 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeightless: Lossy Weight Encoding For Deep Neural Network Compression
Nov 13, 2017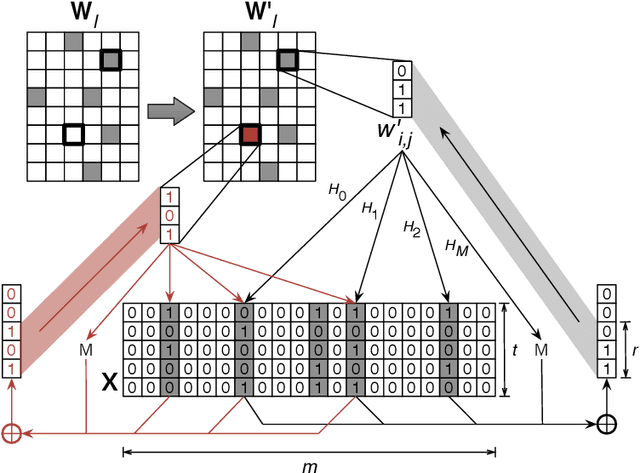
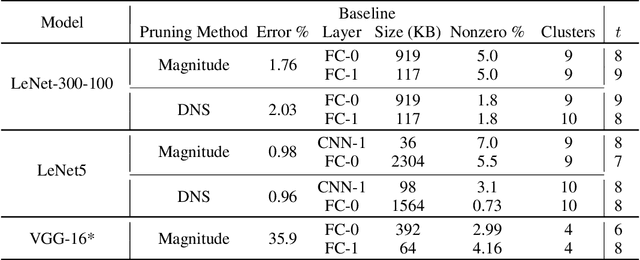

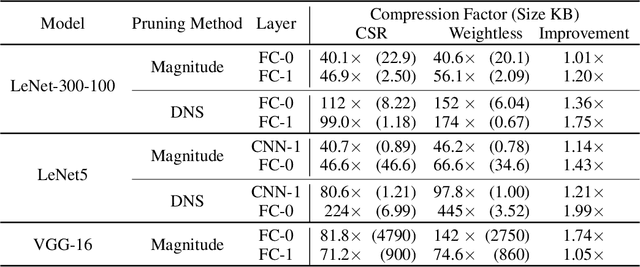
The large memory requirements of deep neural networks limit their deployment and adoption on many devices. Model compression methods effectively reduce the memory requirements of these models, usually through applying transformations such as weight pruning or quantization. In this paper, we present a novel scheme for lossy weight encoding which complements conventional compression techniques. The encoding is based on the Bloomier filter, a probabilistic data structure that can save space at the cost of introducing random errors. Leveraging the ability of neural networks to tolerate these imperfections and by re-training around the errors, the proposed technique, Weightless, can compress DNN weights by up to 496x with the same model accuracy. This results in up to a 1.51x improvement over the state-of-the-art.
Fathom: Reference Workloads for Modern Deep Learning Methods
Aug 23, 2016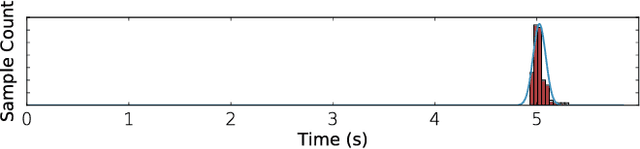
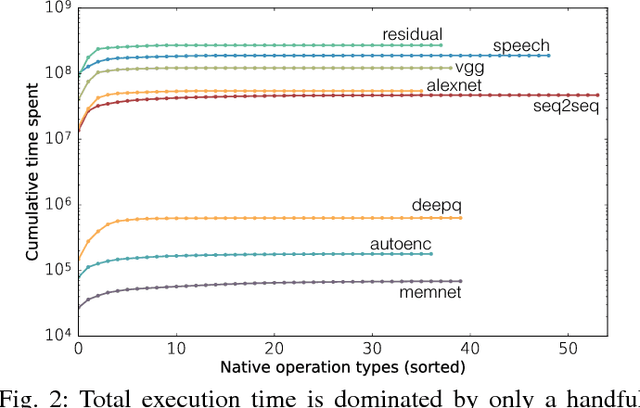

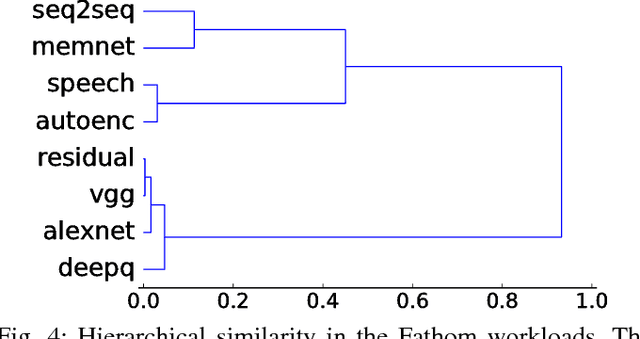
Deep learning has been popularized by its recent successes on challenging artificial intelligence problems. One of the reasons for its dominance is also an ongoing challenge: the need for immense amounts of computational power. Hardware architects have responded by proposing a wide array of promising ideas, but to date, the majority of the work has focused on specific algorithms in somewhat narrow application domains. While their specificity does not diminish these approaches, there is a clear need for more flexible solutions. We believe the first step is to examine the characteristics of cutting edge models from across the deep learning community. Consequently, we have assembled Fathom: a collection of eight archetypal deep learning workloads for study. Each of these models comes from a seminal work in the deep learning community, ranging from the familiar deep convolutional neural network of Krizhevsky et al., to the more exotic memory networks from Facebook's AI research group. Fathom has been released online, and this paper focuses on understanding the fundamental performance characteristics of each model. We use a set of application-level modeling tools built around the TensorFlow deep learning framework in order to analyze the behavior of the Fathom workloads. We present a breakdown of where time is spent, the similarities between the performance profiles of our models, an analysis of behavior in inference and training, and the effects of parallelism on scaling.