 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Asynchronous and Sparse Human-Object Interaction in Videos
Mar 03, 2021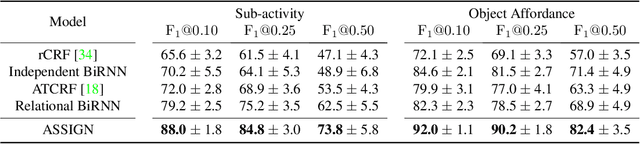
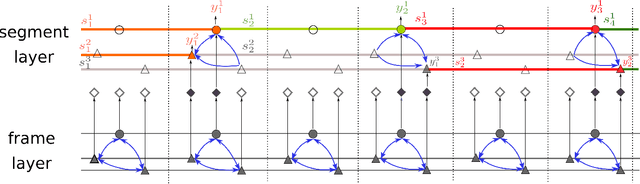

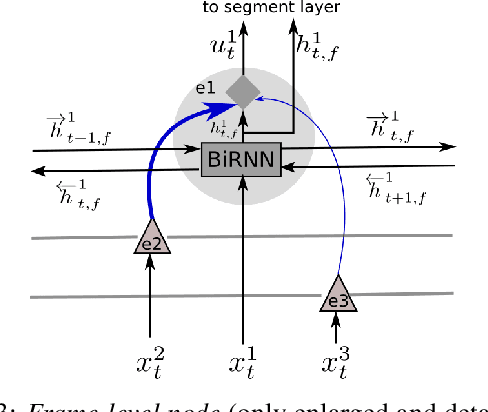
Human activities can be learned from video. With effective modeling it is possible to discover not only the action labels but also the temporal structures of the activities such as the progression of the sub-activities. Automatically recognizing such structure from raw video signal is a new capability that promises authentic modeling and successful recognition of human-object interactions. Toward this goal, we introduce Asynchronous-Sparse Interaction Graph Networks (ASSIGN), a recurrent graph network that is able to automatically detect the structure of interaction events associated with entities in a video scene. ASSIGN pioneers learning of autonomous behavior of video entities including their dynamic structure and their interaction with the coexisting neighbors. Entities' lives in our model are asynchronous to those of others therefore more flexible in adaptation to complex scenarios. Their interactions are sparse in time hence more faithful to the true underlying nature and more robust in inference and learning. ASSIGN is tested on human-object interaction recognition and shows superior performance in segmenting and labeling of human sub-activities and object affordances from raw videos. The native ability for discovering temporal structures of the model also eliminates the dependence on external segmentation that was previously mandatory for this task.
Learning to Abstract and Predict Human Actions
Aug 20, 2020



Human activities are naturally structured as hierarchies unrolled over time. For action prediction, temporal relations in event sequences are widely exploited by current methods while their semantic coherence across different levels of abstraction has not been well explored. In this work we model the hierarchical structure of human activities in videos and demonstrate the power of such structure in action prediction. We propose Hierarchical Encoder-Refresher-Anticipator, a multi-level neural machine that can learn the structure of human activities by observing a partial hierarchy of events and roll-out such structure into a future prediction in multiple levels of abstraction. We also introduce a new coarse-to-fine action annotation on the Breakfast Actions videos to create a comprehensive, consistent, and cleanly structured video hierarchical activity dataset. Through our experiments, we examine and rethink the settings and metrics of activity prediction tasks toward unbiased evaluation of prediction systems, and demonstrate the role of hierarchical modeling toward reliable and detailed long-term action forecasting.
Learning Regularity in Skeleton Trajectories for Anomaly Detection in Videos
Mar 08, 2019


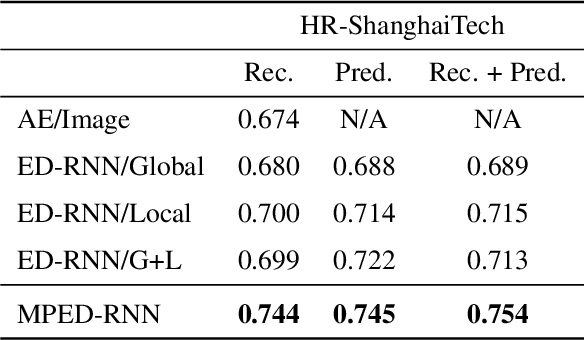
Appearance features have been widely used in video anomaly detection even though they contain complex entangled factors. We propose a new method to model the normal patterns of human movements in surveillance video for anomaly detection using dynamic skeleton features. We decompose the skeletal movements into two sub-components: global body movement and local body posture. We model the dynamics and interaction of the coupled features in our novel Message-Passing Encoder-Decoder Recurrent Network. We observed that the decoupled features collaboratively interact in our spatio-temporal model to accurately identify human-related irregular events from surveillance video sequences. Compared to traditional appearance-based models, our method achieves superior outlier detection performance. Our model also offers "open-box" examination and decision explanation made possible by the semantically understandable features and a network architecture supporting interpretability.