 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan you even tell left from right? Presenting a new challenge for VQA
Mar 15, 2022
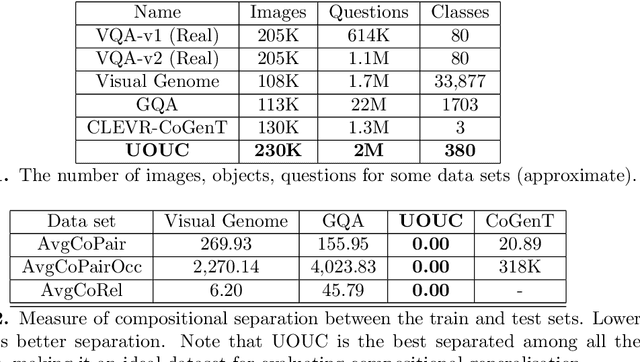
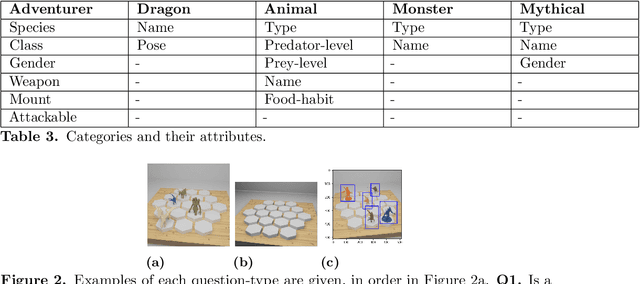
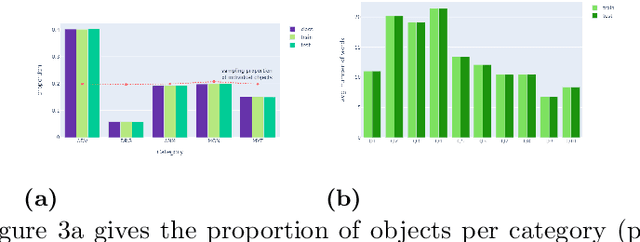
Visual Question Answering (VQA) needs a means of evaluating the strengths and weaknesses of models. One aspect of such an evaluation is the evaluation of compositional generalisation, or the ability of a model to answer well on scenes whose scene-setups are different from the training set. Therefore, for this purpose, we need datasets whose train and test sets differ significantly in composition. In this work, we present several quantitative measures of compositional separation and find that popular datasets for VQA are not good evaluators. To solve this, we present Uncommon Objects in Unseen Configurations (UOUC), a synthetic dataset for VQA. UOUC is at once fairly complex while also being well-separated, compositionally. The object-class of UOUC consists of 380 clasess taken from 528 characters from the Dungeons and Dragons game. The train set of UOUC consists of 200,000 scenes; whereas the test set consists of 30,000 scenes. In order to study compositional generalisation, simple reasoning and memorisation, each scene of UOUC is annotated with up to 10 novel questions. These deal with spatial relationships, hypothetical changes to scenes, counting, comparison, memorisation and memory-based reasoning. In total, UOUC presents over 2 million questions. UOUC also finds itself as a strong challenge to well-performing models for VQA. Our evaluation of recent models for VQA shows poor compositional generalisation, and comparatively lower ability towards simple reasoning. These results suggest that UOUC could lead to advances in research by being a strong benchmark for VQA.
Learning Compositional Structures for Deep Learning: Why Routing-by-agreement is Necessary
Oct 06, 2020
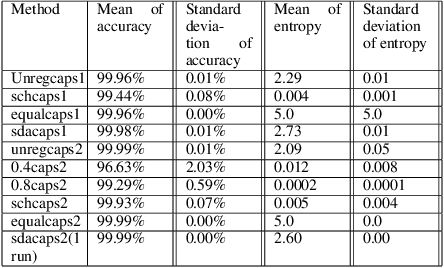

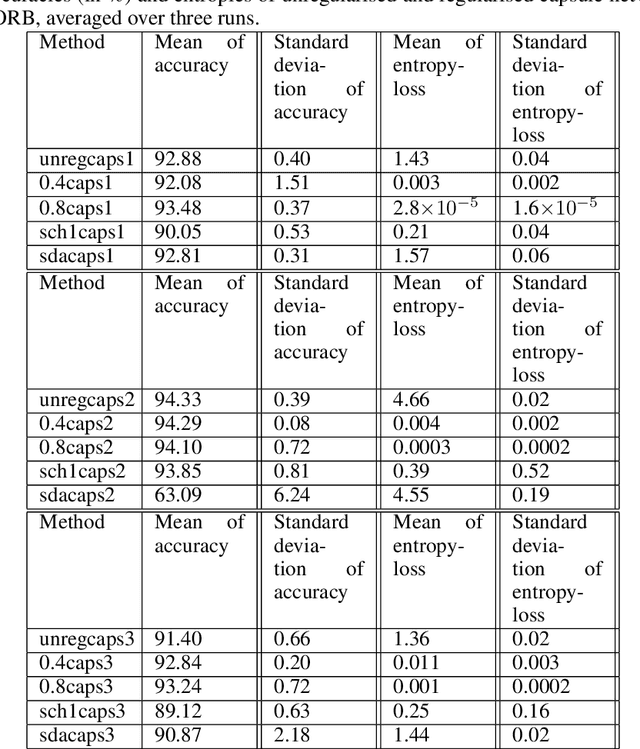
A formal description of the compositionality of neural networks is associated directly with the formal grammar-structure of the objects it seeks to represent. This formal grammar-structure specifies the kind of components that make up an object, and also the configurations they are allowed to be in. In other words, objects can be described as a parse-tree of its components -- a structure that can be seen as a candidate for building connection-patterns among neurons in neural networks. We present a formal grammar description of convolutional neural networks and capsule networks that shows how capsule networks can enforce such parse-tree structures, while CNNs do not. Specifically, we show that the entropy of routing coefficients in the dynamic routing algorithm controls this ability. Thus, we introduce the entropy of routing weights as a loss function for better compositionality among capsules. We show by experiments, on data with a compositional structure, that the use of this loss enables capsule networks to better detect changes in compositionality. Our experiments show that as the entropy of the routing weights increases, the ability to detect changes in compositionality reduces. We see that, without routing, capsule networks perform similar to convolutional neural networks in that both these models perform badly at detecting changes in compositionality. Our results indicate that routing is an important part of capsule networks -- effectively answering recent work that has questioned its necessity. We also, by experiments on SmallNORB, CIFAR-10, and FashionMNIST, show that this loss keeps the accuracy of capsule network models comparable to models that do not use it .