 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Algorithmic Profiling: A German Case Study
Aug 04, 2021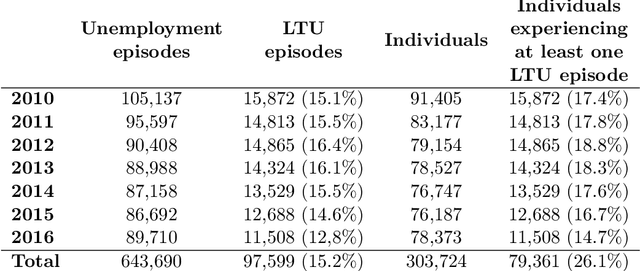
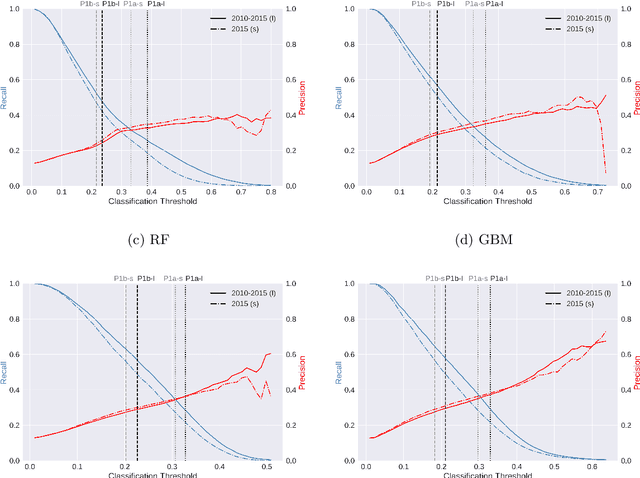

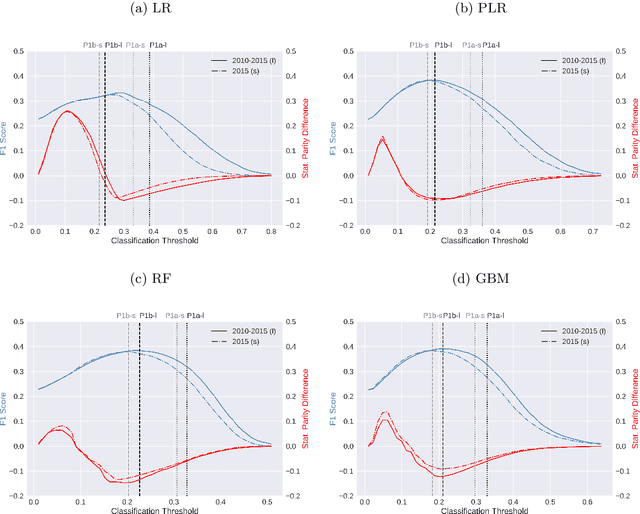
Algorithmic profiling is increasingly used in the public sector as a means to allocate limited public resources effectively and objectively. One example is the prediction-based statistical profiling of job seekers to guide the allocation of support measures by public employment services. However, empirical evaluations of potential side-effects such as unintended discrimination and fairness concerns are rare. In this study, we compare and evaluate statistical models for predicting job seekers' risk of becoming long-term unemployed with respect to prediction performance, fairness metrics, and vulnerabilities to data analysis decisions. Focusing on Germany as a use case, we evaluate profiling models under realistic conditions by utilizing administrative data on job seekers' employment histories that are routinely collected by German public employment services. Besides showing that these data can be used to predict long-term unemployment with competitive levels of accuracy, we highlight that different classification policies have very different fairness implications. We therefore call for rigorous auditing processes before such models are put to practice.
Distributive Justice and Fairness Metrics in Automated Decision-making: How Much Overlap Is There?
May 06, 2021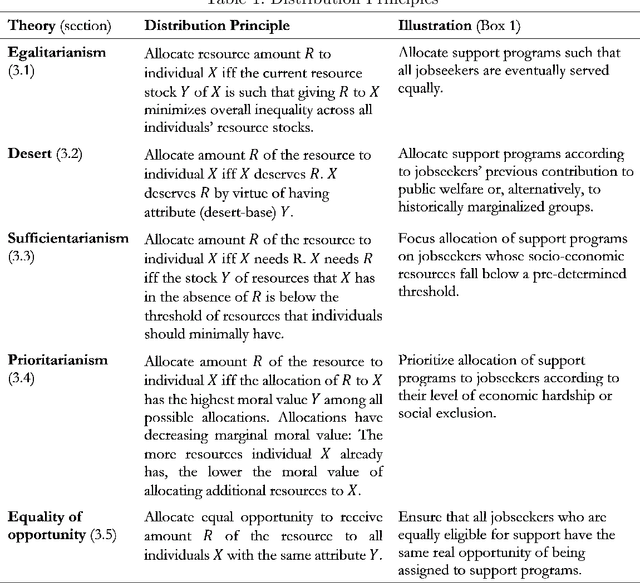
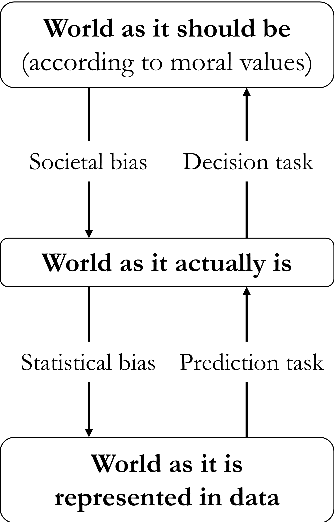


The advent of powerful prediction algorithms led to increased automation of high-stake decisions regarding the allocation of scarce resources such as government spending and welfare support. This automation bears the risk of perpetuating unwanted discrimination against vulnerable and historically disadvantaged groups. Research on algorithmic discrimination in computer science and other disciplines developed a plethora of fairness metrics to detect and correct discriminatory algorithms. Drawing on robust sociological and philosophical discourse on distributive justice, we identify the limitations and problematic implications of prominent fairness metrics. We show that metrics implementing equality of opportunity only apply when resource allocations are based on deservingness, but fail when allocations should reflect concerns about egalitarianism, sufficiency, and priority. We argue that by cleanly distinguishing between prediction tasks and decision tasks, research on fair machine learning could take better advantage of the rich literature on distributive justice.