 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory of PAC Learnability of Partial Concept Classes
Jul 20, 2021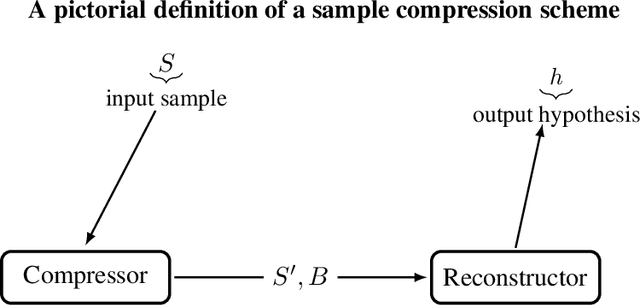
We extend the theory of PAC learning in a way which allows to model a rich variety of learning tasks where the data satisfy special properties that ease the learning process. For example, tasks where the distance of the data from the decision boundary is bounded away from zero. The basic and simple idea is to consider partial concepts: these are functions that can be undefined on certain parts of the space. When learning a partial concept, we assume that the source distribution is supported only on points where the partial concept is defined. This way, one can naturally express assumptions on the data such as lying on a lower dimensional surface or margin conditions. In contrast, it is not at all clear that such assumptions can be expressed by the traditional PAC theory. In fact we exhibit easy-to-learn partial concept classes which provably cannot be captured by the traditional PAC theory. This also resolves a question posed by Attias, Kontorovich, and Mansour 2019. We characterize PAC learnability of partial concept classes and reveal an algorithmic landscape which is fundamentally different than the classical one. For example, in the classical PAC model, learning boils down to Empirical Risk Minimization (ERM). In stark contrast, we show that the ERM principle fails in explaining learnability of partial concept classes. In fact, we demonstrate classes that are incredibly easy to learn, but such that any algorithm that learns them must use an hypothesis space with unbounded VC dimension. We also find that the sample compression conjecture fails in this setting. Thus, this theory features problems that cannot be represented nor solved in the traditional way. We view this as evidence that it might provide insights on the nature of learnability in realistic scenarios which the classical theory fails to explain.