 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Author Obfuscation with Large Language Models
May 17, 2025In this paper, we investigate the efficacy of large language models (LLMs) in obfuscating authorship by paraphrasing and altering writing styles. Rather than adopting a holistic approach that evaluates performance across the entire dataset, we focus on user-wise performance to analyze how obfuscation effectiveness varies across individual authors. While LLMs are generally effective, we observe a bimodal distribution of efficacy, with performance varying significantly across users. To address this, we propose a personalized prompting method that outperforms standard prompting techniques and partially mitigates the bimodality issue.
Traits of a Leader: User Influence Level Prediction through Sociolinguistic Modeling
Jan 05, 2025Recognition of a user's influence level has attracted much attention as human interactions move online. Influential users have the ability to sway others' opinions to achieve some goals. As a result, predicting users' level of influence can help to understand social networks, forecast trends, prevent misinformation, etc. However, predicting user influence is a challenging problem because the concept of influence is specific to a situation or a domain, and user communications are limited to text. In this work, we define user influence level as a function of community endorsement and develop a model that significantly outperforms the baseline by leveraging demographic and personality data. This approach consistently improves RankDCG scores across eight different domains.
''You should probably read this'': Hedge Detection in Text
May 22, 2024Humans express ideas, beliefs, and statements through language. The manner of expression can carry information indicating the author's degree of confidence in their statement. Understanding the certainty level of a claim is crucial in areas such as medicine, finance, engineering, and many others where errors can lead to disastrous results. In this work, we apply a joint model that leverages words and part-of-speech tags to improve hedge detection in text and achieve a new top score on the CoNLL-2010 Wikipedia corpus.
Decoupling entrainment from consistency using deep neural networks
Nov 03, 2020


Human interlocutors tend to engage in adaptive behavior known as entrainment to become more similar to each other. Isolating the effect of consistency, i.e., speakers adhering to their individual styles, is a critical part of the analysis of entrainment. We propose to treat speakers' initial vocal features as confounds for the prediction of subsequent outputs. Using two existing neural approaches to deconfounding, we define new measures of entrainment that control for consistency. These successfully discriminate real interactions from fake ones. Interestingly, our stricter methods correlate with social variables in opposite direction from previous measures that do not account for consistency. These results demonstrate the advantages of using neural networks to model entrainment, and raise questions regarding how to interpret prior associations of conversation quality with entrainment measures that do not account for consistency.
Comparing approaches for mitigating intergroup variability in personality recognition
Jan 31, 2018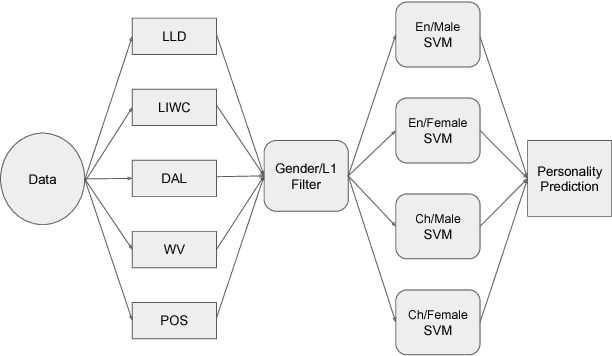

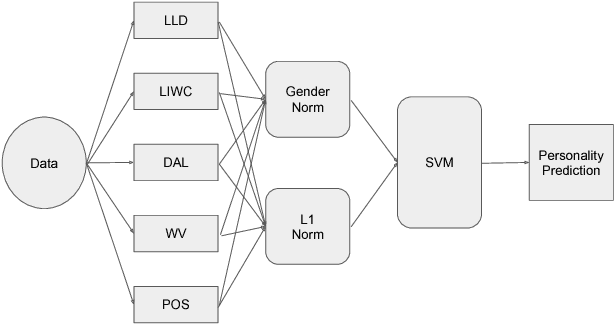

Personality have been found to predict many life outcomes, and there have been huge interests on automatic personality recognition from a speaker's utterance. Previously, we achieved accuracies between 37%-44% for three-way classification of high, medium or low for each of the Big Five personality traits (Openness to Experience, Conscientiousness, Extraversion, Agreeableness, Neuroticism). We show here that we can improve performance on this task by accounting for heterogeneity of gender and L1 in our data, which has English speech from female and male native speakers of Chinese and Standard American English (SAE). We experiment with personalizing models by L1 and gender and normalizing features by speaker, L1 group, and/or gender.