 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe role of grammar in transition-probabilities of subsequent words in English text
Dec 28, 2018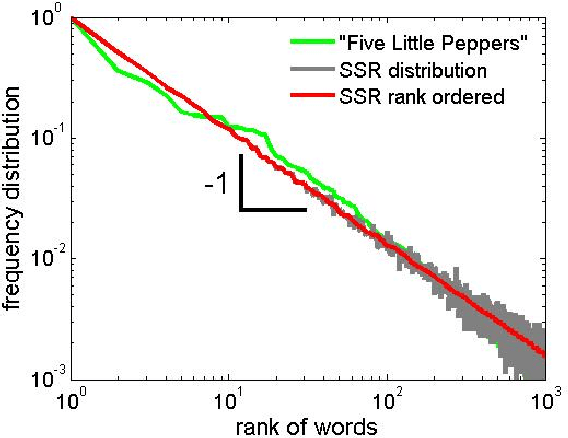
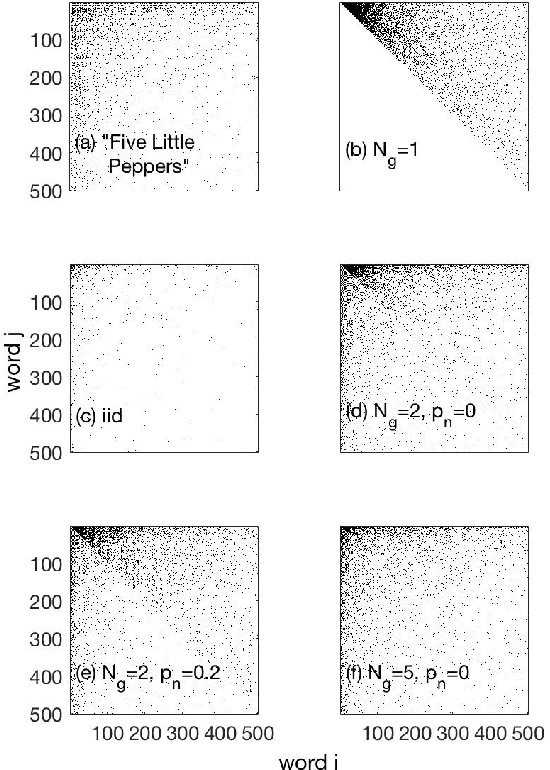
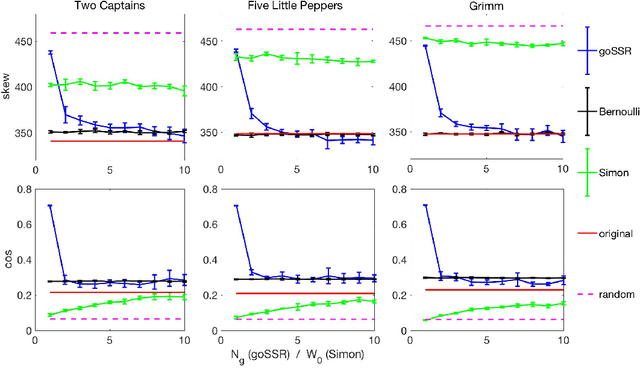
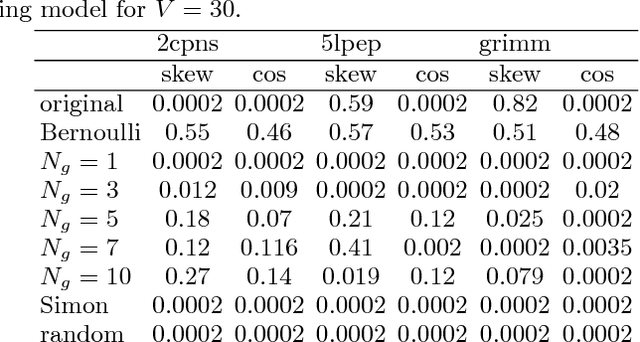
Sentence formation is a highly structured, history-dependent, and sample-space reducing (SSR) process. While the first word in a sentence can be chosen from the entire vocabulary, typically, the freedom of choosing subsequent words gets more and more constrained by grammar and context, as the sentence progresses. This sample-space reducing property offers a natural explanation of Zipf's law in word frequencies, however, it fails to capture the structure of the word-to-word transition probability matrices of English text. Here we adopt the view that grammatical constraints (such as subject--predicate--object) locally re-order the word order in sentences that are sampled with a SSR word generation process. We demonstrate that superimposing grammatical structure -- as a local word re-ordering (permutation) process -- on a sample-space reducing process is sufficient to explain both, word frequencies and word-to-word transition probabilities. We compare the quality of the grammatically ordered SSR model in reproducing several test statistics of real texts with other text generation models, such as the Bernoulli model, the Simon model, and the Monkey typewriting model.
