Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing approaches for mitigating intergroup variability in personality recognition
Paper and Code
Jan 31, 2018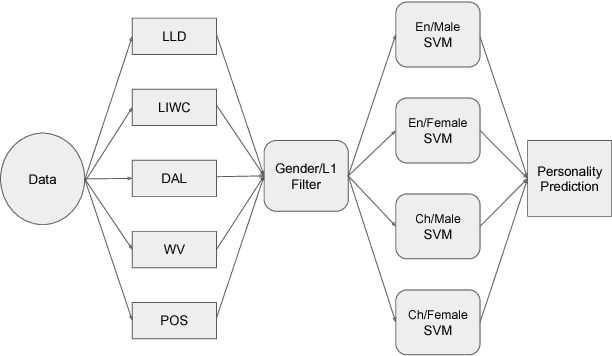

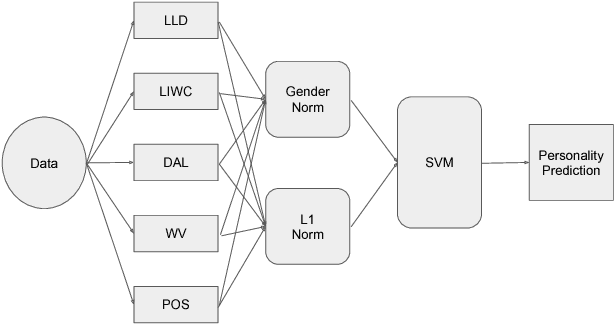

Personality have been found to predict many life outcomes, and there have been huge interests on automatic personality recognition from a speaker's utterance. Previously, we achieved accuracies between 37%-44% for three-way classification of high, medium or low for each of the Big Five personality traits (Openness to Experience, Conscientiousness, Extraversion, Agreeableness, Neuroticism). We show here that we can improve performance on this task by accounting for heterogeneity of gender and L1 in our data, which has English speech from female and male native speakers of Chinese and Standard American English (SAE). We experiment with personalizing models by L1 and gender and normalizing features by speaker, L1 group, and/or gender.
View paper on