 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADRL-based UAVs Trajectory Design with Anti-Collision Mechanism in Vehicular Networks
Jan 21, 2024In upcoming 6G networks, unmanned aerial vehicles (UAVs) are expected to play a fundamental role by acting as mobile base stations, particularly for demanding vehicle-to-everything (V2X) applications. In this scenario, one of the most challenging problems is the design of trajectories for multiple UAVs, cooperatively serving the same area. Such joint trajectory design can be performed using multi-agent deep reinforcement learning (MADRL) algorithms, but ensuring collision-free paths among UAVs becomes a critical challenge. Traditional methods involve imposing high penalties during training to discourage unsafe conditions, but these can be proven to be ineffective, whereas binary masks can be used to restrict unsafe actions, but naively applying them to all agents can lead to suboptimal solutions and inefficiencies. To address these issues, we propose a rank-based binary masking approach. Higher-ranked UAVs move optimally, while lower-ranked UAVs use this information to define improved binary masks, reducing the number of unsafe actions. This approach allows to obtain a good trade-off between exploration and exploitation, resulting in enhanced training performance, while maintaining safety constraints.
Continual Meta-Reinforcement Learning for UAV-Aided Vehicular Wireless Networks
Jul 13, 2022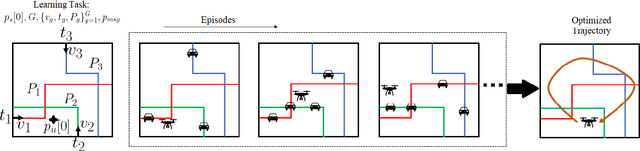
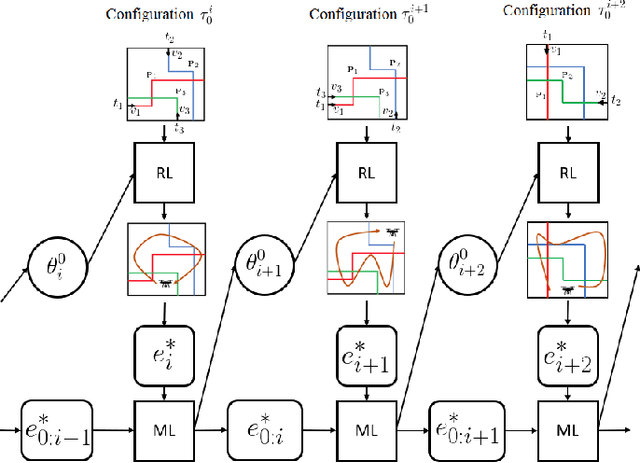
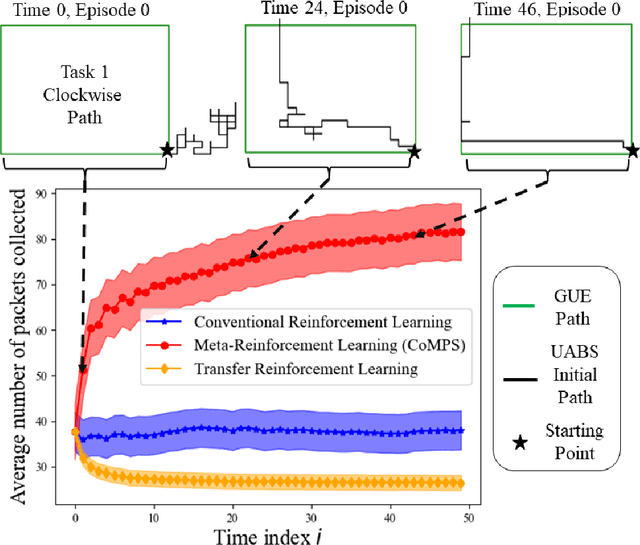
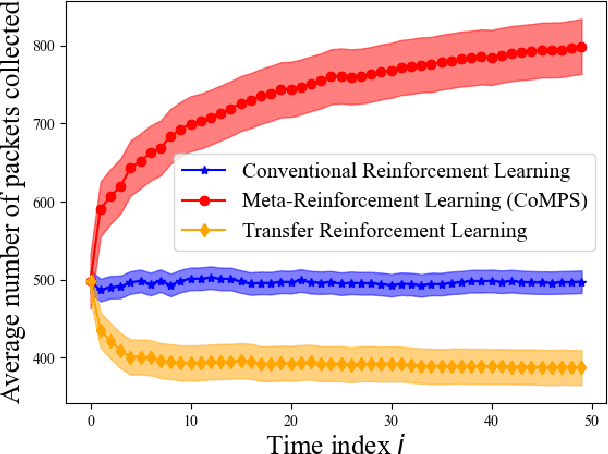
Unmanned aerial base stations (UABSs) can be deployed in vehicular wireless networks to support applications such as extended sensing via vehicle-to-everything (V2X) services. A key problem in such systems is designing algorithms that can efficiently optimize the trajectory of the UABS in order to maximize coverage. In existing solutions, such optimization is carried out from scratch for any new traffic configuration, often by means of conventional reinforcement learning (RL). In this paper, we propose the use of continual meta-RL as a means to transfer information from previously experienced traffic configurations to new conditions, with the goal of reducing the time needed to optimize the UABS's policy. Adopting the Continual Meta Policy Search (CoMPS) strategy, we demonstrate significant efficiency gains as compared to conventional RL, as well as to naive transfer learning methods.