 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Language and Speech Features for Cognitive-Linguistic Assessment
Jun 04, 2019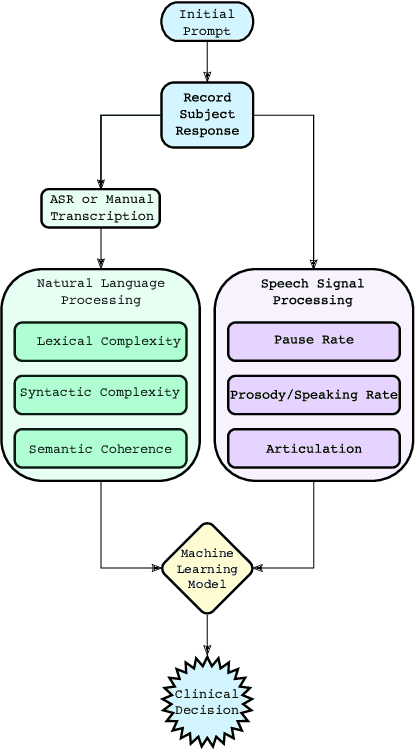

It is widely accepted that information derived from analyzing speech (the acoustic signal) and language production (words and sentences) serves as a useful window into the health of an individual's cognitive ability. In fact, most neuropsychological batteries used in cognitive assessment have a component related to speech and language where clinicians elicit speech from patients for subjective evaluation across a broad set of dimensions. With advances in speech signal processing and natural language processing, there has been recent interest in developing tools to detect more subtle changes in cognitive-linguistic function. This work relies on extracting a set of features from recorded and transcribed speech for objective assessments of cognition, early diagnosis of neurological disease, and objective tracking of disease after diagnosis. In this paper we provide a review of existing speech and language features used in this domain, discuss their clinical application, and highlight their advantages and disadvantages. Broadly speaking, the review is split into two categories: language features based on natural language processing and speech features based on speech signal processing. Within each category, we consider features that aim to measure complementary dimensions of cognitive-linguistics, including language diversity, syntactic complexity, semantic coherence, and timing. We conclude the review with a proposal of new research directions to further advance the field.
Objective Assessment of Social Skills Using Automated Language Analysis for Identification of Schizophrenia and Bipolar Disorder
Apr 24, 2019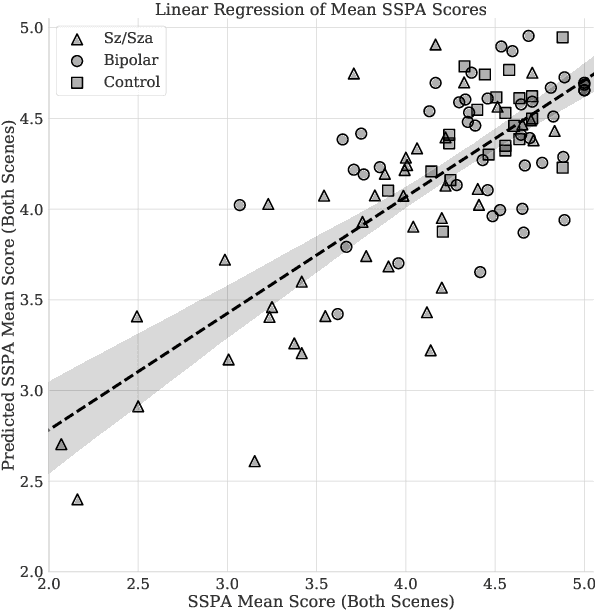

