 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Chain-Ladder to Individual Claims Reserving
Feb 17, 2026The chain-ladder (CL) method is the most widely used claims reserving technique in non-life insurance. This manuscript introduces a novel approach to computing the CL reserves based on a fundamental restructuring of the data utilization for the CL prediction procedure. Instead of rolling forward the cumulative claims with estimated CL factors, we estimate multi-period factors that project the latest observations directly to the ultimate claims. This alternative perspective on CL reserving creates a natural pathway for the application of machine learning techniques to individual claims reserving. As a proof of concept, we present a small-scale real data application employing neural networks for individual claims reserving.
Tab-TRM: Tiny Recursive Model for Insurance Pricing on Tabular Data
Jan 12, 2026We introduce Tab-TRM (Tabular-Tiny Recursive Model), a network architecture that adapts the recursive latent reasoning paradigm of Tiny Recursive Models (TRMs) to insurance modeling. Drawing inspiration from both the Hierarchical Reasoning Model (HRM) and its simplified successor TRM, the Tab-TRM model makes predictions by reasoning over the input features. It maintains two learnable latent tokens - an answer token and a reasoning state - that are iteratively refined by a compact, parameter-efficient recursive network. The recursive processing layer repeatedly updates the reasoning state given the full token sequence and then refines the answer token, in close analogy with iterative insurance pricing schemes. Conceptually, Tab-TRM bridges classical actuarial workflows - iterative generalized linear model fitting and minimum-bias calibration - on the one hand, and modern machine learning, in terms of Gradient Boosting Machines, on the other.
Reinforcement Learning for Micro-Level Claims Reserving
Jan 12, 2026Outstanding claim liabilities are revised repeatedly as claims develop, yet most modern reserving models are trained as one-shot predictors and typically learn only from settled claims. We formulate individual claims reserving as a claim-level Markov decision process in which an agent sequentially updates outstanding claim liability (OCL) estimates over development, using continuous actions and a reward design that balances accuracy with stable reserve revisions. A key advantage of this reinforcement learning (RL) approach is that it can learn from all observed claim trajectories, including claims that remain open at valuation, thereby avoiding the reduced sample size and selection effects inherent in supervised methods trained on ultimate outcomes only. We also introduce practical components needed for actuarial use -- initialisation of new claims, temporally consistent tuning via a rolling-settlement scheme, and an importance-weighting mechanism to mitigate portfolio-level underestimation driven by the rarity of large claims. On CAS and SPLICE synthetic general insurance datasets, the proposed Soft Actor-Critic implementation delivers competitive claim-level accuracy and strong aggregate OCL performance, particularly for the immature claim segments that drive most of the liability.
In-Context Learning Enhanced Credibility Transformer
Sep 09, 2025The starting point of our network architecture is the Credibility Transformer which extends the classical Transformer architecture by a credibility mechanism to improve model learning and predictive performance. This Credibility Transformer learns credibilitized CLS tokens that serve as learned representations of the original input features. In this paper we present a new paradigm that augments this architecture by an in-context learning mechanism, i.e., we increase the information set by a context batch consisting of similar instances. This allows the model to enhance the CLS token representations of the instances by additional in-context information and fine-tuning. We empirically verify that this in-context learning enhances predictive accuracy by adapting to similar risk patterns. Moreover, this in-context learning also allows the model to generalize to new instances which, e.g., have feature levels in the categorical covariates that have not been present when the model was trained -- for a relevant example, think of a new vehicle model which has just been developed by a car manufacturer.
The Credibility Transformer
Sep 25, 2024
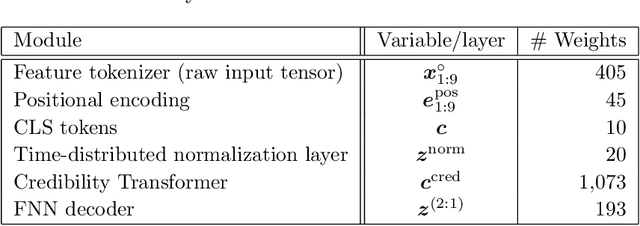
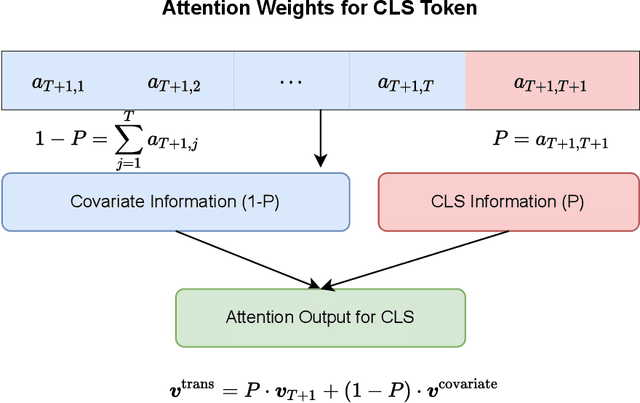
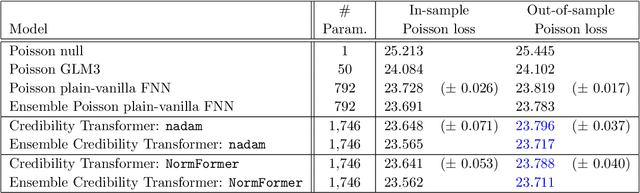
Inspired by the large success of Transformers in Large Language Models, these architectures are increasingly applied to tabular data. This is achieved by embedding tabular data into low-dimensional Euclidean spaces resulting in similar structures as time-series data. We introduce a novel credibility mechanism to this Transformer architecture. This credibility mechanism is based on a special token that should be seen as an encoder that consists of a credibility weighted average of prior information and observation based information. We demonstrate that this novel credibility mechanism is very beneficial to stabilize training, and our Credibility Transformer leads to predictive models that are superior to state-of-the-art deep learning models.
