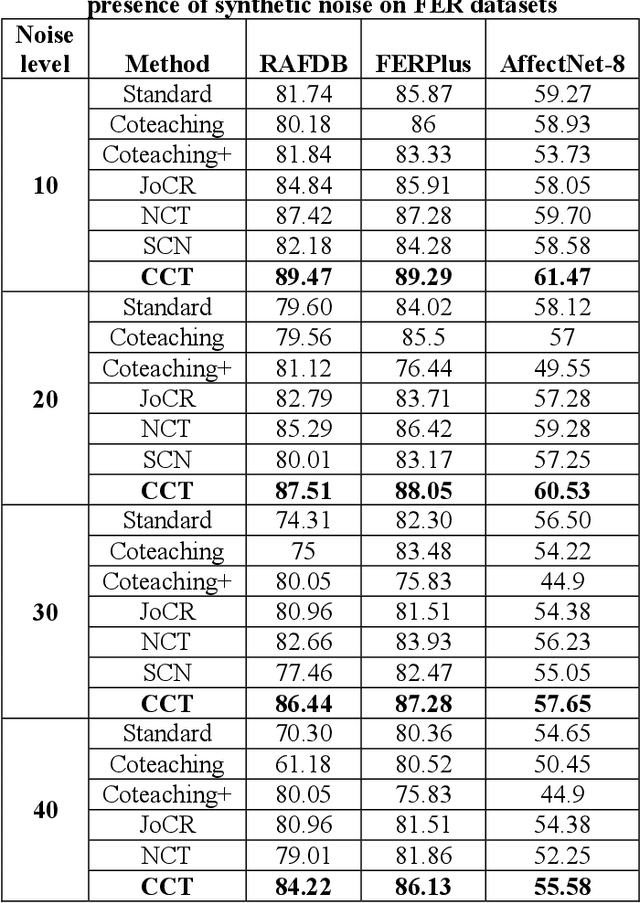

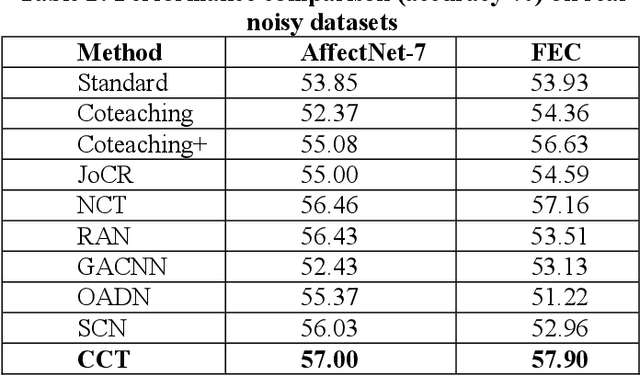
Presence of noise in the labels of large scale facial expression datasets has been a key challenge towards Facial Expression Recognition (FER) in the wild. During early learning stage, deep networks fit on clean data. Then, eventually, they start overfitting on noisy labels due to their memorization ability, which limits FER performance. This work proposes an effective training strategy in the presence of noisy labels, called as Consensual Collaborative Training (CCT) framework. CCT co-trains three networks jointly using a convex combination of supervision loss and consistency loss, without making any assumption about the noise distribution. A dynamic transition mechanism is used to move from supervision loss in early learning to consistency loss for consensus of predictions among networks in the later stage. Inference is done using a single network based on a simple knowledge distillation scheme. Effectiveness of the proposed framework is demonstrated on synthetic as well as real noisy FER datasets. In addition, a large test subset of around 5K images is annotated from the FEC dataset using crowd wisdom of 16 different annotators and reliable labels are inferred. CCT is also validated on it. State-of-the-art performance is reported on the benchmark FER datasets RAFDB (90.84%) FERPlus (89.99%) and AffectNet (66%). Our codes are available at https://github.com/1980x/CCT.
