 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2IL: Structurally Stable Incremental Learning
Mar 15, 2025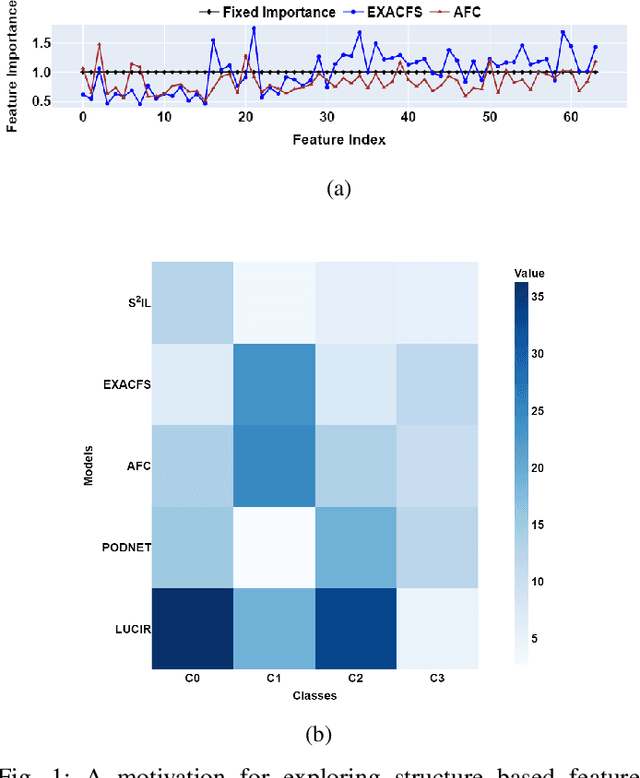
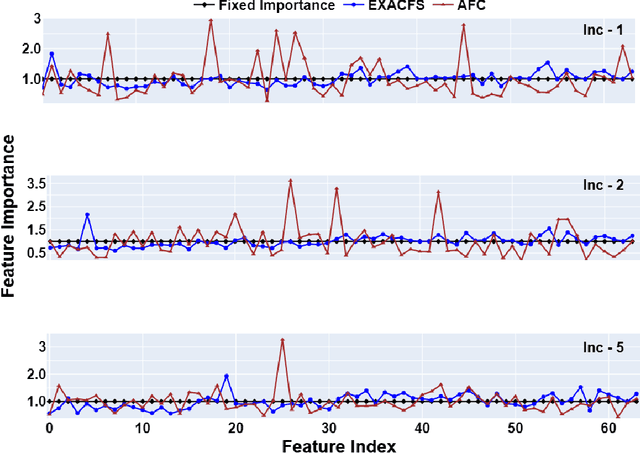
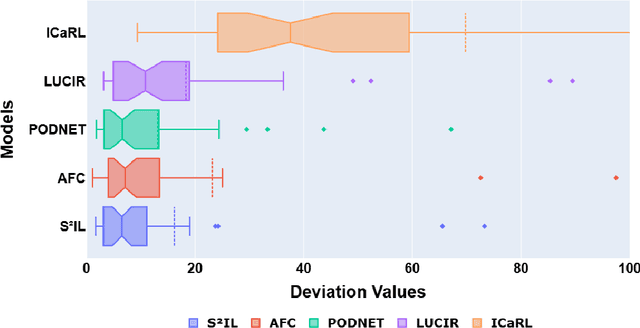
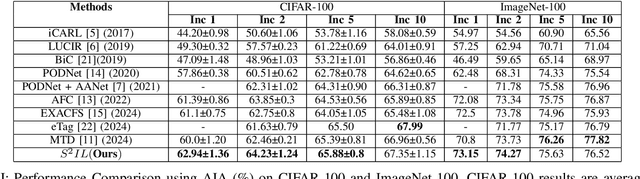
Feature Distillation (FD) strategies are proven to be effective in mitigating Catastrophic Forgetting (CF) seen in Class Incremental Learning (CIL). However, current FD approaches enforce strict alignment of feature magnitudes and directions across incremental steps, limiting the model's ability to adapt to new knowledge. In this paper we propose Structurally Stable Incremental Learning(S22IL), a FD method for CIL that mitigates CF by focusing on preserving the overall spatial patterns of features which promote flexible (plasticity) yet stable representations that preserve old knowledge (stability). We also demonstrate that our proposed method S2IL achieves strong incremental accuracy and outperforms other FD methods on SOTA benchmark datasets CIFAR-100, ImageNet-100 and ImageNet-1K. Notably, S2IL outperforms other methods by a significant margin in scenarios that have a large number of incremental tasks.