Multiple Yield Curve Modeling and Forecasting using Deep Learning
Jan 30, 2024This manuscript introduces deep learning models that simultaneously describe the dynamics of several yield curves. We aim to learn the dependence structure among the different yield curves induced by the globalization of financial markets and exploit it to produce more accurate forecasts. By combining the self-attention mechanism and nonparametric quantile regression, our model generates both point and interval forecasts of future yields. The architecture is designed to avoid quantile crossing issues affecting multiple quantile regression models. Numerical experiments conducted on two different datasets confirm the effectiveness of our approach. Finally, we explore potential extensions and enhancements by incorporating deep ensemble methods and transfer learning mechanisms.
Conditional expectation network for SHAP
Jul 20, 2023
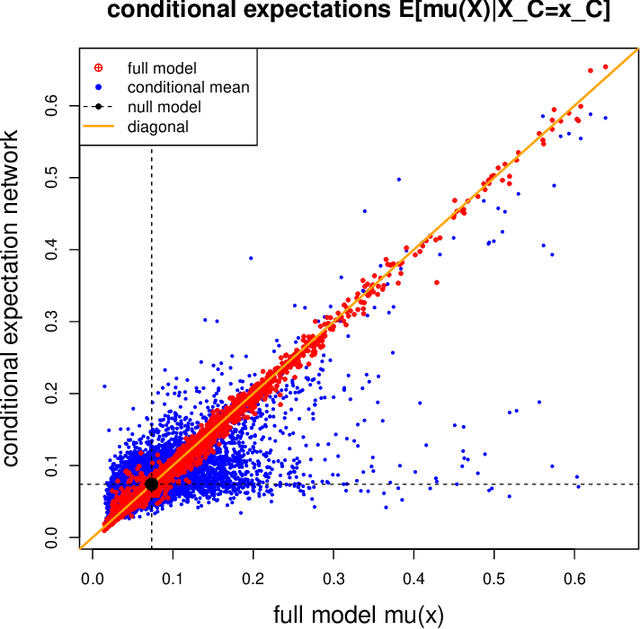
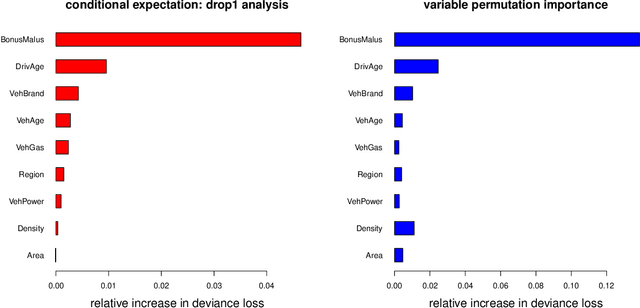
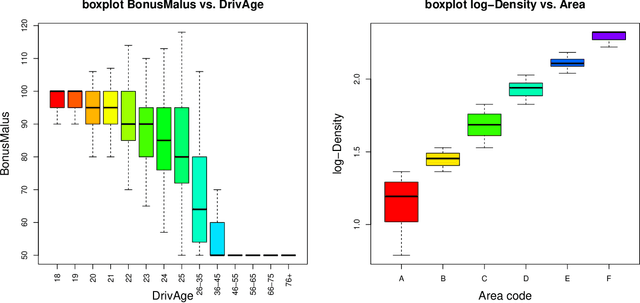
A very popular model-agnostic technique for explaining predictive models is the SHapley Additive exPlanation (SHAP). The two most popular versions of SHAP are a conditional expectation version and an unconditional expectation version (the latter is also known as interventional SHAP). Except for tree-based methods, usually the unconditional version is used (for computational reasons). We provide a (surrogate) neural network approach which allows us to efficiently calculate the conditional version for both neural networks and other regression models, and which properly considers the dependence structure in the feature components. This proposal is also useful to provide drop1 and anova analyses in complex regression models which are similar to their generalized linear model (GLM) counterparts, and we provide a partial dependence plot (PDP) counterpart that considers the right dependence structure in the feature components.
