 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndebted households profiling: a knowledge discovery from database approach
Jul 20, 2016
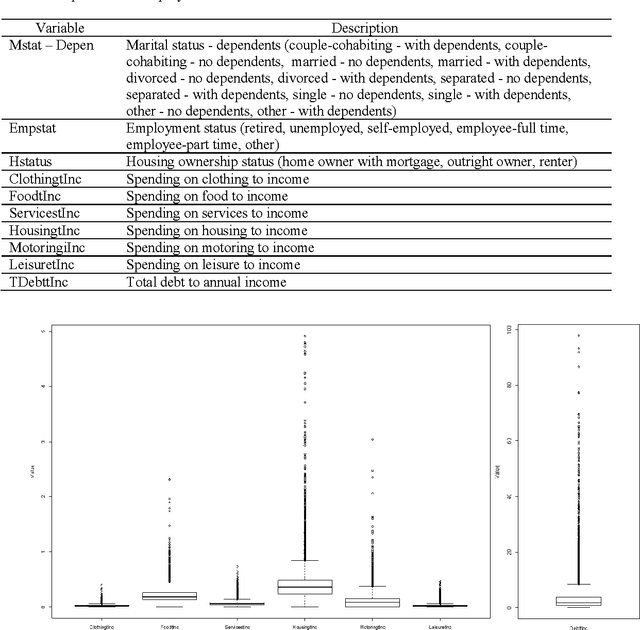


A major challenge in consumer credit risk portfolio management is to classify households according to their risk profile. In order to build such risk profiles it is necessary to employ an approach that analyses data systematically in order to detect important relationships, interactions, dependencies and associations amongst the available continuous and categorical variables altogether and accurately generate profiles of most interesting household segments according to their credit risk. The objective of this work is to employ a knowledge discovery from database process to identify groups of indebted households and describe their profiles using a database collected by the Consumer Credit Counselling Service (CCCS) in the UK. Employing a framework that allows the usage of both categorical and continuous data altogether to find hidden structures in unlabelled data it was established the ideal number of clusters and such clusters were described in order to identify the households who exhibit a high propensity of excessive debt levels.
Augmented Neural Networks for Modelling Consumer Indebtness
Sep 03, 2014
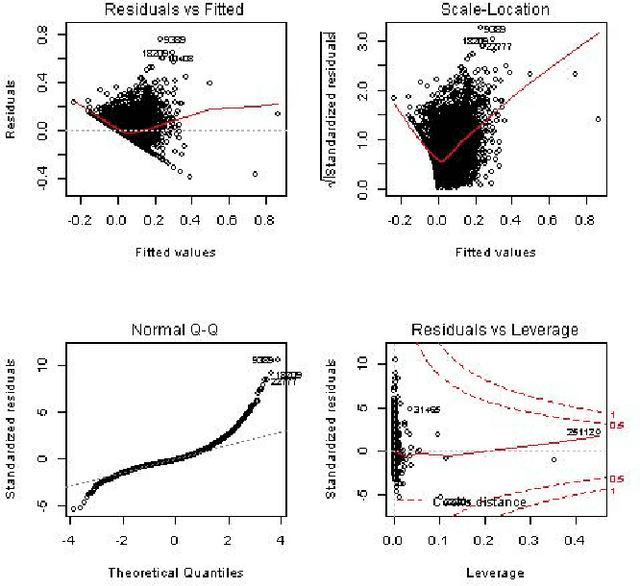
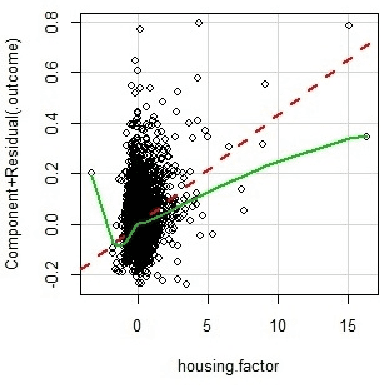
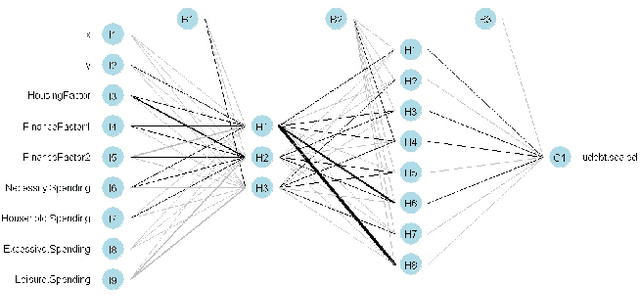
Consumer Debt has risen to be an important problem of modern societies, generating a lot of research in order to understand the nature of consumer indebtness, which so far its modelling has been carried out by statistical models. In this work we show that Computational Intelligence can offer a more holistic approach that is more suitable for the complex relationships an indebtness dataset has and Linear Regression cannot uncover. In particular, as our results show, Neural Networks achieve the best performance in modelling consumer indebtness, especially when they manage to incorporate the significant and experimentally verified results of the Data Mining process in the model, exploiting the flexibility Neural Networks offer in designing their topology. This novel method forms an elaborate framework to model Consumer indebtness that can be extended to any other real world application.