 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Meta-Reinforcement Learning for UAV-Aided Vehicular Wireless Networks
Paper and Code
Jul 13, 2022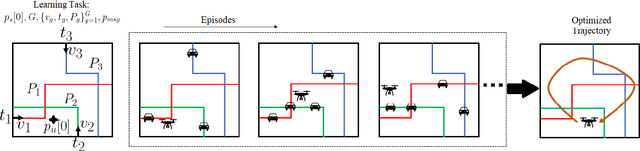
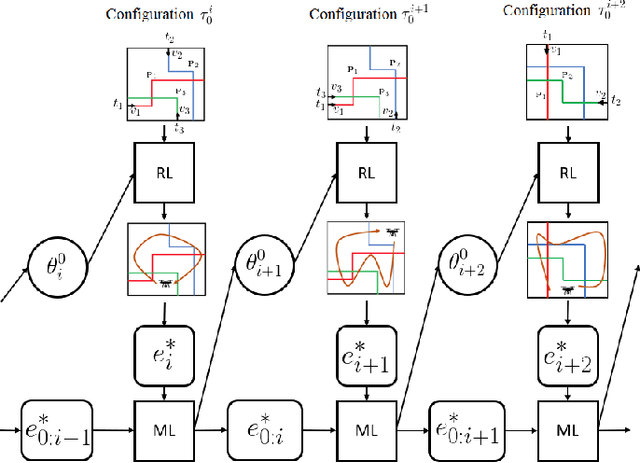
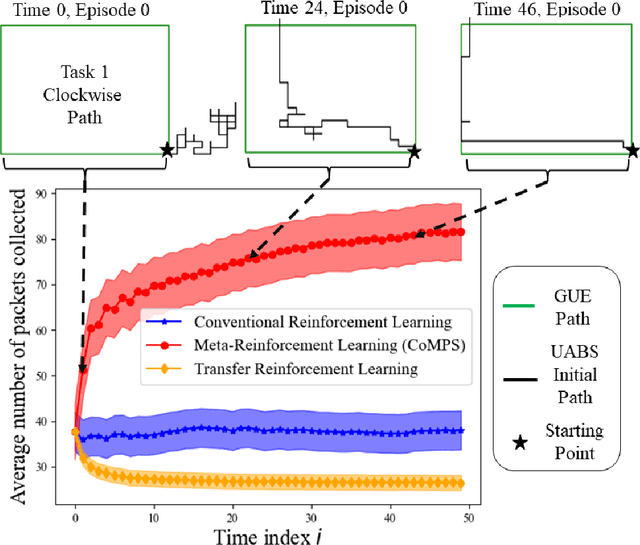
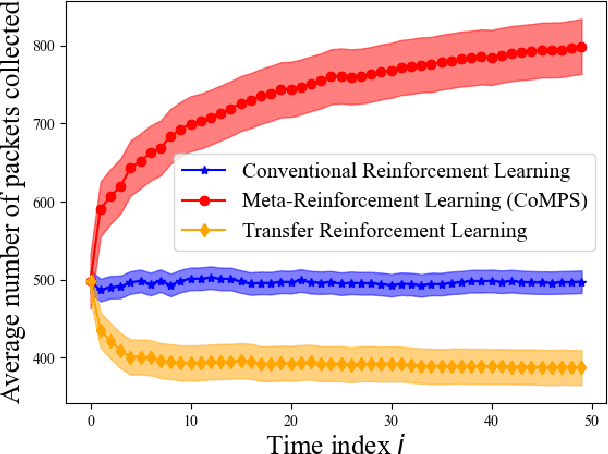
Unmanned aerial base stations (UABSs) can be deployed in vehicular wireless networks to support applications such as extended sensing via vehicle-to-everything (V2X) services. A key problem in such systems is designing algorithms that can efficiently optimize the trajectory of the UABS in order to maximize coverage. In existing solutions, such optimization is carried out from scratch for any new traffic configuration, often by means of conventional reinforcement learning (RL). In this paper, we propose the use of continual meta-RL as a means to transfer information from previously experienced traffic configurations to new conditions, with the goal of reducing the time needed to optimize the UABS's policy. Adopting the Continual Meta Policy Search (CoMPS) strategy, we demonstrate significant efficiency gains as compared to conventional RL, as well as to naive transfer learning methods.