 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Chain-Ladder to Individual Claims Reserving
Feb 17, 2026The chain-ladder (CL) method is the most widely used claims reserving technique in non-life insurance. This manuscript introduces a novel approach to computing the CL reserves based on a fundamental restructuring of the data utilization for the CL prediction procedure. Instead of rolling forward the cumulative claims with estimated CL factors, we estimate multi-period factors that project the latest observations directly to the ultimate claims. This alternative perspective on CL reserving creates a natural pathway for the application of machine learning techniques to individual claims reserving. As a proof of concept, we present a small-scale real data application employing neural networks for individual claims reserving.
Tab-TRM: Tiny Recursive Model for Insurance Pricing on Tabular Data
Jan 12, 2026We introduce Tab-TRM (Tabular-Tiny Recursive Model), a network architecture that adapts the recursive latent reasoning paradigm of Tiny Recursive Models (TRMs) to insurance modeling. Drawing inspiration from both the Hierarchical Reasoning Model (HRM) and its simplified successor TRM, the Tab-TRM model makes predictions by reasoning over the input features. It maintains two learnable latent tokens - an answer token and a reasoning state - that are iteratively refined by a compact, parameter-efficient recursive network. The recursive processing layer repeatedly updates the reasoning state given the full token sequence and then refines the answer token, in close analogy with iterative insurance pricing schemes. Conceptually, Tab-TRM bridges classical actuarial workflows - iterative generalized linear model fitting and minimum-bias calibration - on the one hand, and modern machine learning, in terms of Gradient Boosting Machines, on the other.
Gini Score under Ties and Case Weights
Nov 19, 2025The Gini score is a popular tool in statistical modeling and machine learning for model validation and model selection. It is a purely rank based score that allows one to assess risk rankings. The Gini score for statistical modeling has mainly been used in a binary context, in which it has many equivalent reformulations such as the receiver operating characteristic (ROC) or the area under the curve (AUC). In the actuarial literature, this rank based score for binary responses has been extended to general real-valued random variables using Lorenz curves and concentration curves. While these initial concepts assume that the risk ranking is generated by a continuous distribution function, we discuss in this paper how the Gini score can be used in the case of ties in the risk ranking. Moreover, we adapt the Gini score to the common actuarial situation of having case weights.
In-Context Learning Enhanced Credibility Transformer
Sep 09, 2025The starting point of our network architecture is the Credibility Transformer which extends the classical Transformer architecture by a credibility mechanism to improve model learning and predictive performance. This Credibility Transformer learns credibilitized CLS tokens that serve as learned representations of the original input features. In this paper we present a new paradigm that augments this architecture by an in-context learning mechanism, i.e., we increase the information set by a context batch consisting of similar instances. This allows the model to enhance the CLS token representations of the instances by additional in-context information and fine-tuning. We empirically verify that this in-context learning enhances predictive accuracy by adapting to similar risk patterns. Moreover, this in-context learning also allows the model to generalize to new instances which, e.g., have feature levels in the categorical covariates that have not been present when the model was trained -- for a relevant example, think of a new vehicle model which has just been developed by a car manufacturer.
Calibration Bands for Mean Estimates within the Exponential Dispersion Family
Mar 24, 2025A statistical model is said to be calibrated if the resulting mean estimates perfectly match the true means of the underlying responses. Aiming for calibration is often not achievable in practice as one has to deal with finite samples of noisy observations. A weaker notion of calibration is auto-calibration. An auto-calibrated model satisfies that the expected value of the responses being given the same mean estimate matches this estimate. Testing for auto-calibration has only been considered recently in the literature and we propose a new approach based on calibration bands. Calibration bands denote a set of lower and upper bounds such that the probability that the true means lie simultaneously inside those bounds exceeds some given confidence level. Such bands were constructed by Yang-Barber (2019) for sub-Gaussian distributions. Dimitriadis et al. (2023) then introduced narrower bands for the Bernoulli distribution and we use the same idea in order to extend the construction to the entire exponential dispersion family that contains for example the binomial, Poisson, negative binomial, gamma and normal distributions. Moreover, we show that the obtained calibration bands allow us to construct various tests for calibration and auto-calibration, respectively.
