 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effects of Word Substitution Errors on Sentence Embeddings
Paper and Code

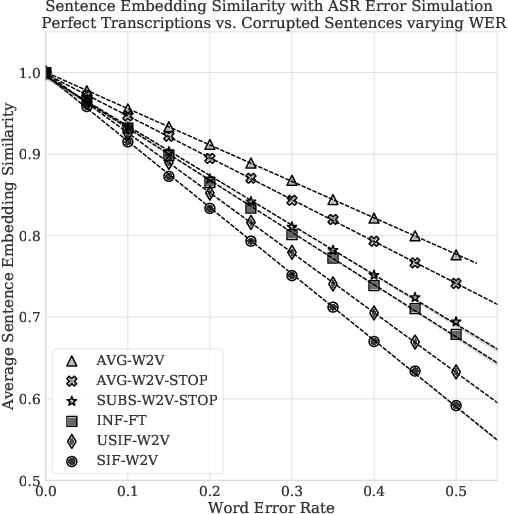

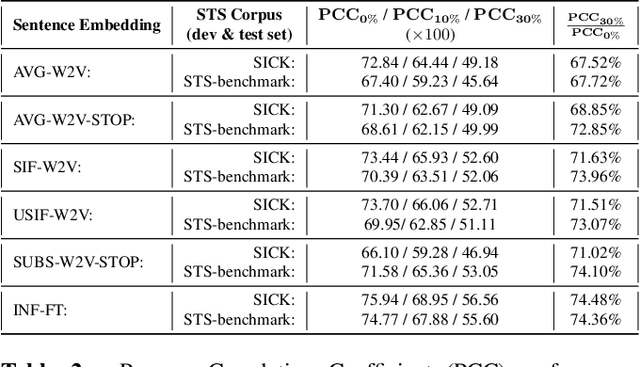
A key initial step in several natural language processing (NLP) tasks involves embedding phrases of text to vectors of real numbers that preserve semantic meaning. To that end, several methods have been recently proposed with impressive results on semantic similarity tasks. However, all of these approaches assume that perfect transcripts are available when generating the embeddings. While this is a reasonable assumption for analysis of written text, it is limiting for analysis of transcribed text. In this paper we investigate the effects of word substitution errors, such as those coming from automatic speech recognition errors (ASR), on several state-of-the-art sentence embedding methods. To do this, we propose a new simulator that allows the experimenter to induce ASR-plausible word substitution errors in a corpus at a desired word error rate. We use this simulator to evaluate the robustness of several sentence embedding methods. Our results show that pre-trained encoders such as InferSent [1] are both robust to ASR errors and perform well on textual similarity tasks after errors are introduced. Meanwhile, unweighted averages perform well with perfect transcriptions, but their performance degrades rapidly on textual similarity tasks for text with word substitution errors.