 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing information into copying versus transformation
Mar 21, 2019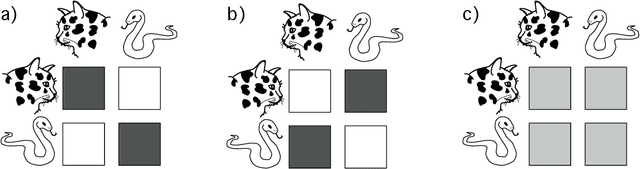
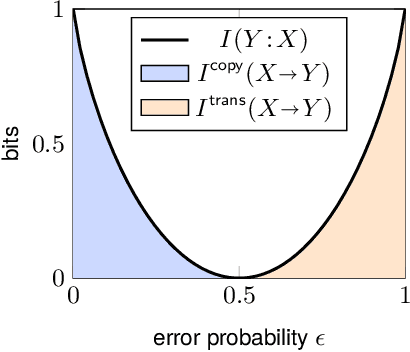
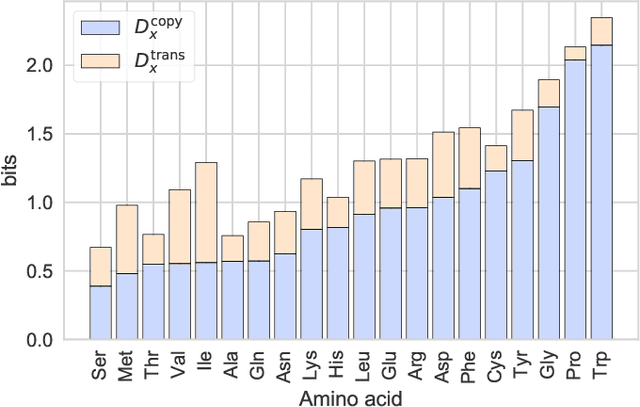
In many real-world systems, information can be transmitted in two qualitatively different ways: by {\em copying} or by {\em transformation}. {\em Copying} occurs when messages are transmitted without modification, for example when an offspring receives an unaltered copy of a gene from its parent. {\em Transformation} occurs when messages are modified in a systematic way during transmission, e.g., when non-random mutations occur during biological reproduction. Standard information-theoretic measures of information transmission, such as mutual information, do not distinguish these two modes of information transfer, even though they may reflect different mechanisms and have different functional consequences. We propose a decomposition of mutual information which separately quantifies the information transmitted by copying versus the information transmitted by transformation. Our measures of copy and transformation information are derived from a few simple axioms, and have natural operationalizations in terms of hypothesis testing and thermodynamics. In this later case, we show that our measure of copy information corresponds to the minimal amount of work needed by a physical copying process, having special relevance for the physics of replication of biological information. We demonstrate our measures on a real world dataset of amino acid substitution rates. Our decomposition into copy and transformation information is general and applies to any system in which the fidelity of copying, rather than simple predictability, is of critical relevance.
Understanding Zipf's law of word frequencies through sample-space collapse in sentence formation
May 27, 2015

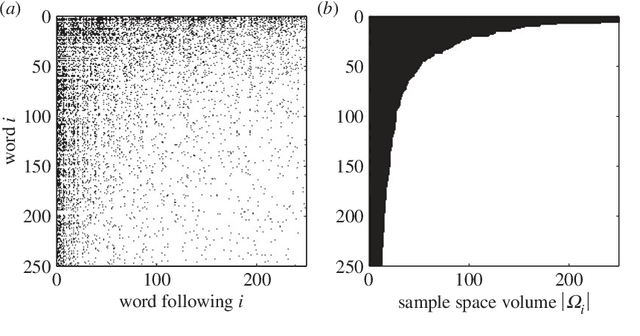
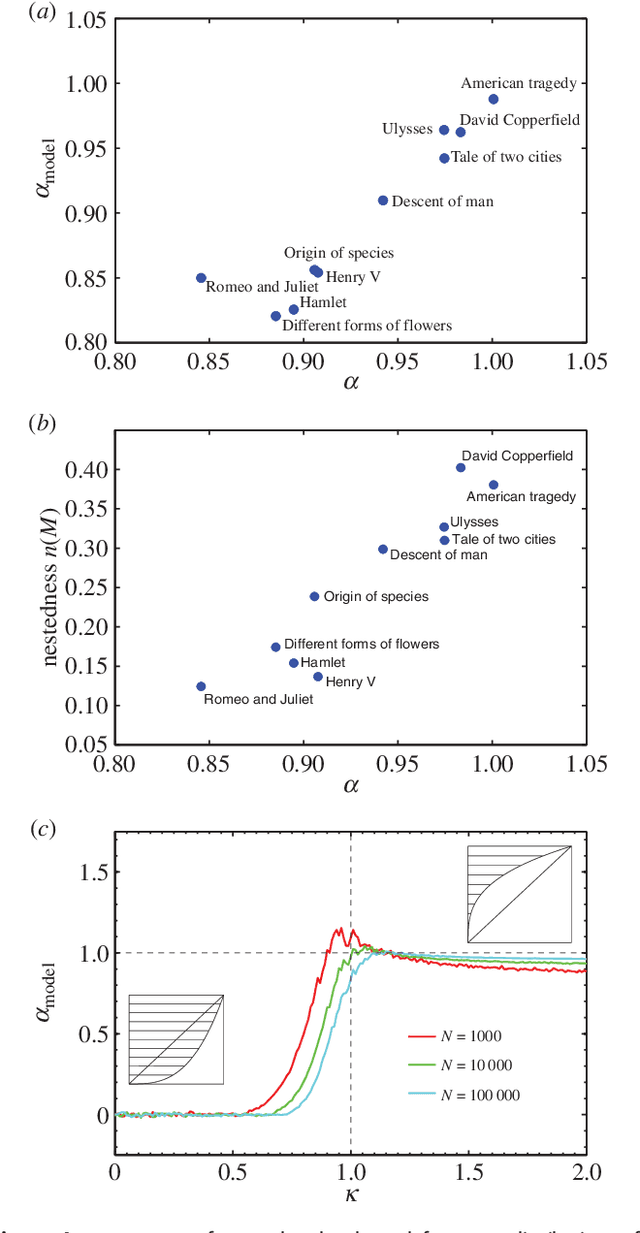
The formation of sentences is a highly structured and history-dependent process. The probability of using a specific word in a sentence strongly depends on the 'history' of word-usage earlier in that sentence. We study a simple history-dependent model of text generation assuming that the sample-space of word usage reduces along sentence formation, on average. We first show that the model explains the approximate Zipf law found in word frequencies as a direct consequence of sample-space reduction. We then empirically quantify the amount of sample-space reduction in the sentences of ten famous