 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Demographic Bias in Facial Landmark Detection for Fair Human-Robot Interaction
Apr 08, 2026Fairness in human-robot interaction critically depends on the reliability of the perceptual models that enable robots to interpret human behavior. While demographic biases have been widely studied in high-level facial analysis tasks, their presence in facial landmark detection remains unexplored. In this paper, we conduct a systematic audit of demographic bias in this task, analyzing the age, gender and race biases. To this end we introduce a controlled statistical methodology to disentangle demographic effects from confounding visual factors. Evaluations of a standard representative model demonstrate that confounding visual factors, particularly head pose and image resolution, heavily outweigh the impact of demographic attributes. Notably, after accounting for these confounders, we show that performance disparities across gender and race vanish. However, we identify a statistically significant age-related effect, with higher biases observed for older individuals. This shows that fairness issues can emerge even in low-level vision components and can propagate through the HRI pipeline, disproportionately affecting vulnerable populations. We argue that auditing and correcting such biases is a necessary step toward trustworthy and equitable robot perception systems.
Pose-guided multi-task video transformer for driver action recognition
Jul 18, 2024We investigate the task of identifying situations of distracted driving through analysis of in-car videos. To tackle this challenge we introduce a multi-task video transformer that predicts both distracted actions and driver pose. Leveraging VideoMAEv2, a large pre-trained architecture, our approach incorporates semantic information from human keypoint locations to enhance action recognition and decrease computational overhead by minimizing the number of spatio-temporal tokens. By guiding token selection with pose and class information, we notably reduce the model's computational requirements while preserving the baseline accuracy. Our model surpasses existing state-of-the art results in driver action recognition while exhibiting superior efficiency compared to current video transformer-based approaches.
On the representation and methodology for wide and short range head pose estimation
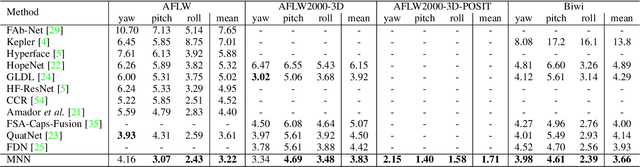
Jan 11, 2024Head pose estimation (HPE) is a problem of interest in computer vision to improve the performance of face processing tasks in semi-frontal or profile settings. Recent applications require the analysis of faces in the full 360{\deg} rotation range. Traditional approaches to solve the semi-frontal and profile cases are not directly amenable for the full rotation case. In this paper we analyze the methodology for short- and wide-range HPE and discuss which representations and metrics are adequate for each case. We show that the popular Euler angles representation is a good choice for short-range HPE, but not at extreme rotations. However, the Euler angles' gimbal lock problem prevents them from being used as a valid metric in any setting. We also revisit the current cross-data set evaluation methodology and note that the lack of alignment between the reference systems of the training and test data sets negatively biases the results of all articles in the literature. We introduce a procedure to quantify this misalignment and a new methodology for cross-data set HPE that establishes new, more accurate, SOTA for the 300W-LP|Biwi benchmark. We also propose a generalization of the geodesic angular distance metric that enables the construction of a loss that controls the contribution of each training sample to the optimization of the model. Finally, we introduce a wide range HPE benchmark based on the CMU Panoptic data set.
Multi-task head pose estimation in-the-wild
Feb 04, 2022
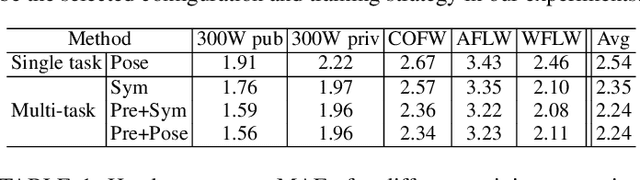
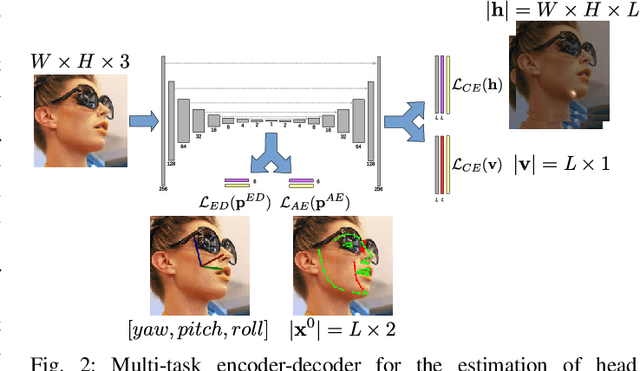
We present a deep learning-based multi-task approach for head pose estimation in images. We contribute with a network architecture and training strategy that harness the strong dependencies among face pose, alignment and visibility, to produce a top performing model for all three tasks. Our architecture is an encoder-decoder CNN with residual blocks and lateral skip connections. We show that the combination of head pose estimation and landmark-based face alignment significantly improve the performance of the former task. Further, the location of the pose task at the bottleneck layer, at the end of the encoder, and that of tasks depending on spatial information, such as visibility and alignment, in the final decoder layer, also contribute to increase the final performance. In the experiments conducted the proposed model outperforms the state-of-the-art in the face pose and visibility tasks. By including a final landmark regression step it also produces face alignment results on par with the state-of-the-art.
Face Alignment using a 3D Deeply-initialized Ensemble of Regression Trees
Feb 05, 2019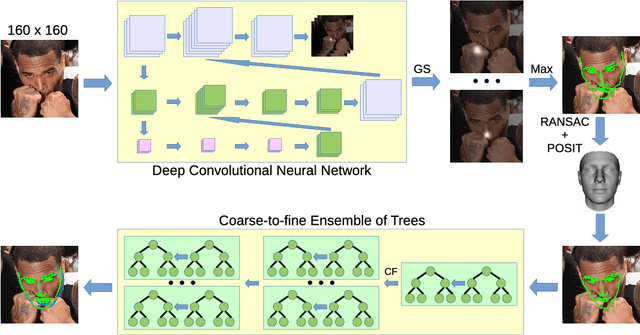



Face alignment algorithms locate a set of landmark points in images of faces taken in unrestricted situations. State-of-the-art approaches typically fail or lose accuracy in the presence of occlusions, strong deformations, large pose variations and ambiguous configurations. In this paper we present 3DDE, a robust and efficient face alignment algorithm based on a coarse-to-fine cascade of ensembles of regression trees. It is initialized by robustly fitting a 3D face model to the probability maps produced by a convolutional neural network. With this initialization we address self-occlusions and large face rotations. Further, the regressor implicitly imposes a prior face shape on the solution, addressing occlusions and ambiguous face configurations. Its coarse-to-fine structure tackles the combinatorial explosion of parts deformation. In the experiments performed, 3DDE improves the state-of-the-art in 300W, COFW, AFLW and WFLW data sets. Finally, given that 3DDE can also be trained with missing and occluded landmarks, we have been able to perform cross-dataset experiments that reveal the existence of a significant data set bias in these benchmarks.