Understanding Zipf's law of word frequencies through sample-space collapse in sentence formation
May 27, 2015

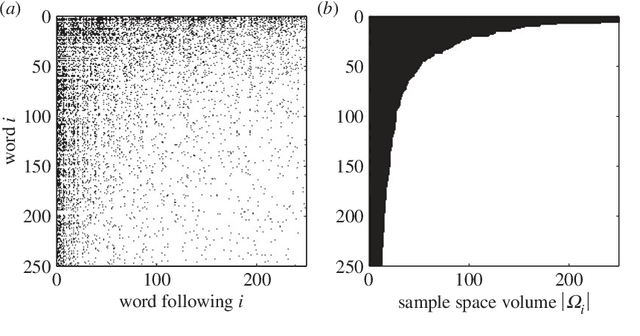
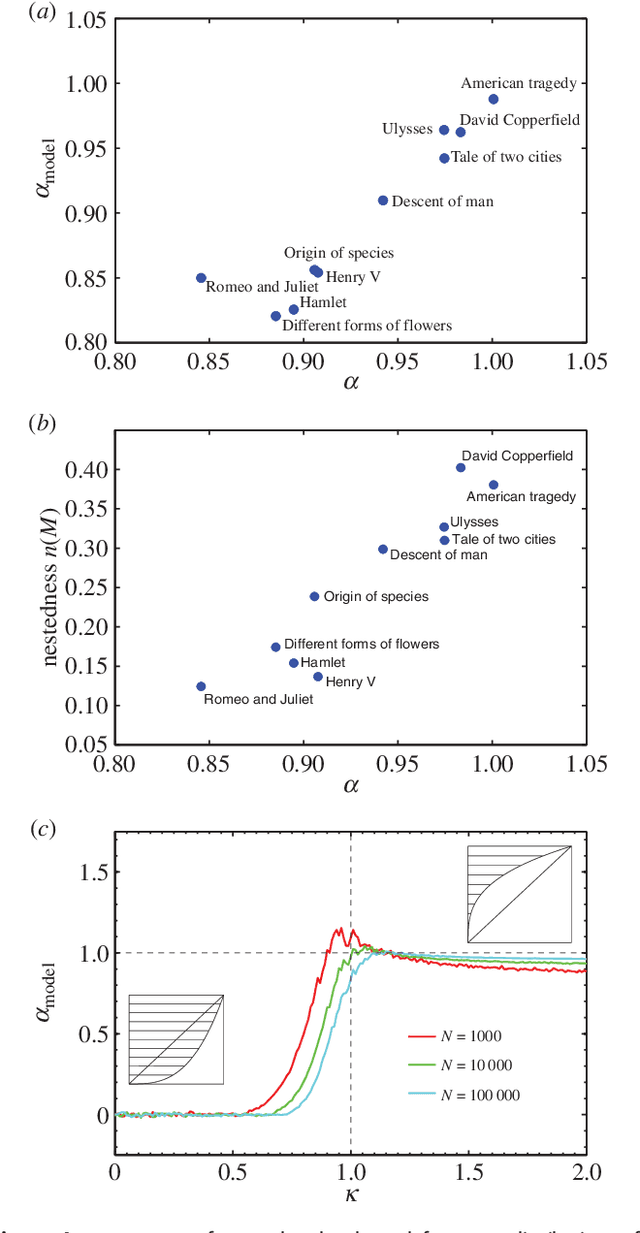
The formation of sentences is a highly structured and history-dependent process. The probability of using a specific word in a sentence strongly depends on the 'history' of word-usage earlier in that sentence. We study a simple history-dependent model of text generation assuming that the sample-space of word usage reduces along sentence formation, on average. We first show that the model explains the approximate Zipf law found in word frequencies as a direct consequence of sample-space reduction. We then empirically quantify the amount of sample-space reduction in the sentences of ten famous English books, by analysis of corresponding word-transition tables that capture which words can follow any given word in a text. We find a highly nested structure in these transition tables and show that this `nestedness' is tightly related to the power law exponents of the observed word frequency distributions. With the proposed model it is possible to understand that the nestedness of a text can be the origin of the actual scaling exponent, and that deviations from the exact Zipf law can be understood by variations of the degree of nestedness on a book-by-book basis. On a theoretical level we are able to show that in case of weak nesting, Zipf's law breaks down in a fast transition. Unlike previous attempts to understand Zipf's law in language the sample-space reducing model is not based on assumptions of multiplicative, preferential, or self-organised critical mechanisms behind language formation, but simply used the empirically quantifiable parameter 'nestedness' to understand the statistics of word frequencies.