English books, by analysis of corresponding word-transition tables that capture which words can follow any given word in a text. We find a highly nested structure in these transition tables and show that this `nestedness' is tightly related to the power law exponents of the observed word frequency distributions. With the proposed model it is possible to understand that the nestedness of a text can be the origin of the actual scaling exponent, and that deviations from the exact Zipf law can be understood by variations of the degree of nestedness on a book-by-book basis. On a theoretical level we are able to show that in case of weak nesting, Zipf's law breaks down in a fast transition. Unlike previous attempts to understand Zipf's law in language the sample-space reducing model is not based on assumptions of multiplicative, preferential, or self-organised critical mechanisms behind language formation, but simply used the empirically quantifiable parameter 'nestedness' to understand the statistics of word frequencies.
On the origin of ambiguity in efficient communication
Oct 01, 2013



This article studies the emergence of ambiguity in communication through the concept of logical irreversibility and within the framework of Shannon's information theory. This leads us to a precise and general expression of the intuition behind Zipf's vocabulary balance in terms of a symmetry equation between the complexities of the coding and the decoding processes that imposes an unavoidable amount of logical uncertainty in natural communication. Accordingly, the emergence of irreversible computations is required if the complexities of the coding and the decoding processes are balanced in a symmetric scenario, which means that the emergence of ambiguous codes is a necessary condition for natural communication to succeed.
* 28 pages, 2 figures
Switcher-random-walks: a cognitive-inspired mechanism for network exploration
Mar 24, 2009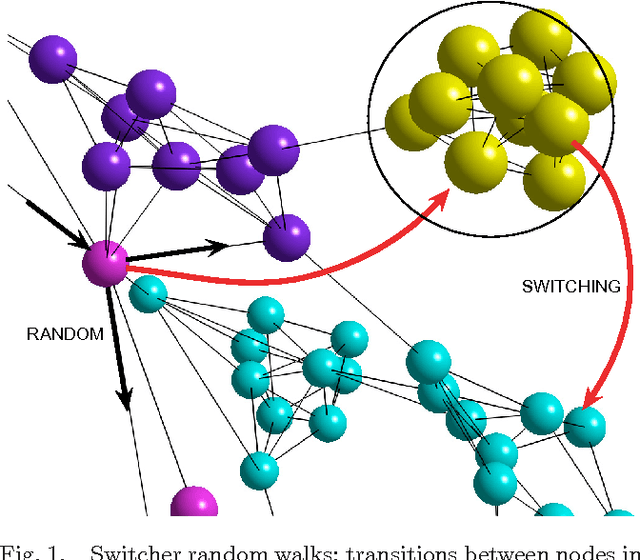
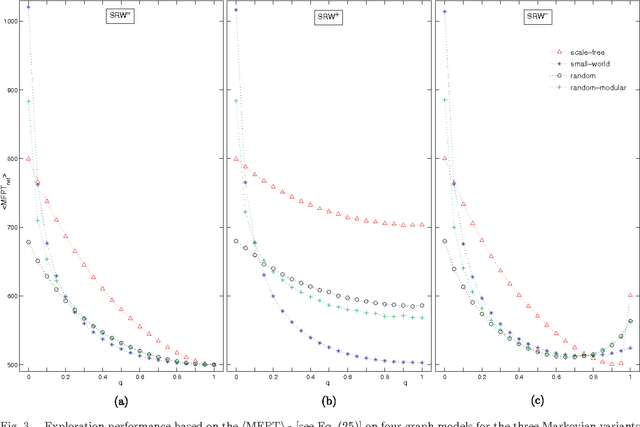
Semantic memory is the subsystem of human memory that stores knowledge of concepts or meanings, as opposed to life specific experiences. The organization of concepts within semantic memory can be understood as a semantic network, where the concepts (nodes) are associated (linked) to others depending on perceptions, similarities, etc. Lexical access is the complementary part of this system and allows the retrieval of such organized knowledge. While conceptual information is stored under certain underlying organization (and thus gives rise to a specific topology), it