The Credibility Transformer
Sep 25, 2024
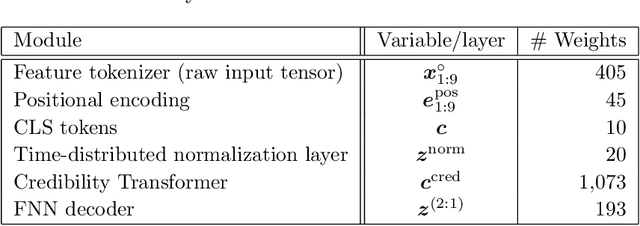
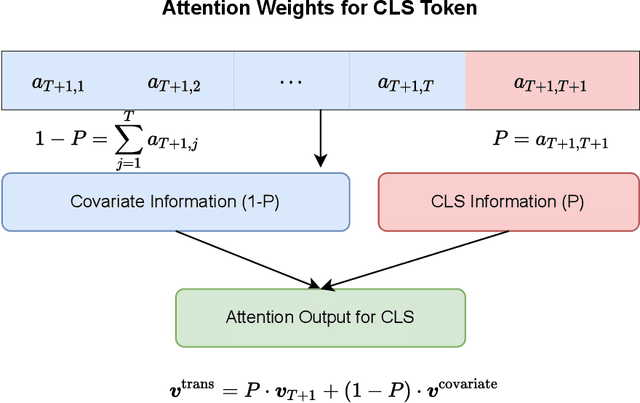
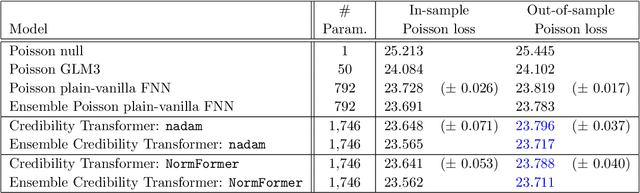
Inspired by the large success of Transformers in Large Language Models, these architectures are increasingly applied to tabular data. This is achieved by embedding tabular data into low-dimensional Euclidean spaces resulting in similar structures as time-series data. We introduce a novel credibility mechanism to this Transformer architecture. This credibility mechanism is based on a special token that should be seen as an encoder that consists of a credibility weighted average of prior information and observation based information. We demonstrate that this novel credibility mechanism is very beneficial to stabilize training, and our Credibility Transformer leads to predictive models that are superior to state-of-the-art deep learning models.
Conditional expectation network for SHAP
Jul 20, 2023
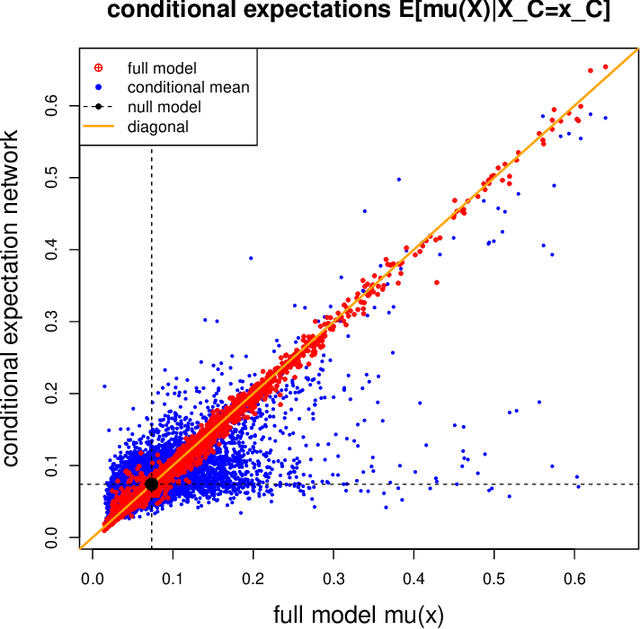
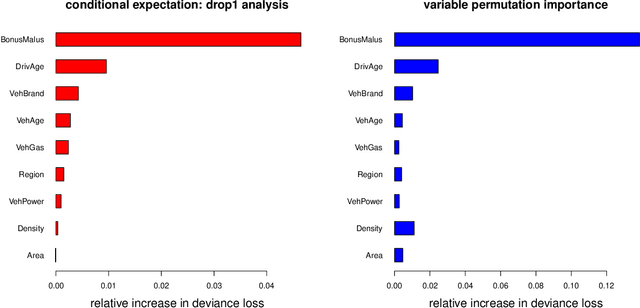
A very popular model-agnostic technique for explaining predictive models is the SHapley Additive exPlanation (SHAP). The two most popular versions of SHAP are a conditional expectation version and an unconditional expectation version (the latter is also known as interventional SHAP). Except for tree-based methods, usually the unconditional version is used (for computational reasons). We provide a (surrogate) neural network approach which allows us to efficiently calculate the conditional version for both neural networks and other regression models, and which properly considers the dependence structure in the feature components. This proposal is also useful to provide drop1 and anova analyses in complex regression models which are similar to their generalized linear model (GLM) counterparts, and we provide a partial dependence plot (PDP) counterpart that considers the right dependence structure in the feature components.
Isotonic Recalibration under a Low Signal-to-Noise Ratio