EXACFS -- A CIL Method to mitigate Catastrophic Forgetting
Oct 31, 2024

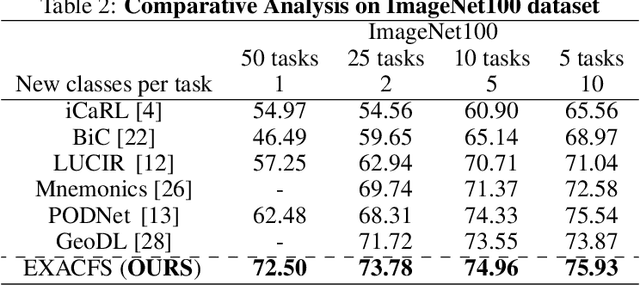
Deep neural networks (DNNS) excel at learning from static datasets but struggle with continual learning, where data arrives sequentially. Catastrophic forgetting, the phenomenon of forgetting previously learned knowledge, is a primary challenge. This paper introduces EXponentially Averaged Class-wise Feature Significance (EXACFS) to mitigate this issue in the class incremental learning (CIL) setting. By estimating the significance of model features for each learned class using loss gradients, gradually aging the significance through the incremental tasks and preserving the significant features through a distillation loss, EXACFS effectively balances remembering old knowledge (stability) and learning new knowledge (plasticity). Extensive experiments on CIFAR-100 and ImageNet-100 demonstrate EXACFS's superior performance in preserving stability while acquiring plasticity.
Class adaptive threshold and negative class guided noisy annotation robust Facial Expression Recognition
May 03, 2023



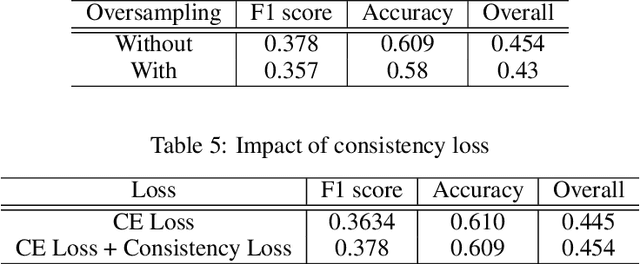
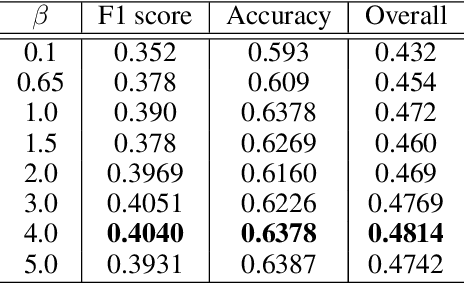
The hindering problem in facial expression recognition (FER) is the presence of inaccurate annotations referred to as noisy annotations in the datasets. These noisy annotations are present in the datasets inherently because the labeling is subjective to the annotator, clarity of the image, etc. Recent works use sample selection methods to solve this noisy annotation problem in FER. In our work, we use a dynamic adaptive threshold to separate confident samples from non-confident ones so that our learning won't be hampered due to non-confident samples. Instead of discarding the non-confident samples, we impose consistency in the negative classes of those non-confident samples to guide the model to learn better in the positive class. Since FER datasets usually come with 7 or 8 classes, we can correctly guess a negative class by 85% probability even by choosing randomly. By learning "which class a sample doesn't belong to", the model can learn "which class it belongs to" in a better manner. We demonstrate proposed framework's effectiveness using quantitative as well as qualitative results. Our method performs better than the baseline by a margin of 4% to 28% on RAFDB and 3.3% to 31.4% on FERPlus for various levels of synthetic noisy labels in the aforementioned datasets.