is crucial to have an accurate access to any of the information units, e.g. the concepts, for efficiently retrieving semantic information for real-time needings. An example of an information retrieval process occurs in verbal fluency tasks, and it is known to involve two different mechanisms: -clustering-, or generating words within a subcategory, and, when a subcategory is exhausted, -switching- to a new subcategory. We extended this approach to random-walking on a network (clustering) in combination to jumping (switching) to any node with certain probability and derived its analytical expression based on Markov chains. Results show that this dual mechanism contributes to optimize the exploration of different network models in terms of the mean first passage time. Additionally, this cognitive inspired dual mechanism opens a new framework to better understand and evaluate exploration, propagation and transport phenomena in other complex systems where switching-like phenomena are feasible.
* 9 pages, 3 figures. Accepted in "International Journal of Bifurcations and Chaos": Special issue on "Modelling and Computation on Complex Networks"
Network statistics on early English Syntax: Structural criteria
Apr 30, 2007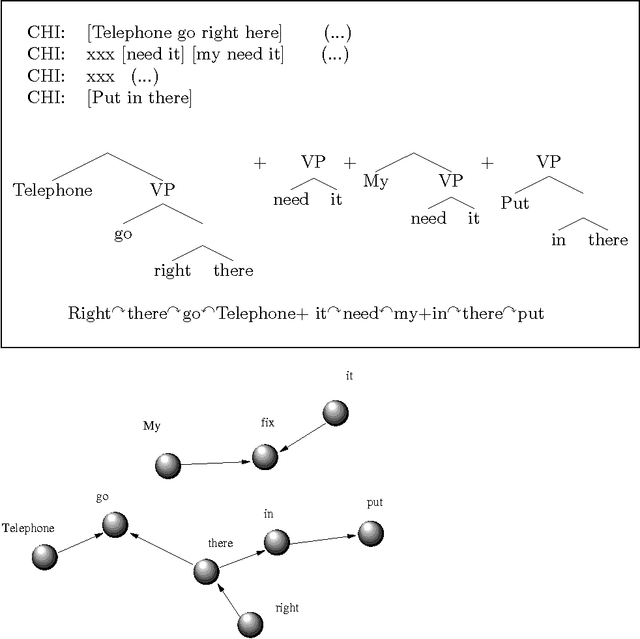
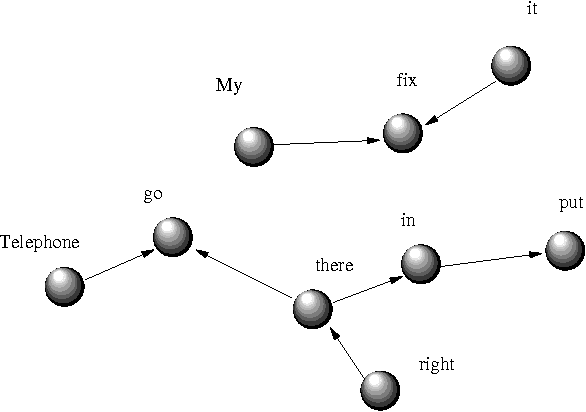
This paper includes a reflection on the role of networks in the study of English language acquisition, as well as a collection of practical criteria to annotate free-speech corpora from children utterances. At the theoretical level, the main claim of this paper is that syntactic networks should be interpreted as the outcome of the use of the syntactic machinery. Thus, the intrinsic features of such machinery are not accessible directly from (known) network properties. Rather, what one can see are the global patterns of its use and, thus, a global view of the power and organization of the underlying grammar. Taking a look into more practical issues, the paper examines how to build a net from the projection of syntactic relations. Recall that, as opposed to adult grammars, early-child language has not a well-defined concept of structure. To overcome such difficulty, we develop a set of systematic criteria assuming constituency hierarchy and a grammar based on lexico-thematic relations. At the end, what we obtain is a well defined corpora annotation that enables us i) to perform statistics on the size of structures and ii) to build a network from syntactic relations over which we can perform the standard measures of complexity. We also provide a detailed example.