 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Discussion of Discrimination and Fairness in Insurance Pricing
Sep 02, 2022Indirect discrimination is an issue of major concern in algorithmic models. This is particularly the case in insurance pricing where protected policyholder characteristics are not allowed to be used for insurance pricing. Simply disregarding protected policyholder information is not an appropriate solution because this still allows for the possibility of inferring the protected characteristics from the non-protected ones. This leads to so-called proxy or indirect discrimination. Though proxy discrimination is qualitatively different from the group fairness concepts in machine learning, these group fairness concepts are proposed to 'smooth out' the impact of protected characteristics in the calculation of insurance prices. The purpose of this note is to share some thoughts about group fairness concepts in the light of insurance pricing and to discuss their implications. We present a statistical model that is free of proxy discrimination, thus, unproblematic from an insurance pricing point of view. However, we find that the canonical price in this statistical model does not satisfy any of the three most popular group fairness axioms. This seems puzzling and we welcome feedback on our example and on the usefulness of these group fairness axioms for non-discriminatory insurance pricing.
A multi-task network approach for calculating discrimination-free insurance prices
Jul 06, 2022
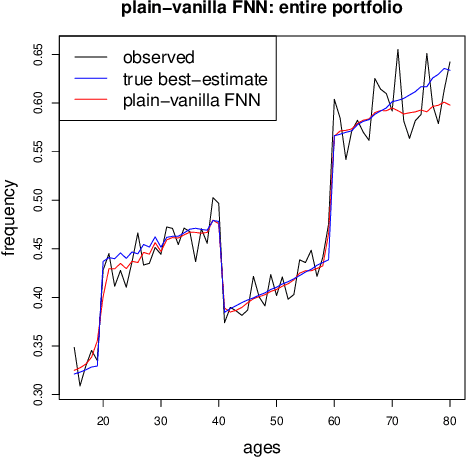
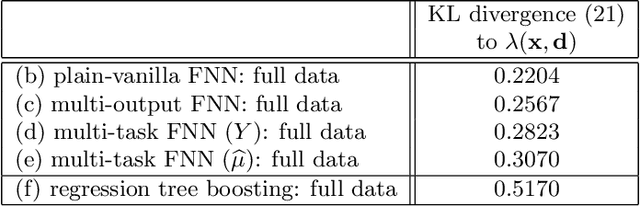
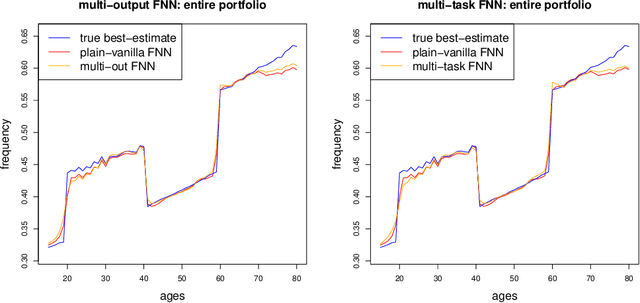
In applications of predictive modeling, such as insurance pricing, indirect or proxy discrimination is an issue of major concern. Namely, there exists the possibility that protected policyholder characteristics are implicitly inferred from non-protected ones by predictive models, and are thus having an undesirable (or illegal) impact on prices. A technical solution to this problem relies on building a best-estimate model using all policyholder characteristics (including protected ones) and then averaging out the protected characteristics for calculating individual prices. However, such approaches require full knowledge of policyholders' protected characteristics, which may in itself be problematic. Here, we address this issue by using a multi-task neural network architecture for claim predictions, which can be trained using only partial information on protected characteristics, and it produces prices that are free from proxy discrimination. We demonstrate the use of the proposed model and we find that its predictive accuracy is comparable to a conventional feedforward neural network (on full information). However, this multi-task network has clearly superior performance in the case of partially missing policyholder information.