Jan 06, 2023Insurance pricing systems should fulfill the auto-calibration property to ensure that there is no systematic cross-financing between different price cohorts. Often, regression models are not auto-calibrated. We propose to apply isotonic recalibration to a given regression model to ensure auto-calibration. Our main result proves that under a low signal-to-noise ratio, this isotonic recalibration step leads to explainable pricing systems because the resulting isotonically recalibrated regression functions have a low complexity.
A Discussion of Discrimination and Fairness in Insurance Pricing
Sep 02, 2022Indirect discrimination is an issue of major concern in algorithmic models. This is particularly the case in insurance pricing where protected policyholder characteristics are not allowed to be used for insurance pricing. Simply disregarding protected policyholder information is not an appropriate solution because this still allows for the possibility of inferring the protected characteristics from the non-protected ones. This leads to so-called proxy or indirect discrimination. Though proxy discrimination is qualitatively different from the group fairness concepts in machine learning, these group fairness concepts are proposed to 'smooth out' the impact of protected characteristics in the calculation of insurance prices. The purpose of this note is to share some thoughts about group fairness concepts in the light of insurance pricing and to discuss their implications. We present a statistical model that is free of proxy discrimination, thus, unproblematic from an insurance pricing point of view. However, we find that the canonical price in this statistical model does not satisfy any of the three most popular group fairness axioms. This seems puzzling and we welcome feedback on our example and on the usefulness of these group fairness axioms for non-discriminatory insurance pricing.
Model selection with Gini indices under auto-calibration
Aug 10, 2022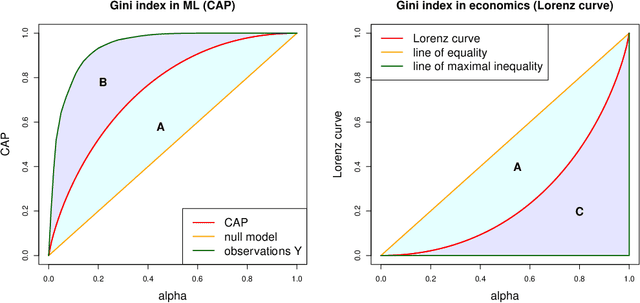
The Gini index does not give a strictly consistent scoring rule in general. Therefore, maximizing the Gini index may lead to wrong decisions. The main issue is that the Gini index is a rank-based score that is not calibration-sensitive. We show that the Gini index allows for strictly consistent scoring if we restrict to the class of auto-calibrated regression models.