 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel PCA for multivariate extremes
Nov 24, 2022We propose kernel PCA as a method for analyzing the dependence structure of multivariate extremes and demonstrate that it can be a powerful tool for clustering and dimension reduction. Our work provides some theoretical insight into the preimages obtained by kernel PCA, demonstrating that under certain conditions they can effectively identify clusters in the data. We build on these new insights to characterize rigorously the performance of kernel PCA based on an extremal sample, i.e., the angular part of random vectors for which the radius exceeds a large threshold. More specifically, we focus on the asymptotic dependence of multivariate extremes characterized by the angular or spectral measure in extreme value theory and provide a careful analysis in the case where the extremes are generated from a linear factor model. We give theoretical guarantees on the performance of kernel PCA preimages of such extremes by leveraging their asymptotic distribution together with Davis-Kahan perturbation bounds. Our theoretical findings are complemented with numerical experiments illustrating the finite sample performance of our methods.
Spectral learning of multivariate extremes
Nov 15, 2021



We propose a spectral clustering algorithm for analyzing the dependence structure of multivariate extremes. More specifically, we focus on the asymptotic dependence of multivariate extremes characterized by the angular or spectral measure in extreme value theory. Our work studies the theoretical performance of spectral clustering based on a random $k$-nearest neighbor graph constructed from an extremal sample, i.e., the angular part of random vectors for which the radius exceeds a large threshold. In particular, we derive the asymptotic distribution of extremes arising from a linear factor model and prove that, under certain conditions, spectral clustering can consistently identify the clusters of extremes arising in this model. Leveraging this result we propose a simple consistent estimation strategy for learning the angular measure. Our theoretical findings are complemented with numerical experiments illustrating the finite sample performance of our methods.
Modeling of time series using random forests: theoretical developments
Aug 06, 2020
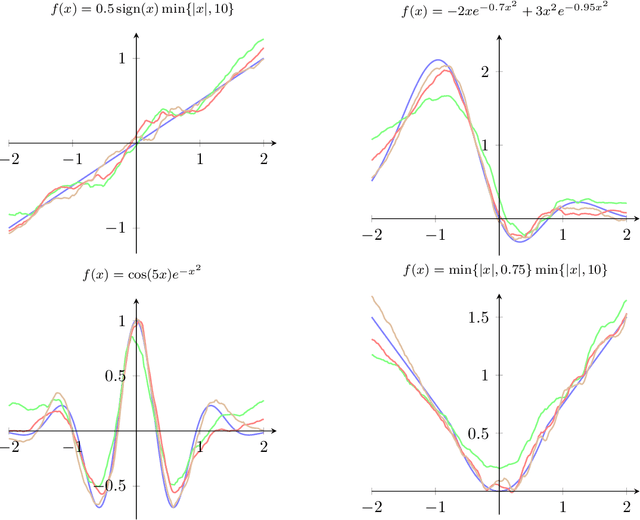


In this paper we study asymptotic properties of random forests within the framework of nonlinear time series modeling. While random forests have been successfully applied in various fields, the theoretical justification has not been considered for their use in a time series setting. Under mild conditions, we prove a uniform concentration inequality for regression trees built on nonlinear autoregressive processes and, subsequently, we use this result to prove consistency for a large class of random forests. The results are supported by various simulations.