 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Mesh-Convolutional Hand Reconstruction in the Wild
Apr 04, 2020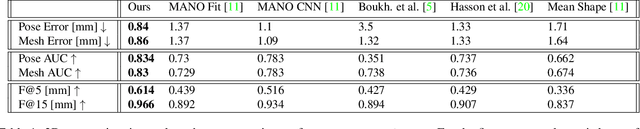

We introduce a simple and effective network architecture for monocular 3D hand pose estimation consisting of an image encoder followed by a mesh convolutional decoder that is trained through a direct 3D hand mesh reconstruction loss. We train our network by gathering a large-scale dataset of hand action in YouTube videos and use it as a source of weak supervision. Our weakly-supervised mesh convolutions-based system largely outperforms state-of-the-art methods, even halving the errors on the in the wild benchmark. The dataset and additional resources are available at https://arielai.com/mesh_hands.
Single Image 3D Hand Reconstruction with Mesh Convolutions
May 13, 2019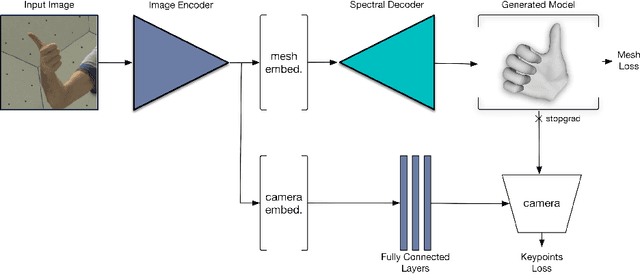

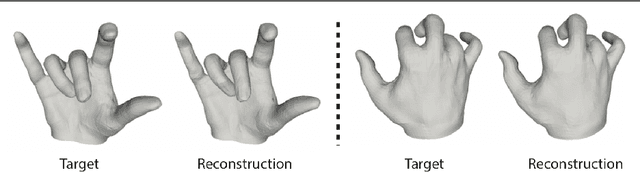
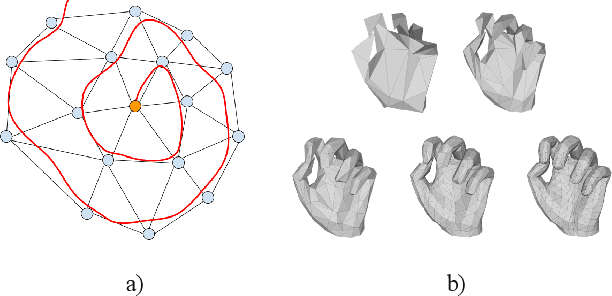
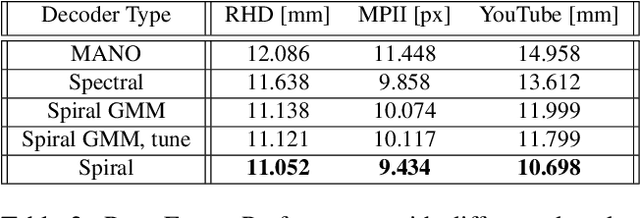
Monocular 3D reconstruction of deformable objects, such as human body parts, has been typically approached by predicting parameters of heavyweight linear models. In this paper, we demonstrate an alternative solution that is based on the idea of encoding images into a latent non-linear representation of meshes. The prior on 3D hand shapes is learned by training an autoencoder with intrinsic graph convolutions performed in the spectral domain. The pre-trained decoder acts as a non-linear statistical deformable model. The latent parameters that reconstruct the shape and articulated pose of hands in the image are predicted using an image encoder. We show that our system reconstructs plausible meshes and operates in real-time. We evaluate the quality of the mesh reconstructions produced by the decoder on a new dataset and show latent space interpolation results. Our code, data, and models will be made publicly available.