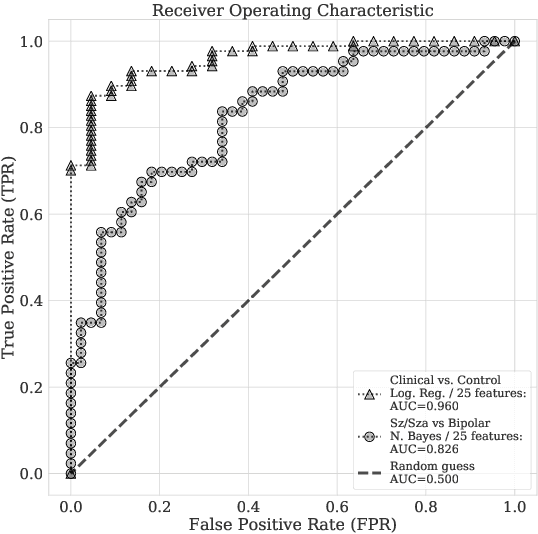
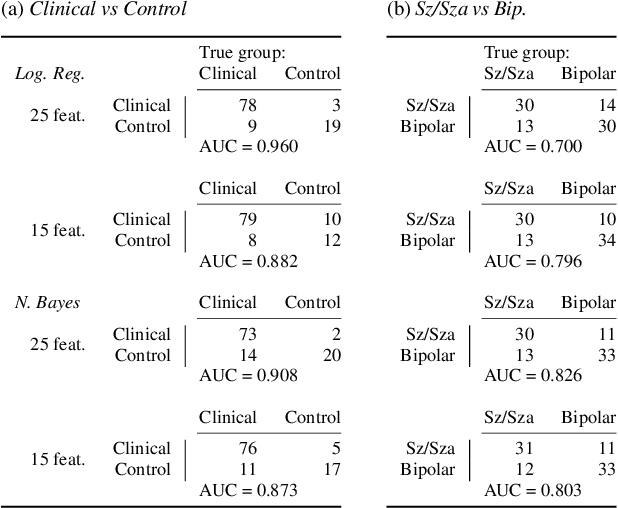
Several studies have shown that speech and language features, automatically extracted from clinical interviews or spontaneous discourse, have diagnostic value for mental disorders such as schizophrenia and bipolar disorder. They typically make use of a large feature set to train a classifier for distinguishing between two groups of interest, i.e. a clinical and control group. However, a purely data-driven approach runs the risk of overfitting to a particular data set, especially when sample sizes are limited. Here, we first down-select the set of language features to a small subset that is related to a well-validated test of functional ability, the Social Skills Performance Assessment (SSPA). This helps establish the concurrent validity of the selected features. We use only these features to train a simple classifier to distinguish between groups of interest. Linear regression reveals that a subset of language features can effectively model the SSPA, with a correlation coefficient of 0.75. Furthermore, the same feature set can be used to build a strong binary classifier to distinguish between healthy controls and a clinical group (AUC = 0.96) and also between patients within the clinical group with schizophrenia and bipolar I disorder (AUC = 0.83).
Investigating the Effects of Word Substitution Errors on Sentence Embeddings
Nov 16, 2018
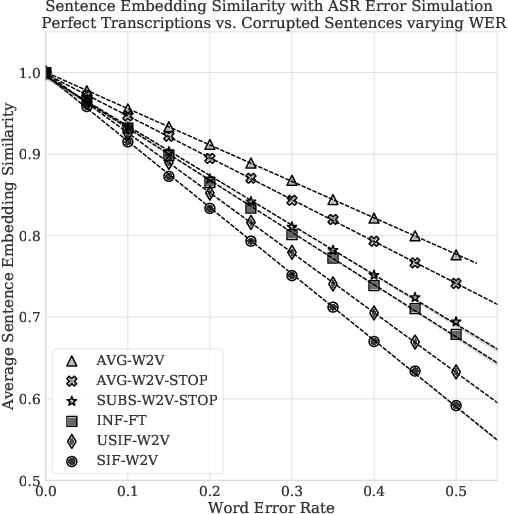

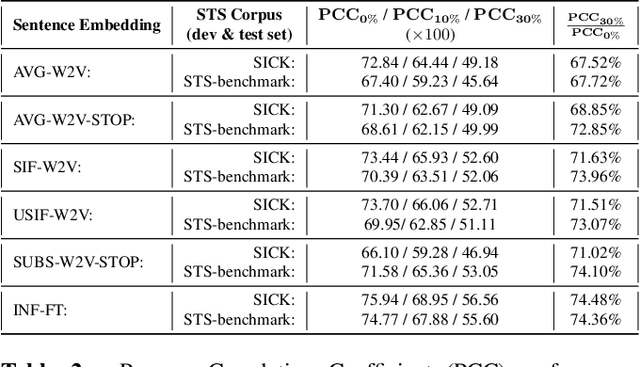
A key initial step in several natural language processing (NLP) tasks involves embedding phrases of text to vectors of real numbers that preserve semantic meaning. To that end, several methods have been recently proposed with impressive results on semantic similarity tasks. However, all of these approaches assume that perfect transcripts are available when generating the embeddings. While this is a reasonable assumption for analysis of written text, it is limiting for analysis of transcribed text. In this paper we investigate the effects of word substitution errors, such as those coming from automatic speech recognition errors (ASR), on several state-of-the-art sentence embedding methods. To do this, we propose a new simulator that allows the experimenter to induce ASR-plausible word substitution errors in a corpus at a desired word error rate. We use this simulator to evaluate the robustness of several sentence embedding methods. Our results show that pre-trained encoders such as InferSent [1] are both robust to ASR errors and perform well on textual similarity tasks after errors are introduced. Meanwhile, unweighted averages perform well with perfect transcriptions, but their performance degrades rapidly on textual similarity tasks for text with word substitution errors.