 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection from Differentially Private Correlations
Aug 20, 2024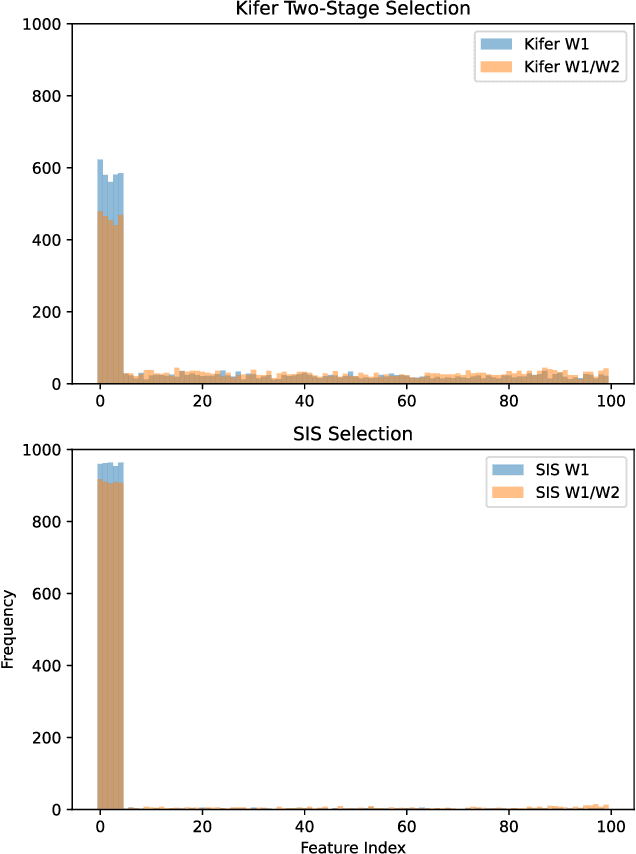
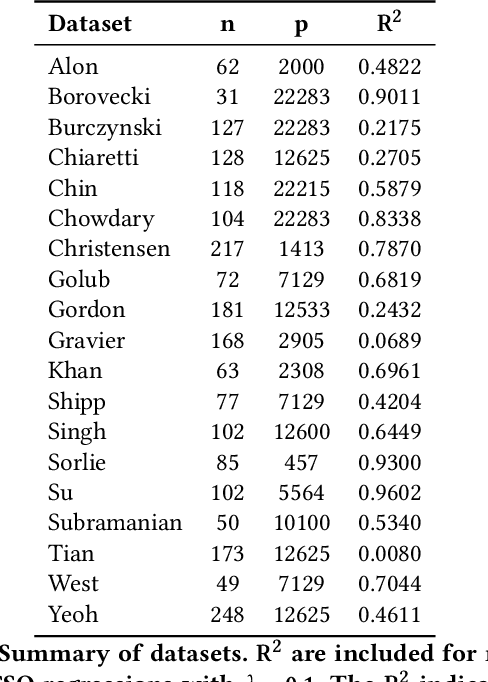
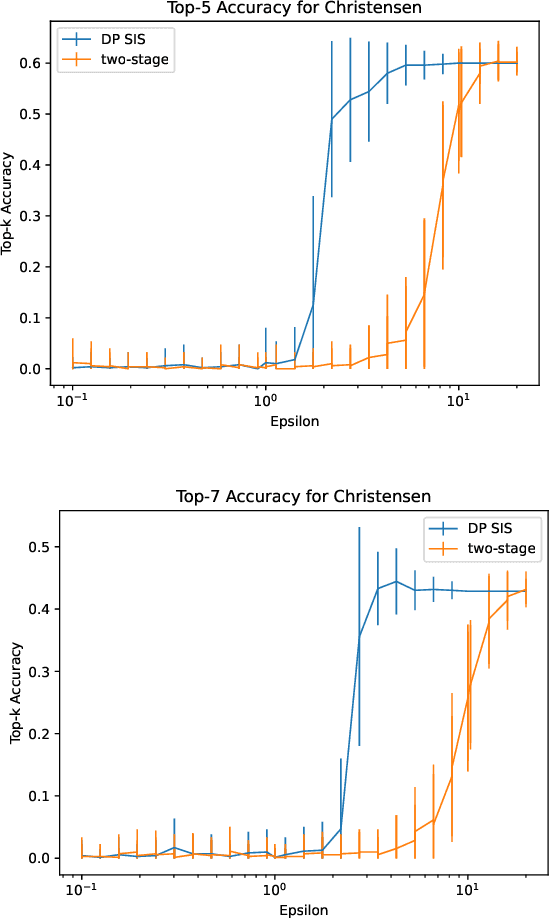
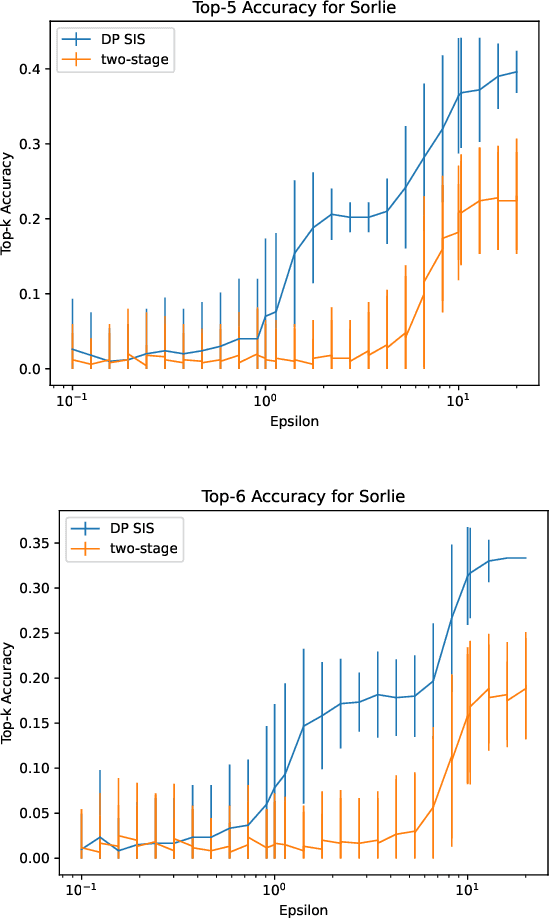
Data scientists often seek to identify the most important features in high-dimensional datasets. This can be done through $L_1$-regularized regression, but this can become inefficient for very high-dimensional datasets. Additionally, high-dimensional regression can leak information about individual datapoints in a dataset. In this paper, we empirically evaluate the established baseline method for feature selection with differential privacy, the two-stage selection technique, and show that it is not stable under sparsity. This makes it perform poorly on real-world datasets, so we consider a different approach to private feature selection. We employ a correlations-based order statistic to choose important features from a dataset and privatize them to ensure that the results do not leak information about individual datapoints. We find that our method significantly outperforms the established baseline for private feature selection on many datasets.