ABAW : Facial Expression Recognition in the wild
Mar 17, 2023The fifth Affective Behavior Analysis in-the-wild (ABAW) competition has multiple challenges such as Valence-Arousal Estimation Challenge, Expression Classification Challenge, Action Unit Detection Challenge, Emotional Reaction Intensity Estimation Challenge. In this paper we have dealt only expression classification challenge using multiple approaches such as fully supervised, semi-supervised and noisy label approach. Our approach using noise aware model has performed better than baseline model by 10.46% and semi supervised model has performed better than baseline model by 9.38% and the fully supervised model has performed better than the baseline by 9.34%
Dynamic Adaptive Threshold based Learning for Noisy Annotations Robust Facial Expression Recognition
Aug 22, 2022
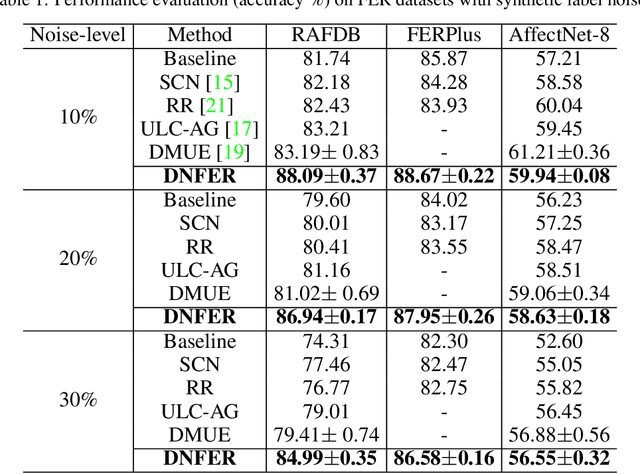
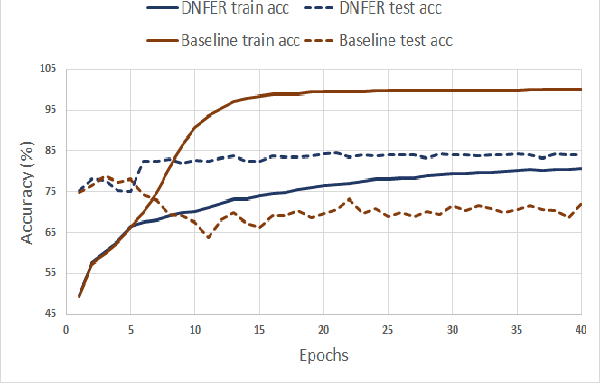
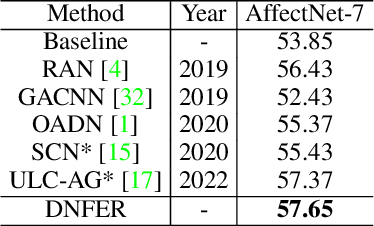
The real-world facial expression recognition (FER) datasets suffer from noisy annotations due to crowd-sourcing, ambiguity in expressions, the subjectivity of annotators and inter-class similarity. However, the recent deep networks have strong capacity to memorize the noisy annotations leading to corrupted feature embedding and poor generalization. To handle noisy annotations, we propose a dynamic FER learning framework (DNFER) in which clean samples are selected based on dynamic class specific threshold during training. Specifically, DNFER is based on supervised training using selected clean samples and unsupervised consistent training using all the samples. During training, the mean posterior class probabilities of each mini-batch is used as dynamic class-specific threshold to select the clean samples for supervised training. This threshold is independent of noise rate and does not need any clean data unlike other methods. In addition, to learn from all samples, the posterior distributions between weakly-augmented image and strongly-augmented image are aligned using an unsupervised consistency loss. We demonstrate the robustness of DNFER on both synthetic as well as on real noisy annotated FER datasets like RAFDB, FERPlus, SFEW and AffectNet.
