 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjective Assessment of Social Skills Using Automated Language Analysis for Identification of Schizophrenia and Bipolar Disorder
Paper and Code
Apr 24, 2019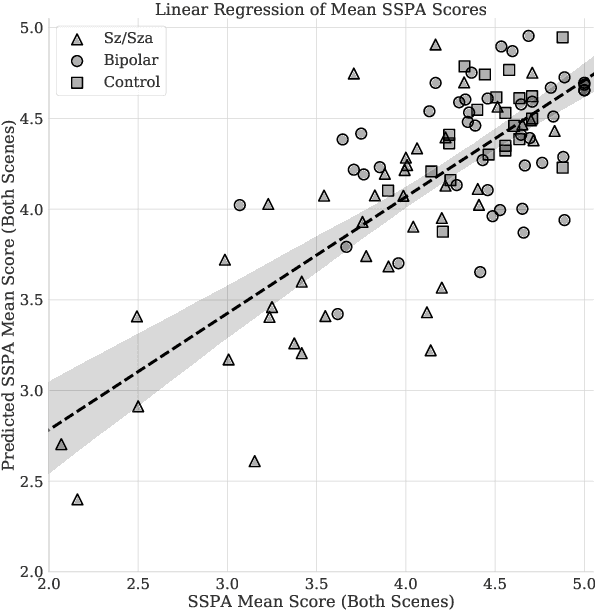

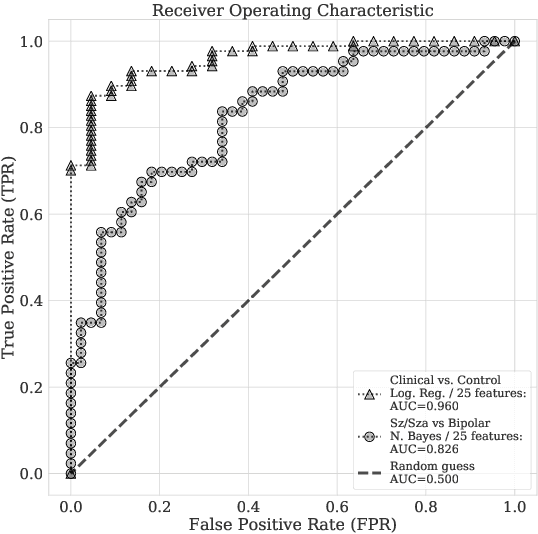
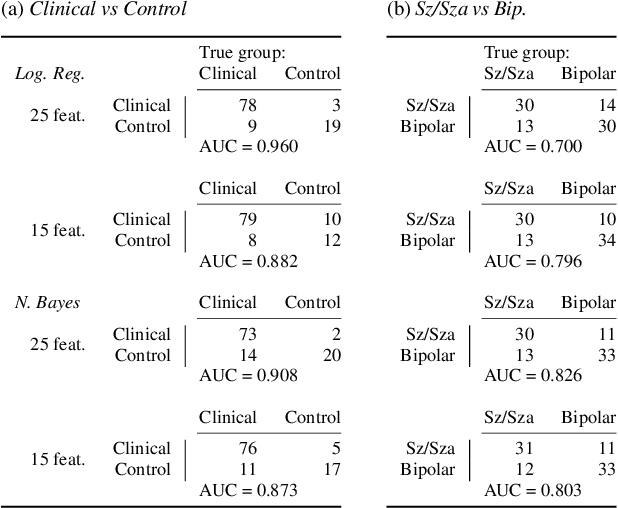
Several studies have shown that speech and language features, automatically extracted from clinical interviews or spontaneous discourse, have diagnostic value for mental disorders such as schizophrenia and bipolar disorder. They typically make use of a large feature set to train a classifier for distinguishing between two groups of interest, i.e. a clinical and control group. However, a purely data-driven approach runs the risk of overfitting to a particular data set, especially when sample sizes are limited. Here, we first down-select the set of language features to a small subset that is related to a well-validated test of functional ability, the Social Skills Performance Assessment (SSPA). This helps establish the concurrent validity of the selected features. We use only these features to train a simple classifier to distinguish between groups of interest. Linear regression reveals that a subset of language features can effectively model the SSPA, with a correlation coefficient of 0.75. Furthermore, the same feature set can be used to build a strong binary classifier to distinguish between healthy controls and a clinical group (AUC = 0.96) and also between patients within the clinical group with schizophrenia and bipolar I disorder (AUC = 0.83).