Smoothness and monotonicity constraints for neural networks using ICEnet
May 15, 2023Deep neural networks have become an important tool for use in actuarial tasks, due to the significant gains in accuracy provided by these techniques compared to traditional methods, but also due to the close connection of these models to the Generalized Linear Models (GLMs) currently used in industry. Whereas constraining GLM parameters relating to insurance risk factors to be smooth or exhibit monotonicity is trivial, methods to incorporate such constraints into deep neural networks have not yet been developed. This is a barrier for the adoption of neural networks in insurance practice since actuaries often impose these constraints for commercial or statistical reasons. In this work, we present a novel method for enforcing constraints within deep neural network models, and we show how these models can be trained. Moreover, we provide example applications using real-world datasets. We call our proposed method ICEnet to emphasize the close link of our proposal to the individual conditional expectation (ICE) model interpretability technique.
A Discussion of Discrimination and Fairness in Insurance Pricing
Sep 02, 2022Indirect discrimination is an issue of major concern in algorithmic models. This is particularly the case in insurance pricing where protected policyholder characteristics are not allowed to be used for insurance pricing. Simply disregarding protected policyholder information is not an appropriate solution because this still allows for the possibility of inferring the protected characteristics from the non-protected ones. This leads to so-called proxy or indirect discrimination. Though proxy discrimination is qualitatively different from the group fairness concepts in machine learning, these group fairness concepts are proposed to 'smooth out' the impact of protected characteristics in the calculation of insurance prices. The purpose of this note is to share some thoughts about group fairness concepts in the light of insurance pricing and to discuss their implications. We present a statistical model that is free of proxy discrimination, thus, unproblematic from an insurance pricing point of view. However, we find that the canonical price in this statistical model does not satisfy any of the three most popular group fairness axioms. This seems puzzling and we welcome feedback on our example and on the usefulness of these group fairness axioms for non-discriminatory insurance pricing.
A multi-task network approach for calculating discrimination-free insurance prices
Jul 06, 2022
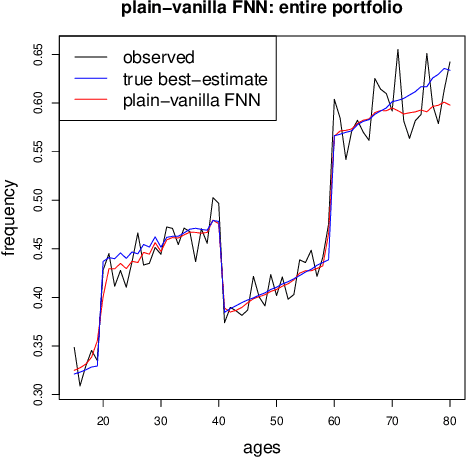
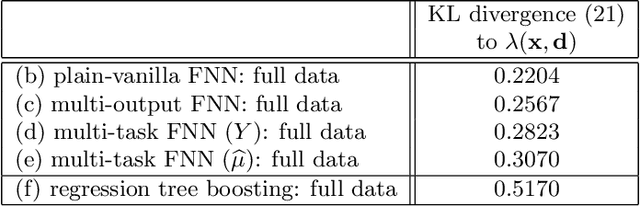
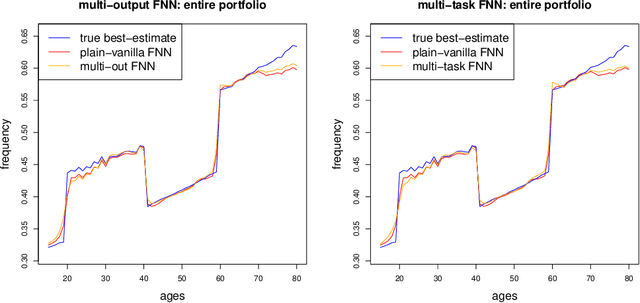
In applications of predictive modeling, such as insurance pricing, indirect or proxy discrimination is an issue of major concern. Namely, there exists the possibility that protected policyholder characteristics are implicitly inferred from non-protected ones by predictive models, and are thus having an undesirable (or illegal) impact on prices. A technical solution to this problem relies on building a best-estimate model using all policyholder characteristics (including protected ones) and then averaging out the protected characteristics for calculating individual prices. However, such approaches require full knowledge of policyholders' protected characteristics, which may in itself be problematic. Here, we address this issue by using a multi-task neural network architecture for claim predictions, which can be trained using only partial information on protected characteristics, and it produces prices that are free from proxy discrimination. We demonstrate the use of the proposed model and we find that its predictive accuracy is comparable to a conventional feedforward neural network (on full information). However, this multi-task network has clearly superior performance in the case of partially missing policyholder information.