 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Results on LPT: A Near-Linear Time Algorithm and Parcel Delivery using Drones
Jul 23, 2024

The focus of this paper is to increase our understanding of the Longest Processing Time First (LPT) heuristic. LPT is a classical heuristic for the fundamental problem of uniform machine scheduling. For different machine speeds, LPT was first considered by Gonzalez et al (SIAM J. Computing, 1977). Since then, extensive work has been done to improve the approximation factor of the LPT heuristic. However, all known implementations of the LPT heuristic take $O(mn)$ time, where $m$ is the number of machines and $n$ is the number of jobs. In this work, we come up with the first near-linear time implementation for LPT. Specifically, the running time is $O((n+m)(\log^2{m}+\log{n}))$. Somewhat surprisingly, the result is obtained by mapping the problem to dynamic maintenance of lower envelope of lines, which has been well studied in the computational geometry community. Our second contribution is to analyze the performance of LPT for the Drones Warehouse Problem (DWP), which is a natural generalization of the uniform machine scheduling problem motivated by drone-based parcel delivery from a warehouse. In this problem, a warehouse has multiple drones and wants to deliver parcels to several customers. Each drone picks a parcel from the warehouse, delivers it, and returns to the warehouse (where it can also get charged). The speeds and battery lives of the drones could be different, and due to the limited battery life, each drone has a bounded range in which it can deliver parcels. The goal is to assign parcels to the drones so that the time taken to deliver all the parcels is minimized. We prove that the natural approach of solving this problem via the LPT heuristic has an approximation factor of $\phi$, where $\phi \approx 1.62$ is the golden ratio.
Learning Sparse Fixed-Structure Gaussian Bayesian Networks
Jul 22, 2021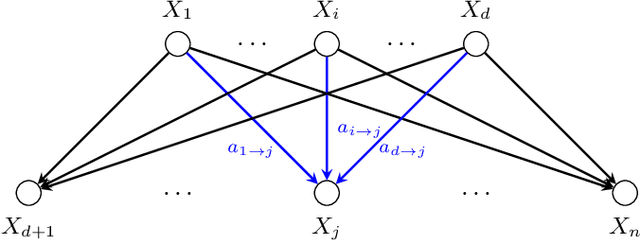
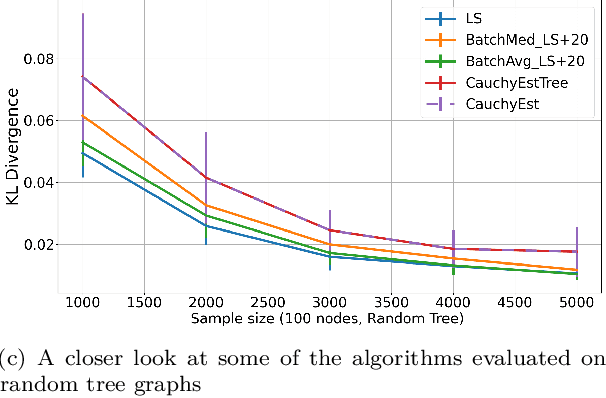

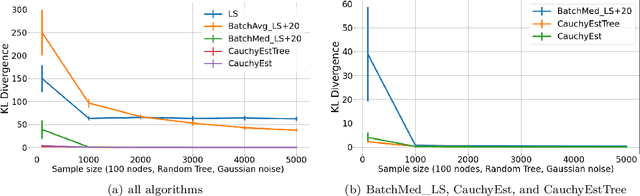
Gaussian Bayesian networks (a.k.a. linear Gaussian structural equation models) are widely used to model causal interactions among continuous variables. In this work, we study the problem of learning a fixed-structure Gaussian Bayesian network up to a bounded error in total variation distance. We analyze the commonly used node-wise least squares regression (LeastSquares) and prove that it has a near-optimal sample complexity. We also study a couple of new algorithms for the problem: - BatchAvgLeastSquares takes the average of several batches of least squares solutions at each node, so that one can interpolate between the batch size and the number of batches. We show that BatchAvgLeastSquares also has near-optimal sample complexity. - CauchyEst takes the median of solutions to several batches of linear systems at each node. We show that the algorithm specialized to polytrees, CauchyEstTree, has near-optimal sample complexity. Experimentally, we show that for uncontaminated, realizable data, the LeastSquares algorithm performs best, but in the presence of contamination or DAG misspecification, CauchyEst/CauchyEstTree and BatchAvgLeastSquares respectively perform better.