SS-MFAR : Semi-supervised Multi-task Facial Affect Recognition
Jul 19, 2022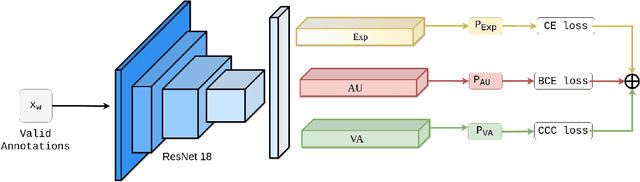
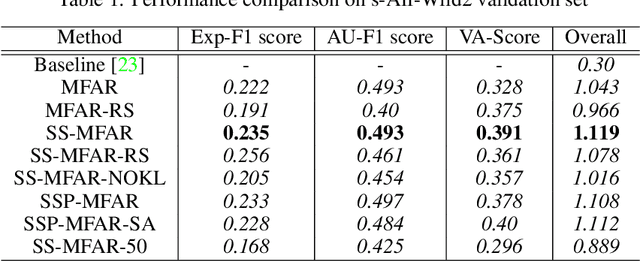

Automatic affect recognition has applications in many areas such as education, gaming, software development, automotives, medical care, etc. but it is non trivial task to achieve appreciable performance on in-the-wild data sets. In-the-wild data sets though represent real-world scenarios better than synthetic data sets, the former ones suffer from the problem of incomplete labels. Inspired by semi-supervised learning, in this paper, we introduce our submission to the Multi-Task-Learning Challenge at the 4th Affective Behavior Analysis in-the-wild (ABAW) 2022 Competition. The three tasks that are considered in this challenge are valence-arousal(VA) estimation, classification of expressions into 6 basic (anger, disgust, fear, happiness, sadness, surprise), neutral, and the 'other' category and 12 action units(AU) numbered AU-\{1,2,4,6,7,10,12,15,23,24,25,26\}. Our method Semi-supervised Multi-task Facial Affect Recognition titled \textbf{SS-MFAR} uses a deep residual network with task specific classifiers for each of the tasks along with adaptive thresholds for each expression class and semi-supervised learning for the incomplete labels. Source code is available at https://github.com/1980x/ABAW2022DMACS.
Affect Expression Behaviour Analysis in the Wild using Consensual Collaborative Training
Jul 24, 2021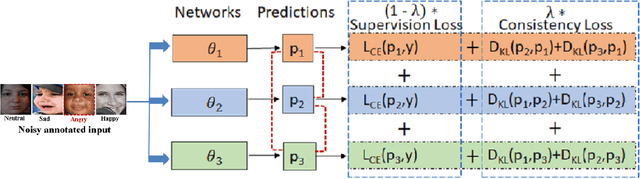
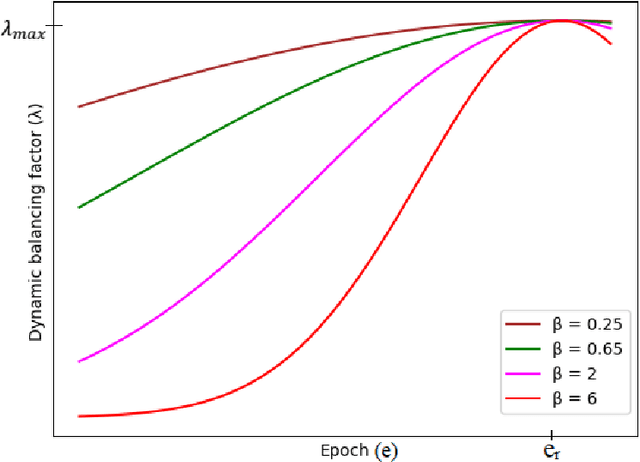
Facial expression recognition (FER) in the wild is crucial for building reliable human-computer interactive systems. However, annotations of large scale datasets in FER has been a key challenge as these datasets suffer from noise due to various factors like crowd sourcing, subjectivity of annotators, poor quality of images, automatic labelling based on key word search etc. Such noisy annotations impede the performance of FER due to the memorization ability of deep networks. During early learning stage, deep networks fit on clean data. Then, eventually, they