 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Consistency, Quality and Challenges in Manual and Automated Coding of Free-text Diagnoses from Hospital Outpatient Letters
Nov 17, 2023

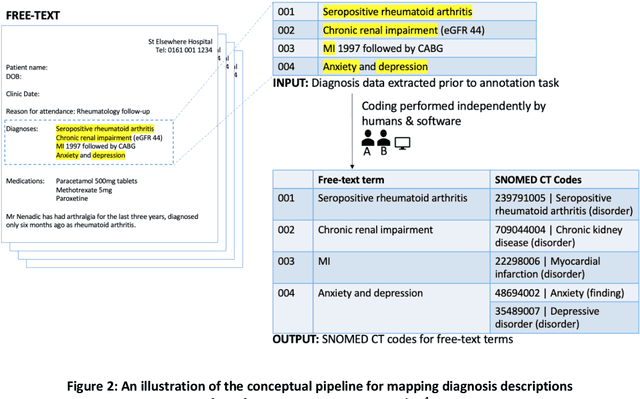
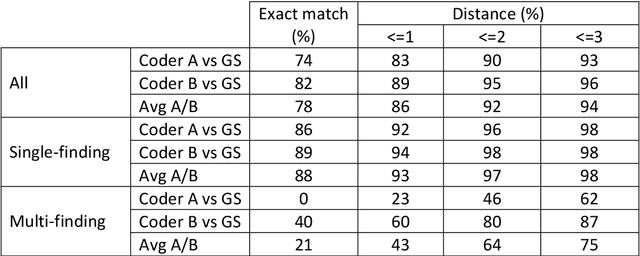
Coding of unstructured clinical free-text to produce interoperable structured data is essential to improve direct care, support clinical communication and to enable clinical research.However, manual clinical coding is difficult and time consuming, which motivates the development and use of natural language processing for automated coding. This work evaluates the quality and consistency of both manual and automated clinical coding of diagnoses from hospital outpatient letters. Using 100 randomly selected letters, two human clinicians performed coding of diagnosis lists to SNOMED CT. Automated coding was also performed using IMO's Concept Tagger. A gold standard was constructed by a panel of clinicians from a subset of the annotated diagnoses. This was used to evaluate the quality and consistency of both manual and automated coding via (1) a distance-based metric, treating SNOMED CT as a graph, and (2) a qualitative metric agreed upon by the panel of clinicians. Correlation between the two metrics was also evaluated. Comparing human and computer-generated codes to the gold standard, the results indicate that humans slightly out-performed automated coding, while both performed notably better when there was only a single diagnosis contained in the free-text description. Automated coding was considered acceptable by the panel of clinicians in approximately 90% of cases.