 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistorted Distributional Policy Evaluation for Offline Reinforcement Learning
Jan 05, 2026While Distributional Reinforcement Learning (DRL) methods have demonstrated strong performance in online settings, its success in offline scenarios remains limited. We hypothesize that a key limitation of existing offline DRL methods lies in their approach to uniformly underestimate return quantiles. This uniform pessimism can lead to overly conservative value estimates, ultimately hindering generalization and performance. To address this, we introduce a novel concept called quantile distortion, which enables non-uniform pessimism by adjusting the degree of conservatism based on the availability of supporting data. Our approach is grounded in theoretical analysis and empirically validated, demonstrating improved performance over uniform pessimism.
Mirror Descent Actor Critic via Bounded Advantage Learning
Feb 06, 2025



Regularization is a core component of recent Reinforcement Learning (RL) algorithms. Mirror Descent Value Iteration (MDVI) uses both Kullback-Leibler divergence and entropy as regularizers in its value and policy updates. Despite its empirical success in discrete action domains and strong theoretical guarantees, the performance of a MDVI-based method does not surpass an entropy-only-regularized method in continuous action domains. In this study, we propose Mirror Descent Actor Critic (MDAC) as an actor-critic style instantiation of MDVI for continuous action domains, and show that its empirical performance is significantly boosted by bounding the actor's log-density terms in the critic's loss function, compared to a non-bounded naive instantiation. Further, we relate MDAC to Advantage Learning by recalling that the actor's log-probability is equal to the regularized advantage function in tabular cases, and theoretically discuss when and why bounding the advantage terms is validated and beneficial. We also empirically explore a good choice for the bounding function, and show that MDAC perfoms better than strong non-regularized and entropy-only-regularized methods with an appropriate choice of the bounding function.
Situated GAIL: Multitask imitation using task-conditioned adversarial inverse reinforcement learning
Nov 01, 2019
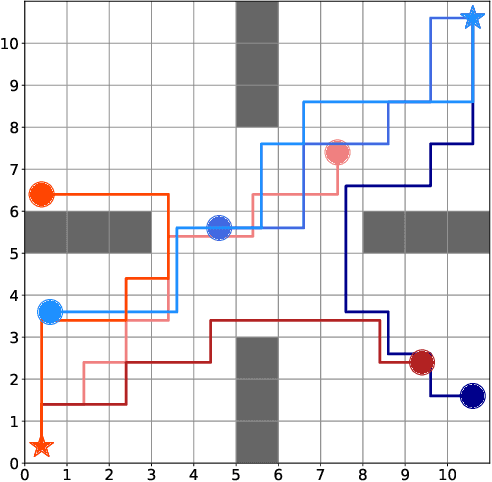
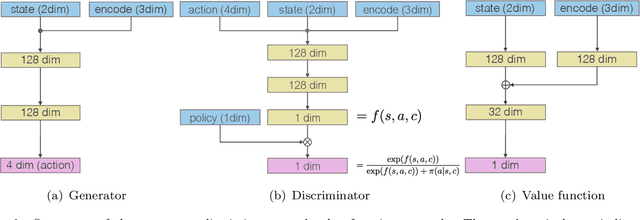
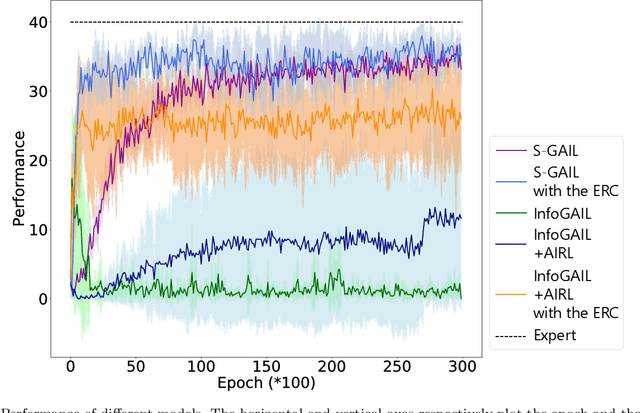
Generative adversarial imitation learning (GAIL) has attracted increasing attention in the field of robot learning. It enables robots to learn a policy to achieve a task demonstrated by an expert while simultaneously estimating the reward function behind the expert's behaviors. However, this framework is limited to learning a single task with a single reward function. This study proposes an extended framework called situated GAIL (S-GAIL), in which a task variable is introduced to both the discriminator and generator of the GAIL framework. The task variable has the roles of discriminating different contexts and making the framework learn different reward functions and policies for multiple tasks. To achieve the early convergence of learning and robustness during reward estimation, we introduce a term to adjust the entropy regularization coefficient in the generator's objective function. Our experiments using two setups (navigation in a discrete grid world and arm reaching in a continuous space) demonstrate that the proposed framework can acquire multiple reward functions and policies more effectively than existing frameworks. The task variable enables our framework to differentiate contexts while sharing common knowledge among multiple tasks.
On- and Off-Policy Monotonic Policy Improvement
Nov 01, 2017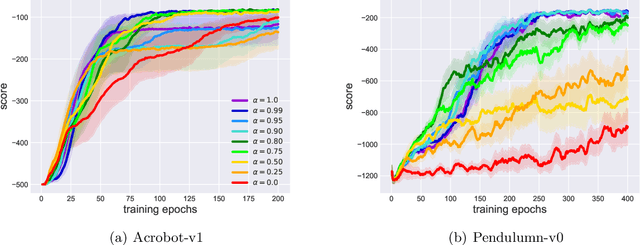
Monotonic policy improvement and off-policy learning are two main desirable properties for reinforcement learning algorithms. In this paper, by lower bounding the performance difference of two policies, we show that the monotonic policy improvement is guaranteed from on- and off-policy mixture samples. An optimization procedure which applies the proposed bound can be regarded as an off-policy natural policy gradient method. In order to support the theoretical result, we provide a trust region policy optimization method using experience replay as a naive application of our bound, and evaluate its performance in two classical benchmark problems.