 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBluff: Interactively Deciphering Adversarial Attacks on Deep Neural Networks
Sep 08, 2020
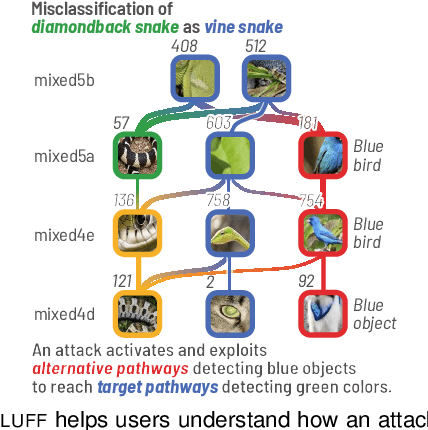
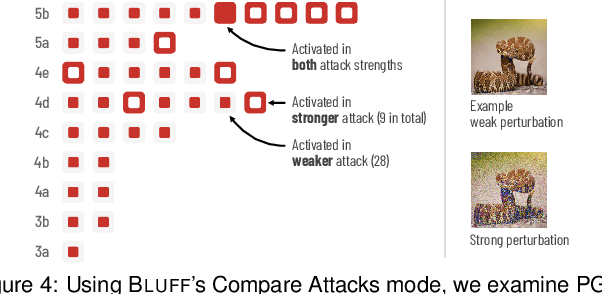
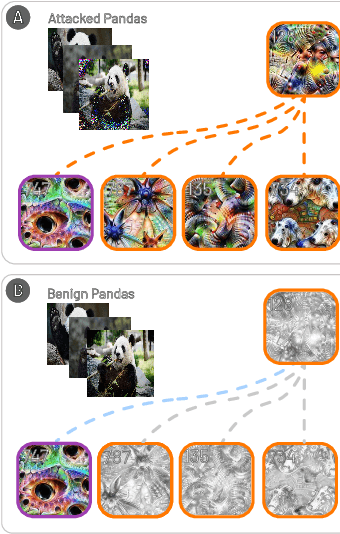
Deep neural networks (DNNs) are now commonly used in many domains. However, they are vulnerable to adversarial attacks: carefully crafted perturbations on data inputs that can fool a model into making incorrect predictions. Despite significant research on developing DNN attack and defense techniques, people still lack an understanding of how such attacks penetrate a model's internals. We present Bluff, an interactive system for visualizing, characterizing, and deciphering adversarial attacks on vision-based neural networks. Bluff allows people to flexibly visualize and compare the activation pathways for benign and attacked images, revealing mechanisms that adversarial attacks employ to inflict harm on a model. Bluff is open-sourced and runs in modern web browsers.
Massif: Interactive Interpretation of Adversarial Attacks on Deep Learning
Feb 16, 2020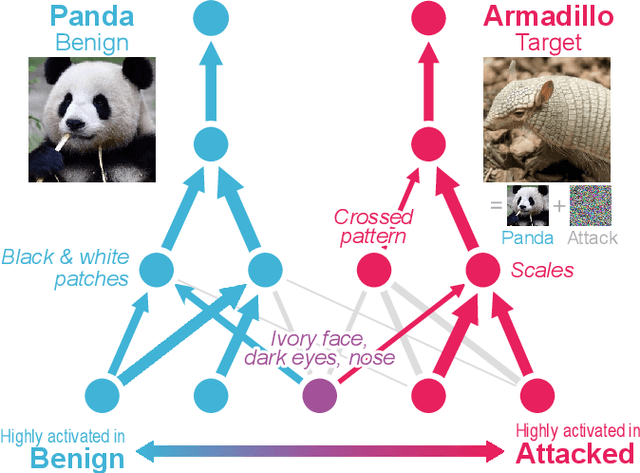
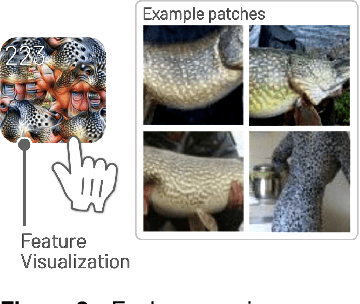
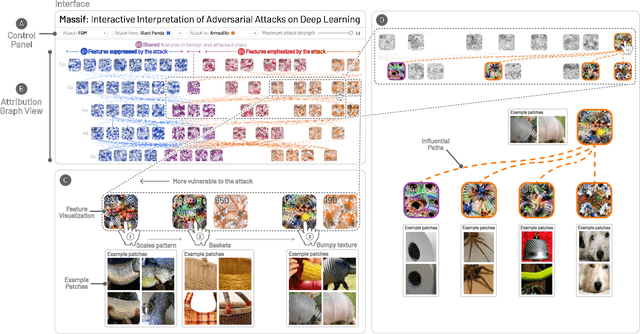
Deep neural networks (DNNs) are increasingly powering high-stakes applications such as autonomous cars and healthcare; however, DNNs are often treated as "black boxes" in such applications. Recent research has also revealed that DNNs are highly vulnerable to adversarial attacks, raising serious concerns over deploying DNNs in the real world. To overcome these deficiencies, we are developing Massif, an interactive tool for deciphering adversarial attacks. Massif identifies and interactively visualizes neurons and their connections inside a DNN that are strongly activated or suppressed by an adversarial attack. Massif provides both a high-level, interpretable overview of the effect of an attack on a DNN, and a low-level, detailed description of the affected neurons. These tightly coupled views in Massif help people better understand which input features are most vulnerable or important for correct predictions.