 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of Synthetic Electronic Medical Record Text
Dec 06, 2018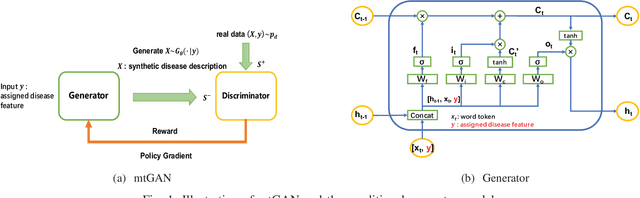
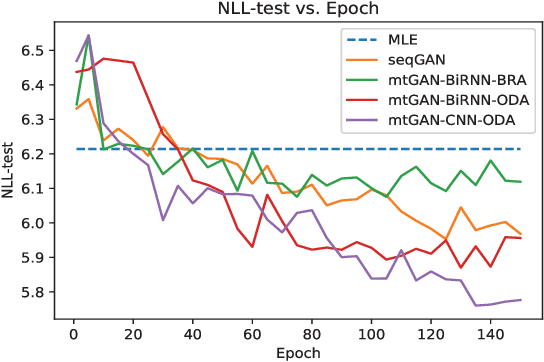


Machine learning (ML) and Natural Language Processing (NLP) have achieved remarkable success in many fields and have brought new opportunities and high expectation in the analyses of medical data. The most common type of medical data is the massive free-text electronic medical records (EMR). It is widely regarded that mining such massive data can bring up important information for improving medical practices as well as for possible new discoveries on complex diseases. However, the free EMR texts are lacking consistent standards, rich of private information, and limited in availability. Also, as they are accumulated from everyday practices, it is often hard to have a balanced number of samples for the types of diseases under study. These problems hinder the development of ML and NLP methods for EMR data analysis. To tackle these problems, we developed a model to generate synthetic text of EMRs called Medical Text Generative Adversarial Network or mtGAN. It is based on the GAN framework and is trained by the REINFORCE algorithm. It takes disease features as inputs and generates synthetic texts as EMRs for the corresponding diseases. We evaluate the model from micro-level, macro-level and application-level on a Chinese EMR text dataset. The results show that the method has a good capacity to fit real data and can generate realistic and diverse EMR samples. This provides a novel way to avoid potential leakage of patient privacy while still supply sufficient well-controlled cohort data for developing downstream ML and NLP methods. It can also be used as a data augmentation method to assist studies based on real EMR data.