start overfitting on noisy labels due to their memorization ability, which limits FER performance. This report presents Consensual Collaborative Training (CCT) framework used in our submission to expression recognition track of the Affective Behaviour Analysis in-the-wild (ABAW) 2021 competition. CCT co-trains three networks jointly using a convex combination of supervision loss and consistency loss, without making any assumption about the noise distribution. A dynamic transition mechanism is used to move from supervision loss in early learning to consistency loss for consensus of predictions among networks in the later stage. Co-training reduces overall error, and consistency loss prevents overfitting to noisy samples. The performance of the model is validated on challenging Aff-Wild2 dataset for categorical expression classification. Our code is made publicly available at https://github.com/1980x/ABAW2021DMACS.
* 7 pages, 2 figures. arXiv admin note: substantial text overlap with arXiv:2009.14440. substantial text overlap with arXiv:2107.04746
Affect Expression Behaviour Analysis in the Wild using Spatio-Channel Attention and Complementary Context Information
Oct 10, 2020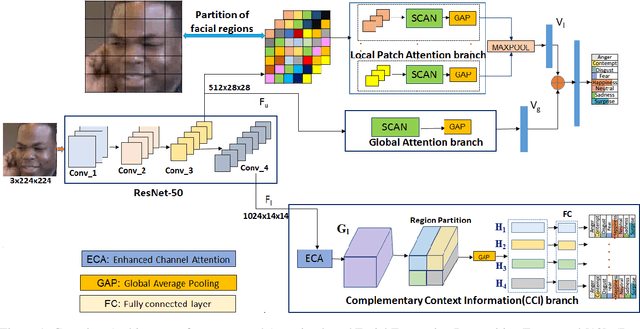
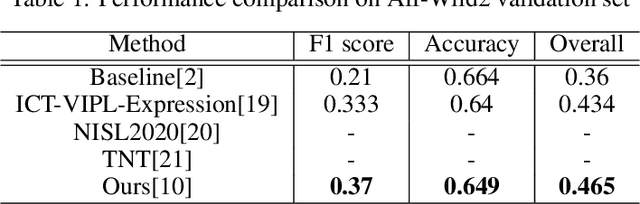
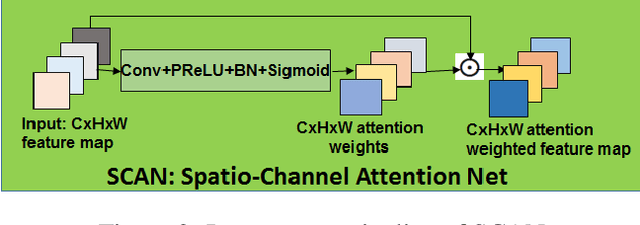

Facial expression recognition(FER) in the wild is crucial for building reliable human-computer interactive systems. However, current FER systems fail to perform well under various natural and un-controlled conditions. This report presents attention based framework used in our submission to expression recognition track of the Affective Behaviour Analysis in-the-wild (ABAW) 2020 competition. Spatial-channel attention net(SCAN) is used to extract local and global attentive features without seeking any information from landmark detectors. SCAN is complemented by a complementary context information(CCI) branch which uses efficient channel attention(ECA) to enhance the relevance of features. The performance of the model is validated on challenging Aff-Wild2 dataset for categorical expression classification.
