 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task head pose estimation in-the-wild
Feb 04, 2022
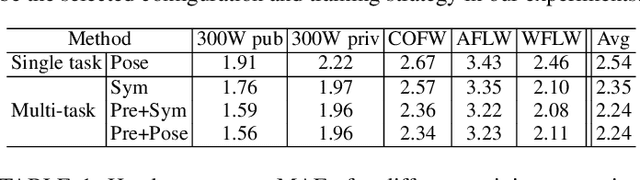
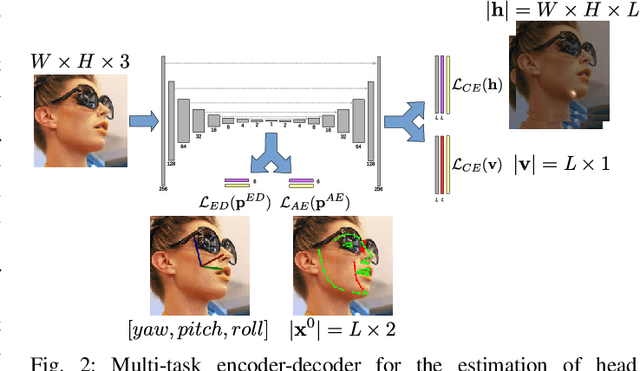
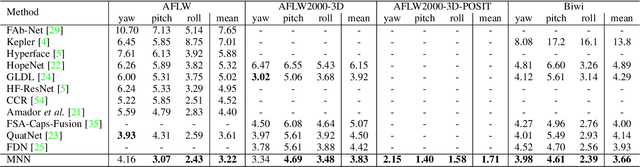
We present a deep learning-based multi-task approach for head pose estimation in images. We contribute with a network architecture and training strategy that harness the strong dependencies among face pose, alignment and visibility, to produce a top performing model for all three tasks. Our architecture is an encoder-decoder CNN with residual blocks and lateral skip connections. We show that the combination of head pose estimation and landmark-based face alignment significantly improve the performance of the former task. Further, the location of the pose task at the bottleneck layer, at the end of the encoder, and that of tasks depending on spatial information, such as visibility and alignment, in the final decoder layer, also contribute to increase the final performance. In the experiments conducted the proposed model outperforms the state-of-the-art in the face pose and visibility tasks. By including a final landmark regression step it also produces face alignment results on par with the state-of-the-art.