Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn- and Off-Policy Monotonic Policy Improvement
Paper and Code
Nov 01, 2017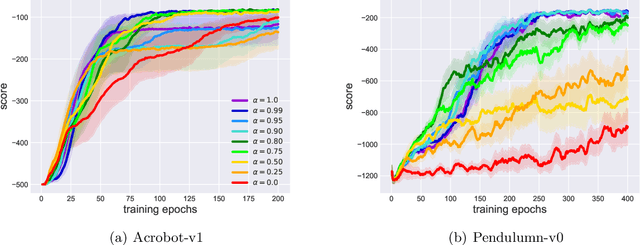
Monotonic policy improvement and off-policy learning are two main desirable properties for reinforcement learning algorithms. In this paper, by lower bounding the performance difference of two policies, we show that the monotonic policy improvement is guaranteed from on- and off-policy mixture samples. An optimization procedure which applies the proposed bound can be regarded as an off-policy natural policy gradient method. In order to support the theoretical result, we provide a trust region policy optimization method using experience replay as a naive application of our bound, and evaluate its performance in two classical benchmark problems.
View paper on