Landmark Guidance Independent Spatio-channel Attention and Complementary Context Information based Facial Expression Recognition
Jul 25, 2020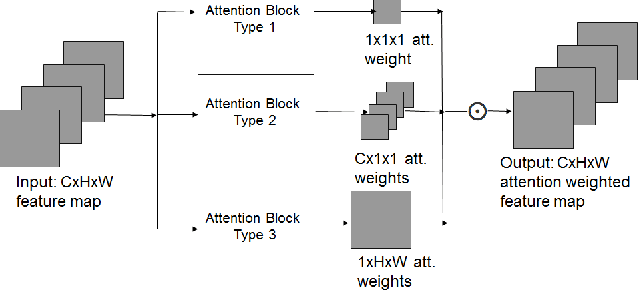



A recent trend to recognize facial expressions in the real-world scenario is to deploy attention based convolutional neural networks (CNNs) locally to signify the importance of facial regions and, combine it with global facial features and/or other complementary context information for performance gain. However, in the presence of occlusions and pose variations, different channels respond differently, and further that the response intensity of a channel differ across spatial locations. Also, modern facial expression recognition(FER) architectures rely on external sources like landmark detectors for defining attention. Failure of landmark detector will have a cascading effect on FER. Additionally, there is no emphasis laid on the relevance of features that are input to compute complementary context information. Leveraging on the aforementioned observations, an end-to-end architecture for FER is proposed in this work that obtains both local and global attention per channel per spatial location through a novel spatio-channel attention net (SCAN), without seeking any information from the landmark detectors. SCAN is complemented by a complementary context information (CCI) branch. Further, using efficient channel attention (ECA), the relevance of features input to CCI is also attended to. The representation learnt by the proposed architecture is robust to occlusions and pose variations. Robustness and superior performance of the proposed model is demonstrated on both in-lab and in-the-wild datasets (AffectNet, FERPlus, RAF-DB, FED-RO, SFEW, CK+, Oulu-CASIA and JAFFE) along with a couple of constructed face mask datasets resembling masked faces in COVID-19 scenario. Codes are publicly available at https://github.com/1980x/SCAN-CCI-FER
Teaching GANs to Sketch in Vector Format
Apr 07, 2019
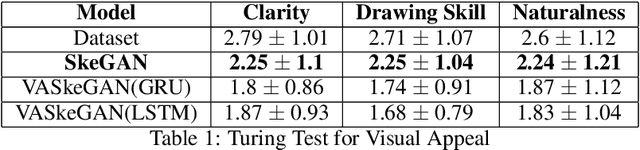
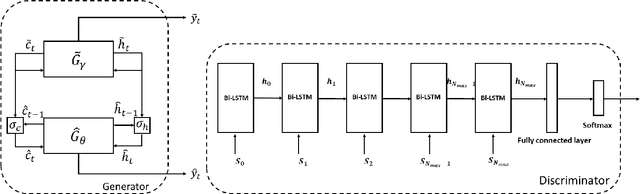

Sketching is more fundamental to human cognition than speech. Deep Neural Networks (DNNs) have achieved the state-of-the-art in speech-related tasks but have not made significant development in generating stroke-based sketches a.k.a sketches in vector format. Though there are Variational Auto Encoders (VAEs) for generating sketches in vector format, there is no Generative Adversarial Network (GAN) architecture for the same. In this paper, we propose a standalone GAN architecture SkeGAN and a VAE-GAN architecture VASkeGAN, for sketch generation in vector format. SkeGAN is a stochastic policy in Reinforcement Learning (RL), capable of generating both multidimensional continuous and discrete outputs. VASkeGAN hybridizes a VAE and a GAN, in order to couple the efficient representation of data by VAE with the powerful generating capabilities of a GAN, to produce visually appealing sketches. We also propose a new metric called the Ske-score which quantifies the quality of vector sketches. We have validated that SkeGAN and VASkeGAN generate visually appealing sketches by using Human Turing Test and Ske-score.