 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye-SpatialNet: Spatial Information Extraction from Ophthalmology Notes
May 19, 2023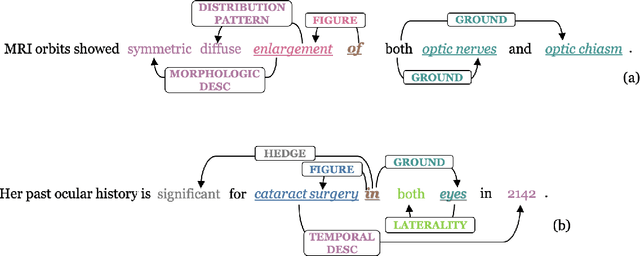



We introduce an annotated corpus of 600 ophthalmology notes labeled with detailed spatial and contextual information of ophthalmic entities. We extend our previously proposed frame semantics-based spatial representation schema, Rad-SpatialNet, to represent spatial language in ophthalmology text, resulting in the Eye-SpatialNet schema. The spatially-grounded entities are findings, procedures, and drugs. To accurately capture all spatial details, we add some domain-specific elements in Eye-SpatialNet. The annotated corpus contains 1715 spatial triggers, 7308 findings, 2424 anatomies, and 9914 descriptors. To automatically extract the spatial information, we employ a two-turn question answering approach based on the transformer language model BERT. The results are promising, with F1 scores of 89.31, 74.86, and 88.47 for spatial triggers, Figure, and Ground frame elements, respectively. This is the first work to represent and extract a wide variety of clinical information in ophthalmology. Extracting detailed information can benefit ophthalmology applications and research targeted toward disease progression and screening.