* 11 pages, 6 figures, Published with International Journal of Engineering Trends and Technology (IJETT), Codes: https://github.com/1980x/CCT
Imponderous Net for Facial Expression Recognition in the Wild
Mar 28, 2021

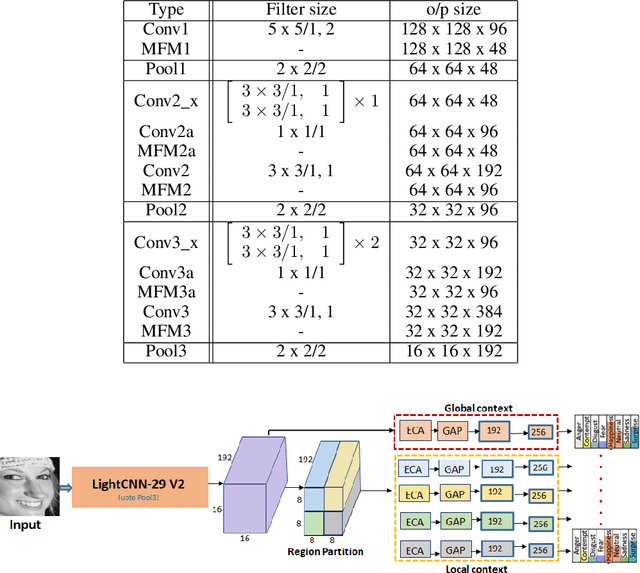

Since the renaissance of deep learning (DL), facial expression recognition (FER) has received a lot of interest, with continual improvement in the performance. Hand-in-hand with performance, new challenges have come up. Modern FER systems deal with face images captured under uncontrolled conditions (also called in-the-wild scenario) including occlusions and pose variations. They successfully handle such conditions using deep networks that come with various components like transfer learning, attention mechanism and local-global context extractor. However, these deep networks are highly complex with large number of parameters, making them unfit to be deployed in real scenarios. Is it possible to build a light-weight network that can still show significantly good performance on FER under in-the-wild scenario? In this work, we methodically build such a network and call it as Imponderous Net. We leverage on the aforementioned components of deep networks for FER, and analyse, carefully choose and fit them to arrive at Imponderous Net. Our Imponderous Net is a low calorie net with only 1.45M parameters, which is almost 50x less than that of a state-of-the-art (SOTA) architecture. Further, during inference, it can process at the real time rate of 40 frames per second (fps) in an intel-i7 cpu. Though it is low calorie, it is still power packed in its performance, overpowering other light-weight architectures and even few high capacity architectures. Specifically, Imponderous Net reports 87.09\%, 88.17\% and 62.06\% accuracies on in-the-wild datasets RAFDB, FERPlus and AffectNet respectively. It also exhibits superior robustness under occlusions and pose variations in comparison to other light-weight architectures from the literature.
Learning Compositional Structures for Deep Learning: Why Routing-by-agreement is Necessary
Oct 06, 2020
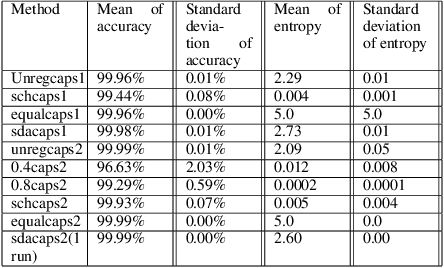

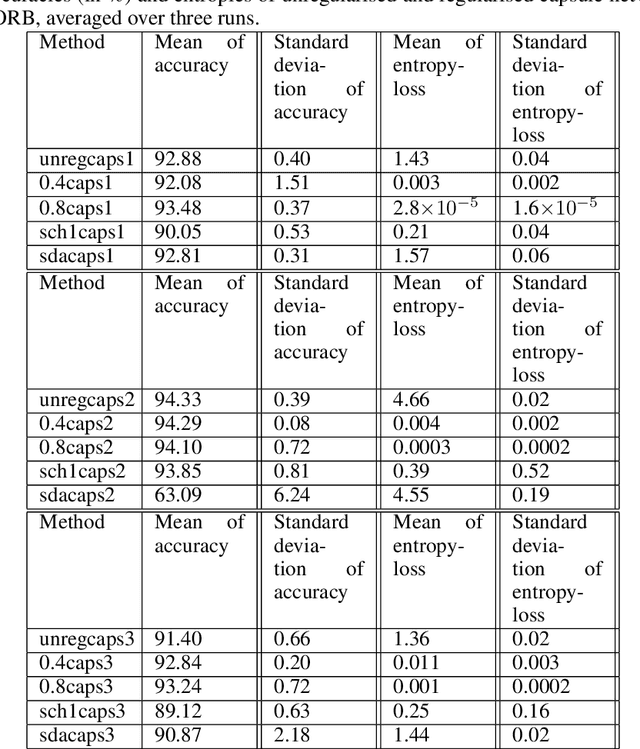
A formal description of the compositionality of neural networks is associated directly with the formal grammar-structure of the objects it seeks to represent. This formal grammar-structure specifies the kind of components that make up an object, and also the configurations they are allowed to be in. In other words, objects can be described as a parse-tree of its components -- a structure that can be seen as a candidate for building connection-patterns among neurons in neural networks. We present a formal grammar description of convolutional neural networks and capsule networks that shows how capsule networks can enforce such parse-tree structures, while CNNs do not. Specifically, we show that the entropy of routing coefficients in the dynamic routing algorithm controls this ability. Thus, we introduce the entropy of routing weights as a loss function for better compositionality among capsules. We show by experiments, on data with a compositional structure, that the use of this loss enables capsule networks to better detect changes in compositionality. Our experiments show that as the entropy of the routing weights increases, the ability to detect changes in compositionality reduces. We see that, without routing, capsule networks perform similar to convolutional neural networks in that both these models perform badly at detecting changes in compositionality. Our results indicate that routing is an important part of capsule networks -- effectively answering recent work that has questioned its necessity. We also, by experiments on SmallNORB, CIFAR-10, and FashionMNIST, show that this loss keeps the accuracy of capsule network models comparable to models that do not use it .
