 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Maximum Entropy approach to Massive Graph Spectra
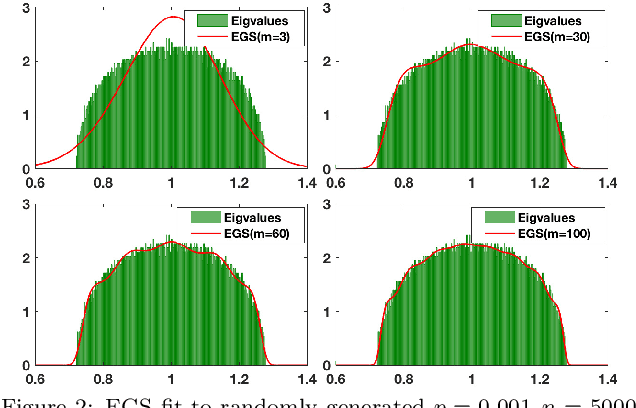
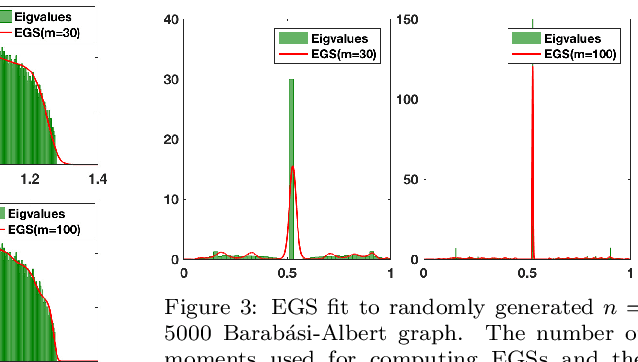
Dec 19, 2019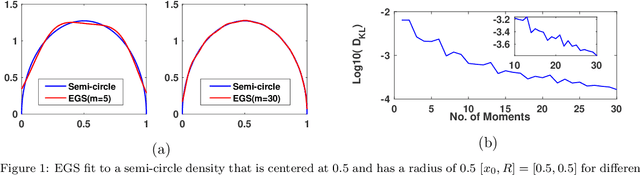

Graph spectral techniques for measuring graph similarity, or for learning the cluster number, require kernel smoothing. The choice of kernel function and bandwidth are typically chosen in an ad-hoc manner and heavily affect the resulting output. We prove that kernel smoothing biases the moments of the spectral density. We propose an information theoretically optimal approach to learn a smooth graph spectral density, which fully respects the moment information. Our method's computational cost is linear in the number of edges, and hence can be applied to large networks, with millions of nodes. We apply our method to the problems to graph similarity and cluster number learning, where we outperform comparable iterative spectral approaches on synthetic and real graphs.