 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Goal Spaces for Intrinsically Motivated Goal Exploration
Oct 09, 2018

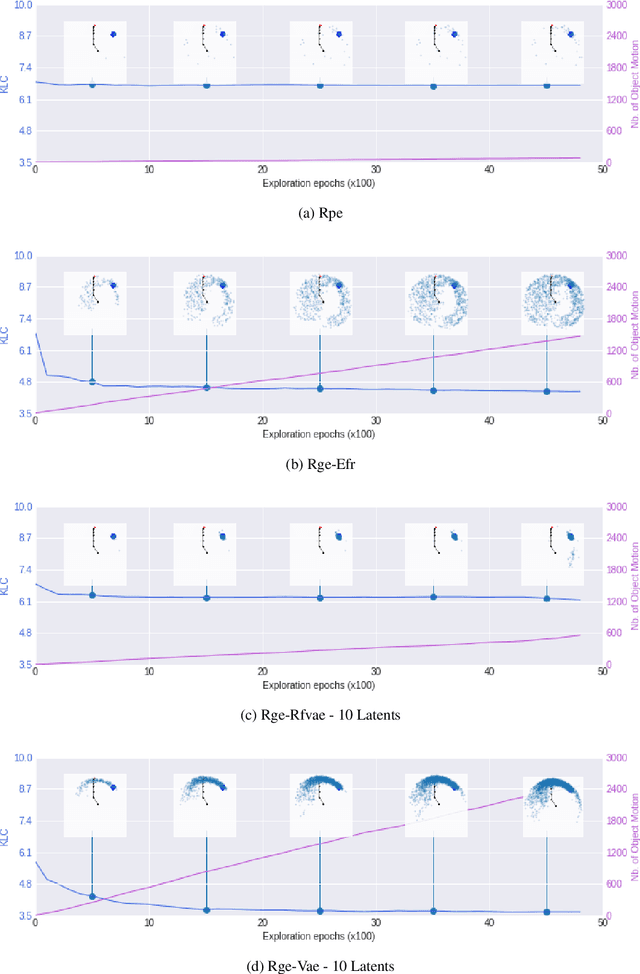
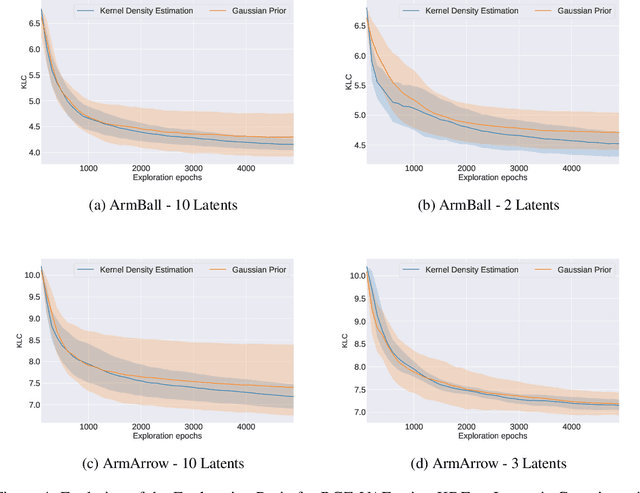
Intrinsically motivated goal exploration algorithms enable machines to discover repertoires of policies that produce a diversity of effects in complex environments. These exploration algorithms have been shown to allow real world robots to acquire skills such as tool use in high-dimensional continuous state and action spaces. However, they have so far assumed that self-generated goals are sampled in a specifically engineered feature space, limiting their autonomy. In this work, we propose to use deep representation learning algorithms to learn an adequate goal space. This is a developmental 2-stage approach: first, in a perceptual learning stage, deep learning algorithms use passive raw sensor observations of world changes to learn a corresponding latent space; then goal exploration happens in a second stage by sampling goals in this latent space. We present experiments where a simulated robot arm interacts with an object, and we show that exploration algorithms using such learned representations can match the performance obtained using engineered representations.
Intrinsically Motivated Goal Exploration Processes with Automatic Curriculum Learning
Aug 07, 2017



Intrinsically motivated spontaneous exploration is a key enabler of autonomous lifelong learning in human children. It allows them to discover and acquire large repertoires of skills through self-generation, self-selection, self-ordering and self-experimentation of learning goals. We present the unsupervised multi-goal reinforcement learning formal framework as well as an algorithmic approach called intrinsically motivated goal exploration processes (IMGEP) to enable similar properties of autonomous learning in machines. The IMGEP algorithmic architecture relies on several principles: 1) self-generation of goals as parameterized reinforcement learning problems; 2) selection of goals based on intrinsic rewards; 3) exploration with parameterized time-bounded policies and fast incremental goal-parameterized policy search; 4) systematic reuse of information acquired when targeting a goal for improving other goals. We present a particularly efficient form of IMGEP that uses a modular representation of goal spaces as well as intrinsic rewards based on learning progress. We show how IMGEPs automatically generate a learning curriculum within an experimental setup where a real humanoid robot can explore multiple spaces of goals with several hundred continuous dimensions. While no particular target goal is provided to the system beforehand, this curriculum allows the discovery of skills of increasing complexity, that act as stepping stone for learning more complex skills (like nested tool use). We show that learning several spaces of diverse problems can be more efficient for learning complex skills than only trying to directly learn these complex skills. We illustrate the computational efficiency of IMGEPs as these robotic experiments use a simple memory-based low-level policy representations and search algorithm, enabling the whole system to learn online and incrementally on a Raspberry Pi 3.