Building Deep, Equivariant Capsule Networks
Aug 04, 2019Capsule networks are constrained by their, relative, inability to deeper in a parameter-inexpensive manner, and also by the general lack of equivariance guarantees. As a step towards bridging these two gaps, we present a new variation of capsule networks termed Space-of-Variation networks (SOVNET). Each layer in SOVNET learns to projectively represent the manifold of legal pose variations for a set of capsules, using learnable neural network - one per capsule-type. Thus, shallower capsules from a local pool predict a deeper capsule by being input into the neural network associated with the type of deeper capsule. In order to capture local object-structures better, benefit from increased parameter-sharing, and have equivariance guarantees; group-equivariant convolutions are used in the prediction mechanism. Further, a new routing algorithm based on the degree-centrality of graph nodes is presented. Experiments on affinely transformed versions of MNIST and FashionMNIST showcase the superiority of SOVNET over certain capsule-network baselines.
A Deep Neural Network for Pixel-Level Electromagnetic Particle Identification in the MicroBooNE Liquid Argon Time Projection Chamber
Aug 22, 2018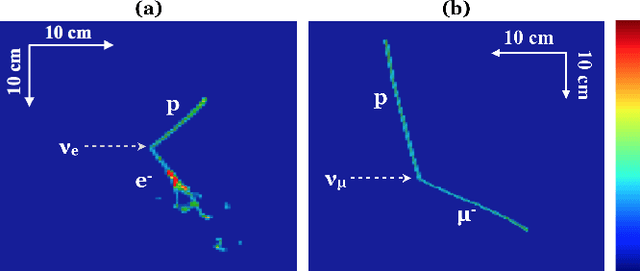
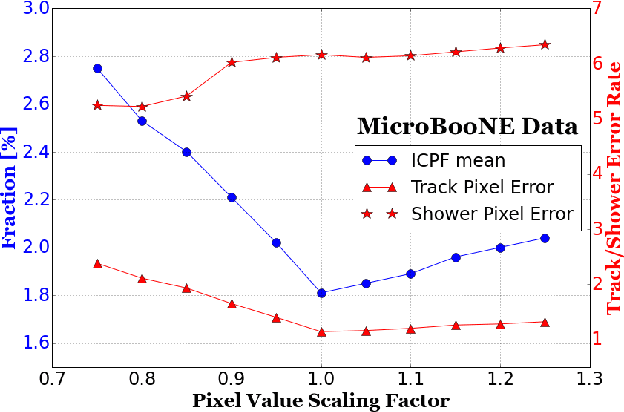
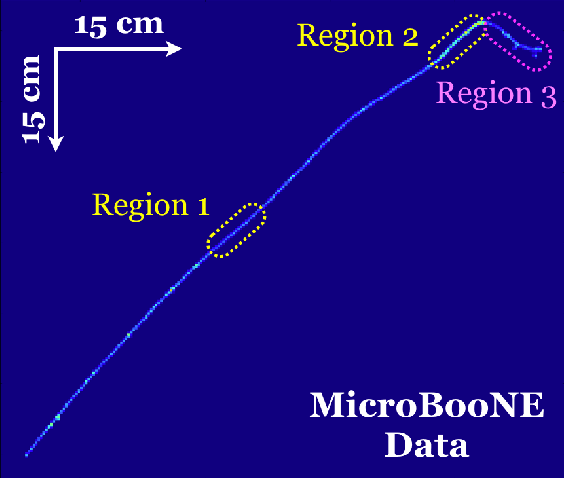
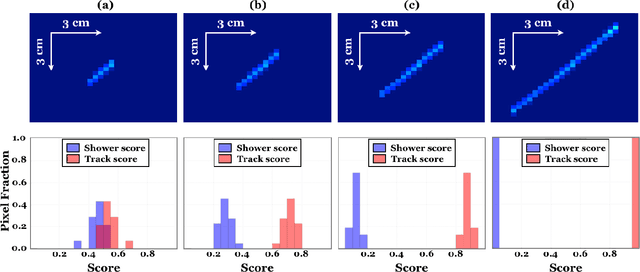
We have developed a convolutional neural network (CNN) that can make a pixel-level prediction of objects in image data recorded by a liquid argon time projection chamber (LArTPC) for the first time. We describe the network design, training techniques, and software tools developed to train this network. The goal of this work is to develop a complete deep neural network based data reconstruction chain for the MicroBooNE detector. We show the first demonstration of a network's validity on real LArTPC data using MicroBooNE collection plane images. The demonstration is performed for stopping muon and a $\nu_\mu$ charged current neutral pion data samples.