 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBe aware of overfitting by hyperparameter optimization!
Jul 30, 2024Hyperparameter optimization is very frequently employed in machine learning. However, an optimization of a large space of parameters could result in overfitting of models. In recent studies on solubility prediction the authors collected seven thermodynamic and kinetic solubility datasets from different data sources. They used state-of-the-art graph-based methods and compared models developed for each dataset using different data cleaning protocols and hyperparameter optimization. In our study we showed that hyperparameter optimization did not always result in better models, possibly due to overfitting when using the same statistical measures. Similar results could be calculated using pre-set hyperparameters, reducing the computational effort by around 10,000 times. We also extended the previous analysis by adding a representation learning method based on Natural Language Processing of smiles called Transformer CNN. We show that across all analyzed sets using exactly the same protocol, Transformer CNN provided better results than graph-based methods for 26 out of 28 pairwise comparisons by using only a tiny fraction of time as compared to other methods. Last but not least we stressed the importance of comparing calculation results using exactly the same statistical measures.
Beyond Chemical 1D knowledge using Transformers
Oct 07, 2020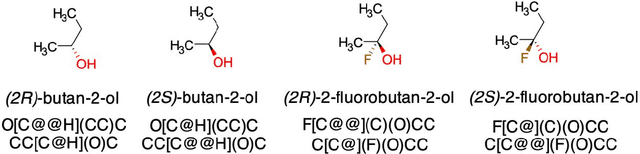


In the present paper we evaluated efficiency of the recent Transformer-CNN models to predict target properties based on the augmented stereochemical SMILES. We selected a well-known Cliff activity dataset as well as a Dipole moment dataset and compared the effect of three representations for R/S stereochemistry in SMILES. The considered representations were SMILES without stereochemistry (noChiSMI), classical relative stereochemistry encoding (RelChiSMI) and an alternative version with absolute stereochemistry encoding (AbsChiSMI). The inclusion of R/S in SMILES representation allowed simplify the assignment of the respective information based on SMILES representation, but did not always show advantages on regression or classification tasks. Interestingly, we did not see degradation of the performance of Transformer-CNN models when the stereochemical information was not present in SMILES. Moreover, these models showed higher or similar performance compared to descriptor-based models based on 3D structures. These observations are an important step in NLP modeling of 3D chemical tasks. An open challenge remains whether Transformer-CNN can efficiently embed 3D knowledge from SMILES input and whether a better representation could further increase the accuracy of this approach.
Deep Generative Model for Sparse Graphs using Text-Based Learning with Augmentation in Generative Examination Networks
Sep 24, 2019


Graphs and networks are a key research tool for a variety of science fields, most notably chemistry, biology, engineering and social sciences. Modeling and generation of graphs with efficient sampling is a key challenge for graphs. In particular, the non-uniqueness, high dimensionality of the vertices and local dependencies of the edges may render the task challenging. We apply our recently introduced method, Generative Examination Networks (GENs) to create the first text-based generative graph models using one-line text formats as graph representation. In our GEN, a RNN-generative model for a one-line text format learns autonomously to predict the next available character. The training is stopped by an examination mechanism checking validating the percentage of valid graphs generated. We achieved moderate to high validity using dense g6 strings (random 67.8 +/- 0.6, canonical 99.1 +/- 0.2). Based on these results we have adapted the widely used SMILES representation for molecules to a new input format, which we call linear graph input (LGI). Apart from the benefits of a short compressible text-format, a major advantage include the possibility to randomize and augment the format. The generative models are evaluated for overall performance and for reconstruction of the property space. The results show that LGI strings are very well suited for machine-learning and that augmentation is essential for the performance of the model in terms of validity, uniqueness and novelty. Lastly, the format can address smaller and larger dataset of graphs and the format can be easily adapted to define another meaning of the characters used in the LGI-string and can address sparse graph problems in used in other fields of science.
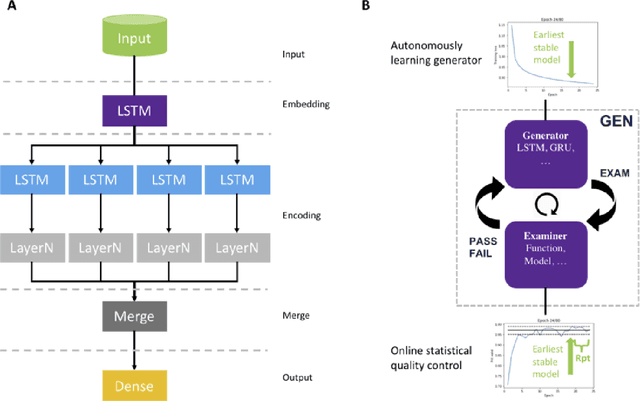
GEN: Highly Efficient SMILES Explorer Using Autodidactic Generative Examination Networks
Sep 10, 2019



Recurrent neural networks have been widely used to generate millions of de novo molecules in a known chemical space. These deep generative models are typically setup with LSTM or GRU units and trained with canonical SMILEs. In this study, we introduce a new robust architecture, Generative Examination Networks GEN, based on bidirectional RNNs with concatenated sub-models to learn and generate molecular SMILES with a trained target space. GENs autonomously learn the target space in a few epochs while being subjected to an independent online examination mechanism to measure the quality of the generated set. Here we have used online statistical quality control (SQC) on the percentage of valid molecules SMILES as an examination measure to select the earliest available stable model weights. Very high levels of valid SMILES (95-98%) can be generated using multiple parallel encoding layers in combination with SMILES augmentation using unrestricted SMILES randomization. Our architecture combines an excellent novelty rate (85-90%) while generating SMILES with a strong conservation of the property space (95-99%). Our flexible examination mechanism is open to other quality criteria.