 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Soil Collection in Environments With Heterogeneous Terrain
Jul 15, 2024



To autonomously collect soil in uncultivated terrain, robotic arms must distinguish between different amorphous materials and submerge themselves into the correct material. We develop a prototype that collects soil in heterogeneous terrain. If mounted to a mobile robot, it can be used to perform soil collection and analysis without human intervention. Unique among soil sampling robots, we use a general-purpose robotic arm rather than a soil core sampler.
Multi-Agent Team Access Monitoring: Environments that Benefit from Target Information Sharing
Mar 28, 2024



Robotic access monitoring of multiple target areas has applications including checkpoint enforcement, surveillance and containment of fire and flood hazards. Monitoring access for a single target region has been successfully modeled as a minimum-cut problem. We generalize this model to support multiple target areas using two approaches: iterating on individual targets and examining the collections of targets holistically. Through simulation we measure the performance of each approach on different scenarios.
Automated Multimodal Data Annotation via Calibration With Indoor Positioning System
Dec 06, 2023Learned object detection methods based on fusion of LiDAR and camera data require labeled training samples, but niche applications, such as warehouse robotics or automated infrastructure, require semantic classes not available in large existing datasets. Therefore, to facilitate the rapid creation of multimodal object detection datasets and alleviate the burden of human labeling, we propose a novel automated annotation pipeline. Our method uses an indoor positioning system (IPS) to produce accurate detection labels for both point clouds and images and eliminates manual annotation entirely. In an experiment, the system annotates objects of interest 261.8 times faster than a human baseline and speeds up end-to-end dataset creation by 61.5%.
SurfaceAug: Closing the Gap in Multimodal Ground Truth Sampling
Dec 06, 2023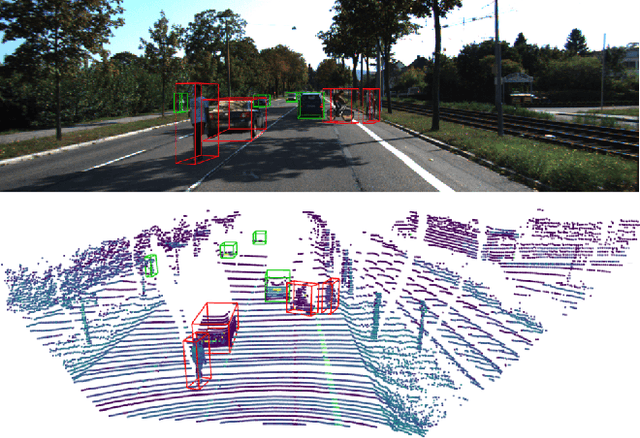



Despite recent advances in both model architectures and data augmentation, multimodal object detectors still barely outperform their LiDAR-only counterparts. This shortcoming has been attributed to a lack of sufficiently powerful multimodal data augmentation. To address this, we present SurfaceAug, a novel ground truth sampling algorithm. SurfaceAug pastes objects by resampling both images and point clouds, enabling object-level transformations in both modalities. We evaluate our algorithm by training a multimodal detector on KITTI and compare its performance to previous works. We show experimentally that SurfaceAug outperforms existing methods on car detection tasks and establishes a new state of the art for multimodal ground truth sampling.