 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurfaceAug: Closing the Gap in Multimodal Ground Truth Sampling
Paper and Code
Dec 06, 2023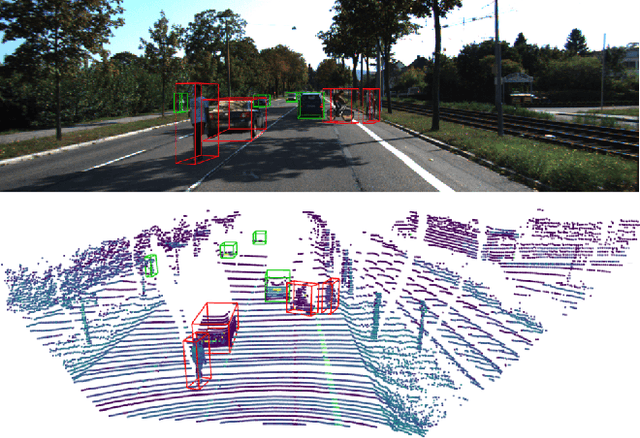



Despite recent advances in both model architectures and data augmentation, multimodal object detectors still barely outperform their LiDAR-only counterparts. This shortcoming has been attributed to a lack of sufficiently powerful multimodal data augmentation. To address this, we present SurfaceAug, a novel ground truth sampling algorithm. SurfaceAug pastes objects by resampling both images and point clouds, enabling object-level transformations in both modalities. We evaluate our algorithm by training a multimodal detector on KITTI and compare its performance to previous works. We show experimentally that SurfaceAug outperforms existing methods on car detection tasks and establishes a new state of the art for multimodal ground truth sampling.